基于无监督学习的算法交易
本文介绍一种基于K-Means的交易策略,实现了1.32的夏普比率和32%的年复合增长率。

一键发币: x402兼容 | Aptos | X Layer | SUI | SOL | BNB | ETH | BASE | ARB | OP | Polygon | Avalanche
本文介绍一种基于K-Means的交易策略,实现了1.32的夏普比率和32%的年复合增长率。
1、动机
大多数金融机器学习是监督式的:模型被训练来预测收益或分类市场环境。我采取了不同的方法,使用K-Means——一种无监督聚类方法——来揭示基本面中的结构并据此进行交易。
关键见解:市盈率(P/E)为25对科技股和公用事业股意味着完全不同的事情。聚类解决了这个问题,通过自动将具有相似特征的股票分组,我们可以评估一只股票当前的基本面情况,而无需考虑与该股票相关的结构性偏差。
传统模型对所有P/E比率一视同仁,但上下文才是关键。以英伟达为例,市盈率为45与25时:
- 市盈率45:相对于标普500指数较高,但对于成长型科技股来说正常。
- 市盈率25:对于标普500指数仍然偏高,但对于成长型股票来说则显得“令人担忧”。
一个简单的特征工程模型会将这两个市盈率视为相同:偏高。但它们忽略了英伟达增长故事的巨大转变。
你可能会认为只需计算市盈率随时间的变化,构建滞后特征向量或生成市盈率变化特征。但这忽略了整个行业范围内的变化。想象一下,新的公共事业费率上限摧毁了整个行业的增长预期。一家公共事业公司的市盈率从12上升到18,在孤立的情况下看起来很糟糕——更高的市盈率通常意味着股票变得昂贵。但如果其同行的市盈率飙升至25,那么这只股票实际上相对便宜,并且表现优于同行。基于市盈率的基本算法交易策略很可能会给这只表现出色的公共事业股票发出“卖出”信号,因为它看到市盈率增加是一个负面信号。然而,行业背景显示这实际上应该是一个“强力买入”信号——这只股票相对于同行而言处于折扣状态。解决方案:集群相对特征。
2、算法交易流程
该策略遵循一个模块化的框架,包括预处理、无监督聚类、特征工程、监督学习和投资组合构建。

3、特征工程
每季度,K-Means模型都会根据股票的基本面特征对其进行分组聚类。11个聚类始终能产生最佳的轮廓分数,尽管该策略在各种聚类数量下依然稳健。在聚类和建模之前,所有基本面特征都会经过对数变换并使用鲁棒缩放器进行缩放,以减轻财务数据中常见的重尾分布和异常值的影响。
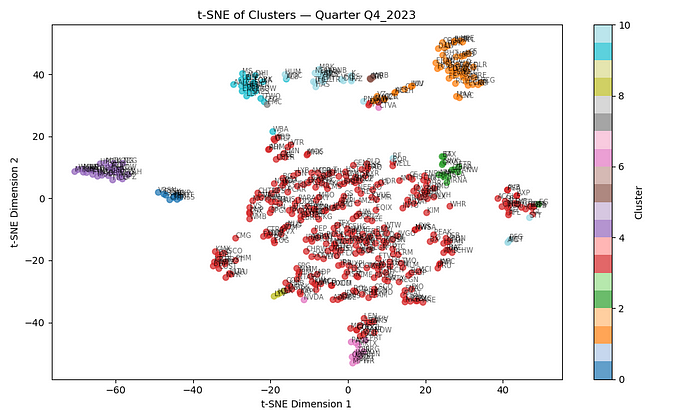
对于每个聚类中的股票,我们计算几个工程特征:
- 相对聚类位置:股票的基本面向量与其聚类均值向量之间的差异。
- 相对聚类位置的时间偏离:股票在其聚类同伴之间相对位置的变化,突出显示基本面的动量或恶化。
- 聚类相对回报:股票从季度 t 到 t + 1 的回报,按其聚类在同期平均回报的归一化值。

最后,计算目标值以训练机器学习模型。具体来说,我们根据股票在下一个季度的聚类相对回报为其分配标签。聚类相对回报位于上四分位数的股票被视为正样本,而位于下三分之一的股票被视为负样本。中间的50%被视为中性样本。
我们假设直接预测一只股票相对于整个市场的表现基于基本指标是非常困难的。然而,预测一只股票相对于其同行的表现要简单得多,并且仍然与积极的表现相关联。这种设定强调了相对表现而不是绝对回报,使模型更能适应市场环境的变化。通过锚定目标到聚类内的排名,我们鼓励模型专注于同行驱动的阿尔法信号,而不是广泛市场趋势。
4、动态聚类预测
每季度,基于上述特征工程过程生成的数据训练一个分类器。该模型学习识别在聚类相对表现之前出现的基本面和时间偏离特征模式。
我们使用随机森林分类器,因为它对噪声具有鲁棒性,能够捕捉非线性关系,并且易于解释。模型超参数未进行调优,以避免过度拟合市场数据。
重要的是,由于每个季度重新定义聚类,模型不是学习特定股票的绝对规则,而是学习关系规则——某些特性如何在同行群体内预示出表现优异。这种动态学习过程使策略能够适应市场构成的变化、行业轮动和估值制度的演变。
输出是每个股票的未来表现概率得分,表示其相对于其聚类的未来表现可能性。在每个季度,根据未来表现对股票进行排名,并购买排名最高的10只股票。对于现有持仓,任何跌入预测分数下三分之一的股票都将从投资组合中移除,确保资本持续分配给最有前途的机会。
5、回测
回测采用季度滚动方式进行,使用标普500指数股票池的基本面数据。我们在季度末和假定的盈利日期之间实施了一个保守的滞后,以确保没有数据泄露。宇宙选择使用点在时间上的标普500成员资格,以避免幸存者偏差,股票根据其实际纳入日期进入或退出回测。该策略在多个市场周期(2008–2024)进行了测试,包括金融危机、新冠崩盘以及各种利率环境,以评估其在不同市场条件下的稳定性。
6、结果
该策略在评估期间实现了1.33的夏普比率和32%的年复合增长率(CAGR)。
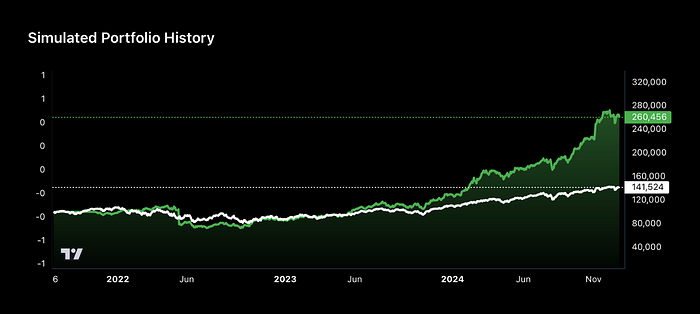
进一步测试确认了以下几点的重要性:
- 时间偏离特征,它捕获了股票在聚类中的角色演变。
- 聚类相对回报,作为比原始回报更稳定的靶标。
- 鲁棒缩放和对数变换,这些提高了模型的稳定性和泛化能力。
7、结束语
这一策略表明,无监督学习可以显著增强金融预测管道,特别是在同行相对估值的背景下。与其直接预测全球阿尔法,无监督方法使我们能够隔离聚类内的动态。这最终更加简单,并且在市场变化下更具弹性。
下一步工作将包括以下内容:
- 开发长空模型,以实现美元中性策略,从而最小化市场相关性并可能降低最大回撤。
- 尝试替代聚类算法(DBSCAN、层次聚类、高斯混合模型)
- 尝试替代分类算法(MLP、梯度提升)
这些改进可能会进一步提高性能,同时确保在各种市场条件下的稳健性。
该策略结果的React可视化可在此处找到:这里。完整代码可在GitHub上获取。
原文链接:Unsupervised ML in Algorithmic Trading
DefiPlot翻译整理,转载请标明出处
免责声明:本站资源仅用于学习目的,也不应被视为投资建议,读者在采取任何行动之前应自行研究并对自己的决定承担全部责任。


