跟单内部交易的真相
内部交易的透明度从未如此清晰。本分析深入研究了法律文件,突出了哪些内部购买实际上带来了收益,帮助交易者做出更明智的决策。

一键发币: x402兼容 | Aptos | X Layer | SUI | SOL | BNB | ETH | BASE | ARB | OP | Polygon | Avalanche
这个名字听起来有点可疑……想象一下,你是一家上市公司的高管,想要买卖自己公司的股票。由于你对公司的状况有第一手了解,你显然知道买卖的正确时机,对吧?
在美国,证券交易委员会(SEC)实施了严格的法规,以促进市场的透明度和公平性。根据1934年《证券交易法》第16条,包括董事、高管和持有公司超过10%股份的受益所有人在内的内部人士有法律义务报告他们的交易。这些报告必须在两个工作日内提交给SEC,通常通过表格4提交。目的是遏制内幕交易,并确保公众迅速获得有关内幕交易活动的信息。
在本文中,我将使用EODHD API获取标普500公司的内部交易数据,并分析收集到的数据。
简而言之:
- 我将获取过去一年的所有内部交易
- 同时包括它们的收盘价
- 准备数据进行交易回报分析
- 讨论发现
1、获取所需的数据
首先,烦人的导入
import requests
import pandas as pd
import os
import json
from tqdm import tqdm
from datetime import date, timedelta
import numpy as np
import matplotlib.pyplot as plt
api_token = os.environ.get('EODHD_API_TOKEN')
使用EODHD API获取标普500成分股,我将检索该指数的所有股票。此外,我还将丰富数据框,加入公司的规模,以便在分析过程中利用此信息。
INDEX_NAME = 'GSPC.INDX'
url = f'https://eodhd.com/api/mp/unicornbay/spglobal/comp/{INDEX_NAME}'
query = {'api_token': api_token, "fmt": "json"}
data = requests.get(url, params=query)
if data.status_code != 200:
print(f"Error: {data.status_code}")
print(data.text)
data = data.json()
df_sp500 = pd.DataFrame(data['Components']).T.reset_index()
df_sp500 = df_sp500.sort_values('Weight', ascending=False)
df_sp500['CumWeight'] = df_sp500['Weight'].cumsum() / df_sp500['Weight'].sum()
df_sp500['CompanySize'] = pd.cut(df_sp500['CumWeight'], bins=[0.0, 0.40, 0.6, 0.8, 0.95, 1.0], labels=['Ultra', 'Mega', 'Large', 'Mid', 'Small'],
include_lowest=True)
现在我们将遍历标普500公司的所有公司,收集过去一年的所有内部交易。此外,我还会将公司规模添加到数据框中,这是之前计算的。
insider_url = 'https://eodhd.com/api/insider-transactions'
insider_rows = []
tickers = df_sp500['Code'].tolist()
for ticker in tqdm(tickers, total=len(tickers), desc="Fetching insiders", dynamic_ncols=True, leave=True):
ticker = f"{ticker}.US"
resp = requests.get(insider_url, params={'api_token': api_token, 'fmt': 'json', 'code': ticker}, timeout=30)
items = resp.json() or []
insider_rows = insider_rows + items
df_insiders = pd.DataFrame(insider_rows)
if 'CompanySize' not in df_insiders.columns:
df_insiders = df_insiders.merge(
df_sp500[['Code', 'CompanySize']].rename(columns={'Code': 'code'}),
on='code',
how='left'
)
df_insiders
我已经收集了超过10,000笔内部交易。为了确定交易的实际结果,我需要获取每只股票的每日价格并将其存储在一个字典中,以便以后用于计算。
df_ie = df_insiders[['code', 'exchange']].dropna()
symbols = (df_ie['code'].astype(str).str.strip() + '.' + df_ie['exchange'].astype(str).str.strip()).unique().tolist()
len(symbols)
base_url = 'https://eodhd.com/api/eod/'
from_date = (date.today() - timedelta(days=5 * 365)).isoformat()
prices_by_symbol: dict[str, pd.DataFrame] = {}
for sym in tqdm(symbols, desc="Fetching 5y daily prices", dynamic_ncols=True):
r = requests.get(
f"{base_url}{sym}",
params={'api_token': api_token, 'fmt': 'json', 'from': from_date},
timeout=30
)
data = r.json() or []
df = pd.DataFrame(data)
# Normalize and sort
if 'date' in df.columns:
df['date'] = pd.to_datetime(df['date'])
df = df.sort_values('date').reset_index(drop=True)
prices_by_symbol[sym] = df
此外,我将创建一个函数来获取特定股票在特定日期的价格。
def get_price_at(symbol: str, ref_date, delta: timedelta):
if symbol not in prices_by_symbol:
return None
df = prices_by_symbol.get(symbol)
# ensure datetime dtype
df = df.copy()
df['date'] = pd.to_datetime(df['date'])
ref_dt = pd.to_datetime(ref_date)
target_dt = ref_dt + delta
# exact match first
row = df.loc[df['date'] == target_dt]
if not row.empty:
return row.iloc[0].get('close', None)
# otherwise, get the latest available date <= target_dt
hist = df.loc[df['date'] <= target_dt]
if hist.empty:
return None
return hist.iloc[-1].get('close', None)
现在是时候计算交易的结果了。我将确定交易后3天、7天和一个月的回报率。
df_insiders['price_on_report_date'] = np.nan
df_insiders['3D_price'] = np.nan
df_insiders['7D_price'] = np.nan
df_insiders['1M_price'] = np.nan
for idx, row in df_insiders.iterrows():
df_insiders.at[idx, 'price_on_report_date'] = get_price_at(f"{row.get('code')}.US", row.get('reportDate'), timedelta(days=0))
df_insiders.at[idx, '3D_price'] = get_price_at(f"{row.get('code')}.US", row.get('date'), timedelta(days=3))
df_insiders.at[idx, '7D_price'] = get_price_at(f"{row.get('code')}.US", row.get('date'), timedelta(days=7))
df_insiders.at[idx, '1M_price'] = get_price_at(f"{row.get('code')}.US", row.get('date'), timedelta(days=30))
df_insiders['3D_Return'] = ((df_insiders['3D_price'] - df_insiders['transactionPrice']) / df_insiders['transactionPrice'])*100
df_insiders.loc[df_insiders['transactionCode'].astype(str).str.upper().str.strip() == 'S', '3D_Return'] *= -1
df_insiders['7D_Return'] = ((df_insiders['7D_price'] - df_insiders['transactionPrice']) / df_insiders['transactionPrice'])*100
df_insiders.loc[df_insiders['transactionCode'].astype(str).str.upper().str.strip() == 'S', '7D_Return'] *= -1
df_insiders['1M_Return'] = ((df_insiders['1M_price'] - df_insiders['transactionPrice']) / df_insiders['transactionPrice'])*100
df_insiders.loc[df_insiders['transactionCode'].astype(str).str.upper().str.strip() == 'S', '1M_Return'] *= -1
df_insiders['1M_Return_from_reporting_date'] = ((df_insiders['1M_price'] - df_insiders['price_on_report_date']) / df_insiders['price_on_report_date'])*100
df_insiders.loc[df_insiders['transactionCode'].astype(str).str.upper().str.strip() == 'S', '1M_Return_from_reporting_date'] *= -1
df_insiders
2、数据清洗和聚合
数据分析中最重要的一环是数据清洗和聚合。这是当我们审视我们的数据集并根据我们个人的偏好和目标进行必要的调整的时候。
所有者标题
我们收到的一个有趣的信息是所有者标题。对于每个内部人士,通过检查我们数据集中的数据,我将所有的首席职位归类为C级,组织高级管理人员职位等,形成一个名为ownerTitleAgg的新列。
df_insiders['ownerTitleAgg'] = df_insiders['ownerTitle']
df_insiders.loc[
df_insiders['ownerTitleAgg'].str.startswith('U.S. Congress Member', na=False), 'ownerTitleAgg'] = 'U.S. Congress Member'
df_insiders.loc[
df_insiders['ownerTitleAgg'].isin(['CEO', 'CAO', 'CFO', 'COO', 'CIO', 'CRO', 'CMO', 'CTO']), 'ownerTitleAgg'] = 'C-Level'
df_insiders.loc[
df_insiders['ownerTitleAgg'].isin(['SVP', 'EVP', 'VP', 'Treasurer', 'Director', 'General Counsel']), 'ownerTitleAgg'] = 'Senior Management'
df_insiders.loc[
df_insiders['ownerTitleAgg'].isin(['Vice Chairman', 'Chairman', 'President']), 'ownerTitleAgg'] = 'Board'
df_insiders.loc[
df_insiders['ownerTitleAgg'].isin(['Insider', 'insider']), 'ownerTitleAgg'] = 'Insider'
美国国会成员
我注意到一些来自美国国会成员的异常交易数据。经过调查,似乎他们的做法独特且不一致,包括手写的填写和其他上世纪的过时程序。这就是为什么我将使用以下代码从数据集中排除他们。
if 'ownerTitleAgg' in df_insiders.columns:
df_insiders = df_insiders[df_insiders['ownerTitleAgg'] != 'U.S. Congress Member']
不现实的回报
一些数据点看起来不现实,显示回报率高达数千。由于这些情况很少见,我不会调查其原因。我随机检查了其余的数据,看起来是合法的。让我们删除单月利润或损失超过50%的条目。
if '1M_Return' in df_insiders.columns:
df_insiders['1M_Return'] = pd.to_numeric(df_insiders['1M_Return'], errors='coerce')
df_insiders = df_insiders[df_insiders['1M_Return'].abs() <= 50]
3、分析数据
首先,让我们考虑整体情况。所有交易的平均回报是多少,或者按购买或销售分组?
def stats(series: pd.Series):
s = pd.to_numeric(series, errors='coerce').dropna()
wins = int((s > 0).sum())
losses = int((s <= 0).sum())
avg = s.mean()
return wins, losses, avg
df_insiders_copy = df_insiders.copy()
summary = []
for period, col in [('3D', '3D_Return'), ('7D', '7D_Return'), ('1M', '1M_Return')]:
# Overall
wins, losses, avg = stats(df_insiders_copy[col])
summary.append(
{'Period': period, 'transactionCode': 'All', 'Wins': wins, 'Losses': losses, 'AverageReturn(%)': avg})
# Purchases (P)
mask_p = df_insiders_copy['transactionCode'].astype(str).str.upper().str.strip() == 'P'
wins_p, losses_p, avg_p = stats(df_insiders_copy.loc[mask_p, col])
summary.append(
{'Period': period, 'transactionCode': 'P', 'Wins': wins_p, 'Losses': losses_p, 'AverageReturn(%)': avg_p})
# Sales (S)
mask_s = df_insiders_copy['transactionCode'].astype(str).str.upper().str.strip() == 'S'
wins_s, losses_s, avg_s = stats(df_insiders_copy.loc[mask_s, col])
summary.append(
{'Period': period, 'transactionCode': 'S', 'Wins': wins_s, 'Losses': losses_s, 'AverageReturn(%)': avg_s})
df_summary = pd.DataFrame(summary)
df_summary
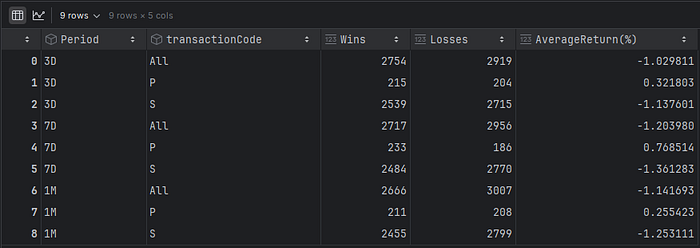
虽然回报相当平衡(列“AverageReturn (%)”),但我们可以清楚地看到,只有购买(交易代码 = P)略具盈利性。这是因为出售可能出于与公司表现无关的原因(税收、个人流动性等)。
现在让我们根据每个内部人士的头衔来检查回报。从这一点开始,我将只专注于购买。
df_insiders_copy = df_insiders.copy()
df_insiders_copy = df_insiders_copy[df_insiders_copy['transactionCode'].astype(str).str.upper().str.strip() == 'P']
# Compute average returns per code
df_avg_by_ownerTitle = (
df_insiders_copy
.copy()
.assign(
Return_3D=pd.to_numeric(df_insiders_copy['3D_Return'], errors='coerce'),
Return_7D=pd.to_numeric(df_insiders_copy['7D_Return'], errors='coerce'),
Return_1M=pd.to_numeric(df_insiders_copy['1M_Return'], errors='coerce')
)
.groupby('ownerTitleAgg', as_index=False)
.agg(
Trades=('ownerTitle', 'count'),
Avg_3D_Return=('Return_3D', 'mean'),
Avg_7D_Return=('Return_7D', 'mean'),
Avg_1M_Return=('Return_1M', 'mean')
)
.sort_values('Avg_1M_Return', ascending=False)
)
df_avg_by_ownerTitle
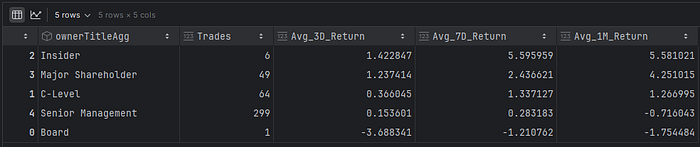
内部人士和大股东似乎是最有利可图的。嗯,那些人拥有更多的“资金投入”!当我搜索哪种类型的内部人士最受市场密切关注时,答案很明确。股东!而数据证明了这一点。
让我们看看更多组别。为了避免在文章中填满大量的Python代码,我将展示结果。您可以在我的GitHub仓库中找到完整的代码。
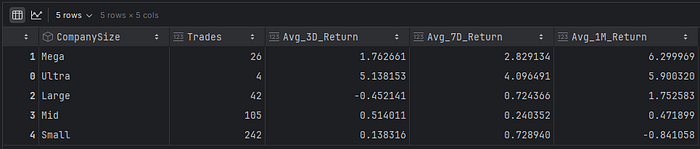
当基于公司规模进行分组时,首先是大型公司。“超大型”公司(如AAPL、NVDA、MSFT等)只有4次购买。但为什么没有内部人士购买这些股票?显然这不是原因。我看到的更重要的原因是,这些公司的内部人士已经持有大量股权,他们也不觉得有必要购买股票来表明对公司信心...
现在让我们按股票来看。我将排除那些只有1或2次购买的股票。
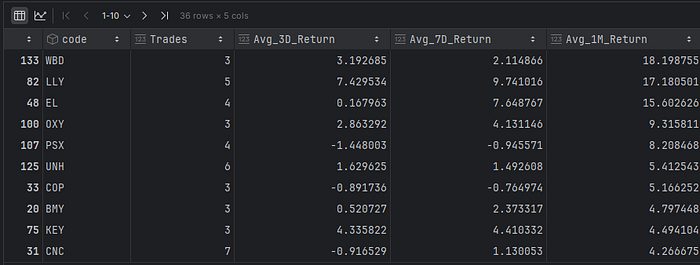
在顶部,我们会看到华纳兄弟(WBD——媒体和娱乐)、礼来公司(LLY——制药业)和雅诗兰黛(EL——化妆品等)。我认为这些公司共有的特点是,它们的股价受重大企业事件的影响很大,例如新产品发布或媒体报道,无论好坏。
让我们详细查看交易。在下面的图表中,我将用红色显示销售,用绿色显示购买。
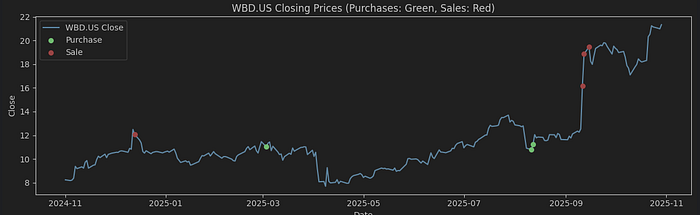
对于华纳兄弟来说,有趣的是,在8月25日左右有一些购买行为,大约在股票价格显著上涨的一个月前。值得注意的是,在原始数据中,购买股票的人与卖出股票的人不同,所以不要以为有人通过内幕交易赚了钱;)。
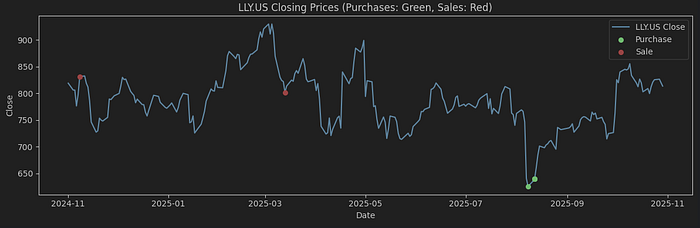
对于礼来公司,我们再次观察到在8月25日左右的52周低点附近进行了购买。我可以假设在此时,高管们旨在展示他们对公司信心。他们没有错...几个月内,股价上涨了约25%。
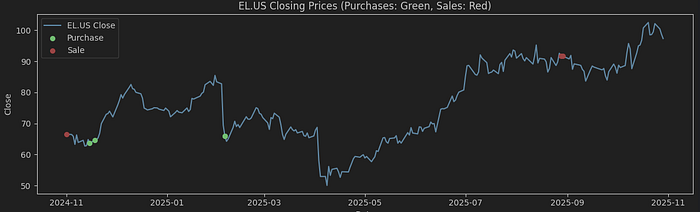
对于雅诗兰黛公司,我们可以在2024年底和2025年初看到一些购买行为。这些交易不像礼来公司在某个底部低点那样…但所有交易都成功了,尽管后来经历了特朗普贸易战期间的回撤…但股票弥补了这些损失,目前的回报约为40%。
4、结束语
数据显示的一些事实:
- 销售不一定意味着内部人士对公司失去信心;通常,这可能是由于各种其他原因。
- 购买主要是为了增加信心。
- 股东和其他内部人士比执行团队更成功,应该更加密切监控。
内部交易不是都市传说,但另一方面,你不应该盲目追随它们。此外,仅凭这些信息无法做出自动化的决定。然而,监控它们似乎是一种每个交易者都应该纳入工具箱的信息。
原文链接:The Truth About Following Insider Trades: Analysis of thousands of transactions
DefiPlot翻译整理,转载请标明出处
免责声明:本站资源仅用于学习目的,也不应被视为投资建议,读者在采取任何行动之前应自行研究并对自己的决定承担全部责任。


