Polymarket数据索引的悲剧
作为Polymarket的关键组成部分的数据索引,是否真的代表了一个“去中心化预测市场”?为什么像The Graph这样的公共基础设施未能履行其初衷?

一键发币: x402兼容 | Aptos | X Layer | SUI | SOL | BNB | ETH | BASE | ARB | OP | Polygon | Avalanche
欢迎来到GCC研究专栏的“加密公共物品的悲剧”系列。
在这个系列中,我们将关注加密世界中日益无法满足规范的关键公共产品。这些是整个生态系统的基本基础设施,但它们常常面临激励不足、治理不平衡甚至集中化的挑战。加密技术的理想与冗余和稳定性的现实在这片领域受到了严峻考验。
本期聚焦以太坊生态系统中最具影响力的其中一个应用:Polymarket及其数据索引工具。今年,Polymarket多次成为公众关注的焦点,特别是围绕特朗普选举胜利、乌克兰稀土贸易中的预言机操控以及泽连斯基西装颜色的政治投注事件。它所承载的资金规模和市场影响力使得这些争议尤为棘手。
然而,作为该产品的关键组成部分的数据索引,是否真的代表了一个“去中心化预测市场”?为什么像The Graph这样的公共基础设施未能履行其初衷?真正可用且可持续的数据索引公共产品应该采取什么形式?
1、中心化数据平台停机引发的连锁反应
2024年7月,Goldsky经历了六小时的停机(Goldsky是一个为Web3开发者提供实时区块链数据基础设施的平台,提供索引、子图和流数据服务,帮助快速构建数据驱动的去中心化应用程序),这使以太坊生态系统的大部分部分瘫痪。例如,DeFi前端无法显示用户的头寸和余额数据,预测市场Polymarket也无法显示正确数据。无数项目似乎对前端用户完全不可用。
在去中心化应用的世界中,这种情况不应该发生。毕竟,区块链技术的设计初衷是为了消除单点故障。Goldsky事件揭示了一个令人不安的真相:尽管区块链本身尽可能地去中心化,但建立在其上的应用程序使用的基础设施往往包括大量中心化服务。
原因在于区块链数据索引和检索是非排他性、非竞争性的数字公共产品。用户通常期望它们是免费或极低成本的,但这些服务需要持续而密集的硬件、存储、带宽和运营人员投资。在缺乏可持续盈利模式的情况下,一个赢家通吃的中心化结构就会出现:一旦某个服务提供商在速度和资本上获得先发优势,开发者往往会将所有查询流量导向该服务,从而重新创建一个单一依赖点。Gitcoin等公共福利项目一再强调,“开源基础设施可以创造数十亿美元的价值,但作者往往无法依靠它来支付房贷。”
这提醒我们,去中心化世界迫切需要通过公共产品资金、再分配或社区驱动的举措来多样化Web3基础设施。否则,集中化将是不可避免的。我们敦促DApp开发者构建本地优先的产品,技术社区在设计DApps时应考虑数据检索服务的失败,确保即使没有数据检索基础设施,用户也能与项目互动。
2、Dapp中你看到的数据来自哪里?
为了理解像Goldsky这样的事件为何会发生,我们需要深入了解DApp背后的运作机制。对于普通用户来说,DApp通常只由两部分组成:链上合约和前端。大多数用户习惯于使用Etherscan来跟踪链上交易状态,获取前端所需的必要信息,并发起交易并与合约进行交互。但是,用户前端显示的这些数据实际上来自哪里?
2.1 不可或缺的数据检索服务
假设你正在构建一个借贷协议,需要显示用户持有的资产,以及每个头寸的保证金和债务状态。一个朴素的想法是让前端直接从链上读取这些数据。但实际上,借贷协议合约不允许用户地址查询头寸数据。合约提供了一个函数,可以通过头寸ID查询特定数据。因此,如果我们想在前端显示用户头寸状态,我们需要检索当前系统中的所有头寸,然后找出哪些头寸属于当前用户。这就像让人手动搜索数百万页的账本以查找特定信息——技术上可行,但极其缓慢和低效。实际上,前端很难完成这个检索过程。即使大型DeFi项目的检索任务由本地节点在服务器上执行,也常常需要数小时。
因此,我们必须引入加速数据获取的基础设施。像Goldsky这样的公司就提供了这些数据索引服务。下图展示了数据索引服务可以为应用程序提供的类型。

此时,一些读者可能会好奇以太坊生态系统中是否存在一个名为TheGraph的去中心化数据检索平台。这个平台与Goldsky之间有什么关系?为什么大量DeFi项目选择Goldsky作为数据提供商而不是更去中心化的TheGraph?
2.2 TheGraph/Goldsky与SubGraph的关系
要回答上述问题,我们需要首先了解一些技术概念。
- SubGraph是一个开发框架,开发者可以使用它编写代码来读取和总结链上数据,并使用某些方法将这些数据展示给前端。
- TheGraph是一个早期的去中心化数据检索平台,开发了用AssemblyScript编写的SubGraph框架。开发者可以使用subgraph框架编写程序来捕获合约事件并将这些合约事件写入数据库。用户随后可以使用Graphql方法读取这些数据,或者直接使用SQL代码读取数据库。
- 我们通常将运行SubGraph的服务提供商称为SubGraph运营商。TheGraph和Goldsky都是SubGraph主机。因为SubGraph是一个开发框架,使用它的应用程序必须运行在服务器上。我们在Goldsky文档中可以看到以下内容:
一些读者可能好奇为什么SubGraph中有多个运营商?
这是因为SubGraph框架实际上只规定了如何从数据库中读取和写入数据。
并没有实现如何将数据流入SubGraph程序以及最终输出结果写入哪种数据库。这些内容需要由SubGraph运营商自己实现。
一般来说,SubGraph运营商会进行节点修改以实现更快的速度。不同的运营商(如TheGraph、Goldsky)有不同的策略和技术解决方案。
TheGraph目前使用Firehouse技术方案。在引入这一技术方案后,TheGraph可以比以前更快地进行数据检索。然而,Goldsky尚未公开其SubGraph的核心程序。
如上所述,TheGraph是一个去中心化的数据检索平台。以Uniswap v3的subgraph为例,我们可以看到有大量运营商为Uniswap v3提供数据检索服务。因此,我们也可以将TheGraph视为SubGraph运营商的集成平台。用户可以将自己的SubGraph代码发送到TheGraph,然后TheGraph内部的一些运营商可以帮助用户检索数据。
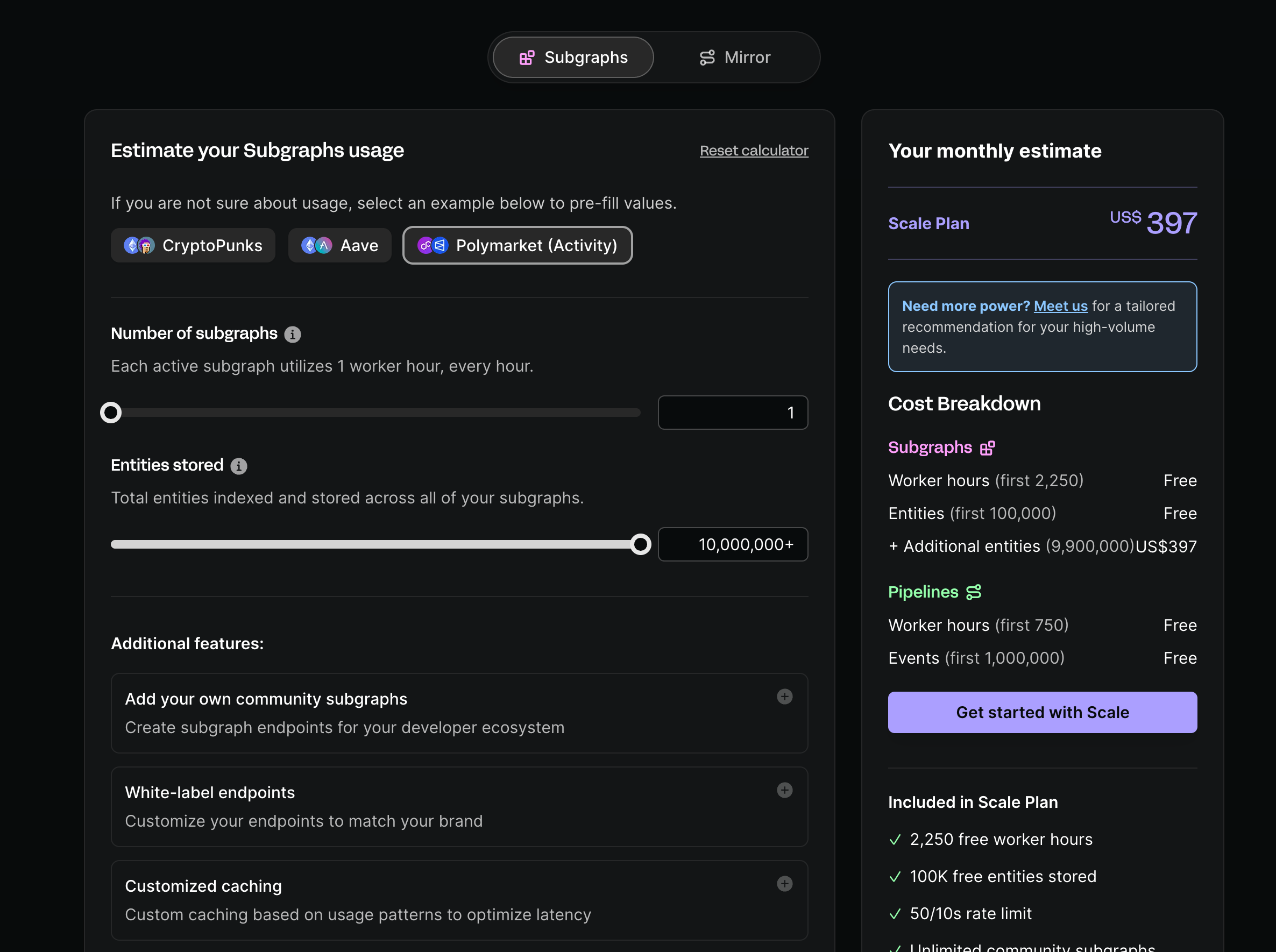
2.3 Goldsky的定价模型
对于像Goldsky这样的中心化平台,Goldsky有一个基于资源使用的简单计费系统。这是互联网上最常见的SaaS计费方式,大多数技术人员都很熟悉。下图显示了Goldsky的价格计算器:
2.4 TheGraph的定价模型
TheGraph的费用结构与传统计费完全不同。这种费用结构与GRT的代币经济有关。下图显示了GRT的整体代币经济:
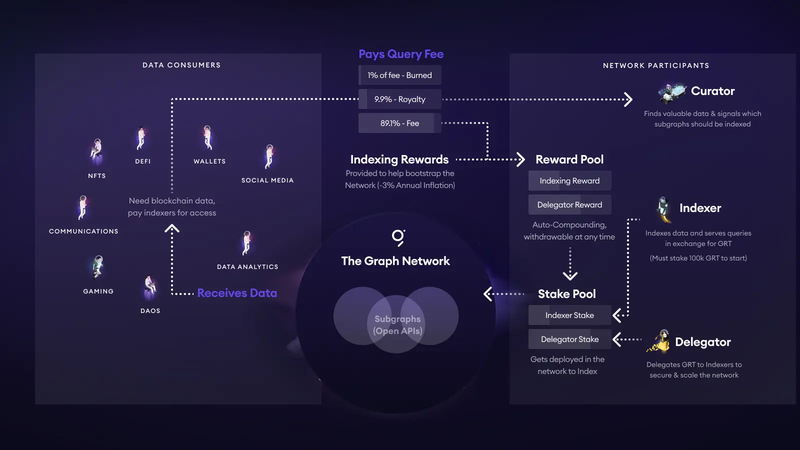
- 每当DApp或钱包向Subgraph发出请求时,支付的查询费用将自动分割:1%被销毁,约10%进入Subgraph的curator/开发者池,其余约89%根据指数返还机制支付给提供计算能力的Indexer及其Delegator。
- Indexer必须在上线前质押≥100k GRT;返回错误数据会导致惩罚。Delegators将GRT委托给Indexer,并按比例获得上述89%的收益。
- Curators(通常是开发者)使用Signal在自己的Subgraph的绑定曲线上质押GRT。更高的Signal数量会吸引更多Indexer分配资源。社区经验表明,质押5,000–10,000 GRT可以确保几个Indexer的订单。Curators也会获得10%的版税。
TheGraph的每查询费用:
在TheGraph后台注册API KEY,并使用API KEY请求TheGraph中运营商检索的数据。这些请求根据请求数量收费。开发者需要在平台上预先存入一部分GRT代币作为API请求的成本。
TheGraph的Signal质押费用:
对于SubGraph部署者来说,他们需要TheGraph平台内的运营商的帮助来检索数据。根据上述利润分配方法,他们需要告诉其他参与者,他们的查询服务更好并能获得更多钱。他们需要质押GRT,这类似于广告和保证自己会有利润,这样人们才会来。
在测试期间,开发者可以免费将SubGraph部署到TheGraph平台。TheGraph将协助用户进行一些搜索,提供用于测试的免费配额。这个配额不适合生产使用。如果开发者认为SubGraph在TheGraph官方测试环境中表现良好,他们可以将其发布到公共网络,并等待其他运营商参与搜索。开发者不能直接支付单个运营商以获得保证的搜索访问;相反,多个运营商竞争提供服务,避免单一依赖点。这个过程需要使用GRT代币在他们的SubGraph上进行curating(也称为信号)。这涉及开发者将一定数量的GRT存入他们部署的SubGraph中。只有当质押的GRT达到一定水平时(之前咨询的数据是10,000 GRT),运营商才会参与SubGraph的搜索过程。
2.5 糟糕的计费体验阻碍开发者和传统会计师
对于大多数项目开发者来说,使用TheGraph是一个相对繁琐的过程。虽然购买GRT代币对Web3项目来说相对容易,但部署SubGraph并等待运营商的过程相当低效。这个过程至少存在两个问题:
- 要质押的GRT金额和吸引运营商所需的时间的不确定性。当我过去部署SubGraph时,我直接咨询了TheGraph社区大使来确定要质押的GRT金额。然而,对于大多数开发者来说,这些数据不容易获得。此外,在质押足够的GRT之后,需要一些时间才能让运营商介入并进行搜索。
- 成本计算和会计复杂性。由于TheGraph使用代币经济设计其费用结构,成本计算对大多数开发者来说变得复杂。更实际地说,如果一家企业要对此费用进行核算,会计师可能无法理解成本结构。
“是继续繁琐的去中心化好还是选择方便的中心化方案?”
显然,对于大多数开发者来说,直接选择Goldsky更为简单。计费方式对每个人来说都很容易理解,只要支付费用,几乎可以立即使用,不确定性大大减少。这也导致了区块链数据索引和检索服务中依赖单一产品的现象。
显然,TheGraph复杂的GRT代币经济已经阻碍了广泛采用。虽然代币经济可以很复杂,但这些复杂性不应该暴露给用户。例如,GRT的curating和质押机制不应该暴露给用户。更好的做法是为用户提供一个简化的支付页面。
上述对TheGraph的贬低并不是我的个人意见。知名智能合约工程师和Sablier项目创始人Paul Razvan Berg也在一条推文中表达了这一观点。这条推文提到启动SubGraph和GRT计费的用户体验非常糟糕。
3、一些现有的解决方案
关于如何解决数据检索中的单点故障问题,我们上面已经提到了。也就是说,开发者可以考虑使用TheGraph服务,但过程会更复杂。开发者需要购买GRT代币用于质押curating和支付API费用。
目前,EVM生态系统中有许多数据检索软件。详情可参考Dune撰写的《EVM索引状态》或rindexer撰写的EVM数据检索软件摘要。另一次最近的讨论,请参见这条推文。
本文不会讨论Glodsky问题的具体原因。Glodsky目前知道原因,但只向企业用户披露。这意味着目前没有任何第三方可以确定Glodsky故障的确切性质。根据报告,可以推测可能是写入数据库时出现了问题。在这篇简短的报告中,Glodsky提到数据库不可访问,经过与AWS合作后才恢复访问。
在本节中,我们主要介绍其他解决方案:
- Poder是一个简单的数据检索服务软件,具有良好的开发体验和易于部署。开发者可以租用服务器并自行部署。
- 本地优先是一种有趣的开发理念,鼓励开发者即使在网络不可用时也能提供良好的用户体验。在有区块链的情况下,我们可以适度放松本地优先的限制,确保用户在能够连接区块链时获得良好的体验。
3.1 ponder
为什么我推荐使用ponder而不是其他软件?具体原因如下:
- Ponder没有供应商依赖。最初,Ponder是一个由个人开发者构建的项目,因此与由其他公司提供的其他数据检索软件相比,Ponder只需要用户填写以太坊RPC URL和Postgres数据库链接。
- Ponder提供了良好的开发体验。我过去多次使用Ponder进行开发。由于Ponder是用TypeScript编写的,核心库主要依赖Viem,开发体验非常好。
- Ponder性能更高
当然,也有一些问题。Ponder仍在快速开发中,开发者可能会遇到因重大更新而导致先前项目无法运行的情况。由于本文不是技术介绍,我们不会深入探讨Ponder的开发细节。有兴趣的技术背景读者可以查阅文档。
关于Ponder的一个更有趣的特点是,它已经开始部分商业化,但Ponder的商业化路径非常符合前一篇文章中讨论的“隔离理论”。
在这里,我们简要介绍“隔离理论”。我们认为,公共物品的公共性质使其能够服务于无限数量的用户。因此,对公共物品收费会导致一些用户停止使用它们,社会利益不会最大化(这在经济学术语中被称为“不再帕累托最优”)。理论上,可以对每个用户对公共物品进行不同的定价,但差别定价的成本可能超过其收益。因此,公共物品之所以免费,并不是因为它们本质上是免费的,而是因为任何固定费用都会损害社会利益,而目前还没有廉价的方法来实现每个用户的差异化定价。隔离理论提出了一种在公共物品内进行定价的方法:通过隔离一个同质群体并对他们收取费用。虽然隔离理论并不阻止所有人免费享受公共物品,但它建议对其中的一部分人收取费用。
Ponder采用了类似隔离理论的方法:
- 首先,Ponder的部署仍然需要一定的知识。开发者在部署过程中需要提供外部依赖项,如RPC和数据库。
- 部署后,开发者需要持续操作和维护Ponder应用程序,例如使用代理系统进行负载均衡,以防止数据请求影响Ponder的链上数据检索后台线程。这对普通开发者来说有点复杂。
- 目前,Ponder正在进行完全自动化部署服务marble的内部测试。用户只需将代码交付给平台即可实现自动部署。
这显然是“隔离理论”原则的应用:不愿意自行操作和维护Ponder服务的开发者被隔离,这些开发者可以付费获得简化的Ponder部署服务。当然,Marble平台的出现并没有阻止其他开发者免费使用Ponder框架并自行托管部署。
ponder和Goldsky的目标受众?
- 完全无供应商依赖的公共物品ponder,在开发小型项目方面比其他依赖供应商的数据检索服务更受欢迎。
- 一些运营大型项目的开发者不一定选择ponder框架,因为大型项目通常需要检索服务具备足够的性能,而Goldsky等服务提供商通常提供足够的可用性保证。
两者都有风险。正如最近的Goldsky事件所示,建议开发者维护自己的ponder服务以减轻潜在的第三方服务中断。此外,使用ponder时应考虑RPC返回数据的有效性。Safe最近报告了一次搜索引擎因错误的RPC返回数据而崩溃。虽然没有直接证据表明Goldsky事件与无效的RPC返回数据有关,但我怀疑Goldsky可能遇到了类似的问题。
3.2 本地优先开发理念
本地优先在过去几年一直是热门话题。简单来说,本地优先要求软件具备以下功能:
- 离线工作
- 跨客户端协作
目前,与本地优先技术相关的大多数讨论都涉及到CRDT(无冲突复制数据类型)。CRDT是一种无冲突的数据格式,允许用户在多个设备上操作时自动解决冲突并保持数据完整性。简单地想象CRDT就是一种带有简单共识协议的数据类型。在分布式环境中,CRDT可以保证数据的完整性和一致性。
然而,在区块链开发中,我们可以适度放宽上述本地优先软件的要求。我们只需要确保用户在没有项目开发者提供的后端索引数据时仍能保持最低限度的可用性。此外,区块链已经解决了跨客户端协作的本地优先要求。
在DApps的背景下,本地优先的概念可以这样实现:
- 缓存关键数据:前端应缓存重要的用户数据,如余额和持仓,这样即使索引服务不可用,用户仍然可以看到最后已知的状态。
- 降级功能设计:当后端索引服务不可用时,DApp可以提供基本功能。例如,当数据检索服务不可用时,一些数据可以直接通过RPC从链上读取,这可以确保用户可以看到某些现有数据的最新状态。
这种本地优先的DApp设计哲学显著提高了应用程序的弹性,防止了数据检索服务崩溃时的不可用性。无论可用性如何,最好的本地优先应用程序都需要用户运行本地节点,然后使用trueblocks等工具从本地检索数据。关于去中心化或本地检索的更多讨论,请参阅帖子“没有人关心去中心化前端和索引器”。
4、最后想法
Goldsky六小时的停机事件为整个生态系统敲响了警钟。虽然区块链本质上提供了去中心化和抗单点故障的能力,但建立在其上的应用生态系统仍然高度依赖于中心化基础设施服务。这种依赖对整个生态系统构成了系统性风险。
本文简要解释了为什么TheGraph这样一个长期存在的去中心化搜索服务今天并未被广泛使用,特别是讨论了GRT代币经济带来的复杂性。最后,本文讨论了如何构建更强大的数据搜索基础设施。我鼓励开发者使用Ponder自托管数据搜索框架作为应急选项,并概述了Ponder的一个有前景的商业化路径。最后,本文讨论了本地优先的开发理念,鼓励开发者构建即使没有数据搜索服务也能运行的应用程序。
目前,许多Web3开发者已经意识到数据检索服务的单点故障问题。GCC希望更多的开发者关注这一基础设施,并尝试构建去中心化的数据检索服务或设计一种框架,使DApp前端即使没有数据检索服务也能运行。
原文链接:Tragedy of the Crypto Commons Series: The Tragedy of Polymarket’s Data Indexing
DefiPlot翻译整理,转载请标明出处
免责声明:本站资源仅用于学习目的,也不应被视为投资建议,读者在采取任何行动之前应自行研究并对自己的决定承担全部责任。


