技术指标+机器学习模型
使用机器学习进行技术分析。发现突破(以及失望)当技术分析指标遇到人工智能。获得独特的见解、代码片段和真实的实验结果。

作为交易者,我们寻找策略中的特殊优势的旅程通常涉及探索不同的技术指标及其提供的信号。从简单的工具如简单移动平均线到更复杂的工具如抛物线 SAR,每个指标都旨在通过将其转化为有助于决策的有用规则来使市场行为更容易理解。
每个指标都有其特定的作用。一些指标,如 SMA 和 EMA,有助于显示价格的整体趋势,使我们更容易看到市场走向。其他指标,如 RSI 或 MACD,则关注动量,并可能提示可能的反转,为交易者提供有用的信号。像布林带或 ATR 这样的工具提供了对市场波动性和稳定性的见解,而成交量指标如 OBV 则显示了价格变动的力量。当有意识地一起使用时,这些工具可以为交易者提供更清晰、更完整的市场情况画面。
1、初步尝试
对于 RSI、MACD 等振荡器,我将它们转换为 1、0 和 -1。例如,RSI 高于 70 将被标记为 1(超买),低于 30 被标记为 -1(超卖),否则为 0(中性)。
all_stocks_df = all_stocks_df.copy().dropna()
all_stocks_df['52w_high'] = (
(all_stocks_df['52w_high'] - all_stocks_df['adjusted_close']) / all_stocks_df['adjusted_close'] * 100
)
all_stocks_df['52w_low'] = (
(all_stocks_df['52w_low'] - all_stocks_df['adjusted_close']) / all_stocks_df['adjusted_close'] * 100
)
all_stocks_df['sma_sma'] = (
(all_stocks_df['sma_sma'] - all_stocks_df['adjusted_close']) / all_stocks_df['adjusted_close'] * 100
)
all_stocks_df['ema_ema'] = (
(all_stocks_df['ema_ema'] - all_stocks_df['adjusted_close']) / all_stocks_df['adjusted_close'] * 100
)
all_stocks_df['wma_wma'] = (
(all_stocks_df['ema_ema'] - all_stocks_df['adjusted_close']) / all_stocks_df['adjusted_close'] * 100
)
all_stocks_df['sar_sar'] = (
(all_stocks_df['sar_sar'] - all_stocks_df['adjusted_close']) / all_stocks_df['adjusted_close'] * 100
)
all_stocks_df['rsi_rsi'] = np.select(
[
all_stocks_df['rsi_rsi'] > 70,
all_stocks_df['rsi_rsi'] < 30
],
[1, -1],
default=0
).astype('int8')
all_stocks_df['stochastic_k_values'] = np.select(
[
all_stocks_df['stochastic_k_values'] > 80,
all_stocks_df['stochastic_k_values'] < 20
],
[1, -1],
default=0
).astype('int8')
all_stocks_df['stochastic_d_values'] = np.select(
[
all_stocks_df['stochastic_d_values'] > 80,
all_stocks_df['stochastic_d_values'] < 20
],
[1, -1],
default=0
).astype('int8')
all_stocks_df['cci_cci'] = np.select(
[
all_stocks_df['cci_cci'] > 100,
all_stocks_df['cci_cci'] < -100
],
[1, -1],
default=0
).astype('int8')
all_stocks_df['macd_macd'] = (
(all_stocks_df['macd_macd'] - all_stocks_df['macd_signal']) / all_stocks_df['macd_signal'] * 100
)
all_stocks_df.drop(['macd_signal', 'macd_divergence'], axis=1, inplace=True)
# 计算绝对距离
dist_u = (all_stocks_df['adjusted_close'] - all_stocks_df['bbands_uband']).abs()
dist_m = (all_stocks_df['adjusted_close'] - all_stocks_df['bbands_mband']).abs()
dist_l = (all_stocks_df['adjusted_close'] - all_stocks_df['bbands_lband']).abs()
# 创建距离数据框
distances = pd.concat([dist_u, dist_m, dist_l], axis=1)
distances.columns = [1, 0, -1] # 映射到所需输出
# 找到每行中距离最小的列(信号)
all_stocks_df['bbands_uband'] = distances.idxmin(axis=1)
all_stocks_df.rename(
columns={'bbands_uband': 'bbands_bband'},
inplace=True
)
all_stocks_df.drop(['bbands_mband', 'bbands_lband'], axis=1, inplace=True)
现在开始训练。几点注意事项:
- 我将使用数据集的前 80% 进行训练,然后在剩余的 20% 上进行测试。如果你使用 sklearn 的随机分割,你将会得到超过 90% 的准确率,但这将是不正确的,因为你将用未来事件进行训练,用过去事件进行测试——这相当于作弊;
- 我会将结果保存在一个名为
results的字典中,以便以后绘图和处理,这对于你自己进一步检查也很有帮助。
def return_model_and_results(df, exclude_ind=None):
# 确保按时间排序以允许按时间顺序拆分
df = df.sort_values(['date']).reset_index(drop=True)
# 早期拆分:定义训练和测试数据帧(按时间顺序的 80/20)
n_total = len(df)
n_train = int(n_total * 0.80)
train_df = df.iloc[:n_train].copy()
test_df = df.iloc[n_train:].copy()
# 从训练数据帧中删除所有 NA
train_df = train_df.dropna()
test_df = test_df.dropna()
train_df.to_csv('train.csv')
test_df.to_csv('test.csv')
# 选择你的特征:删除目标列和所有不想作为特征使用的列
excluded_cols = [
"target_1w_class", "target_1m_class", "target_3m_class",'ret_1w', 'ret_1m', 'ret_3m',
"ticker", 'open', 'high', 'low', 'close', 'adjusted_close', 'volume', 'date'
]
if exclude_ind:
excluded_cols.extend(exclude_ind)
# print(exclude_ind)
# 从各自的 dataframe 中构建训练和测试的特征
features_train = train_df.drop(columns=[col for col in excluded_cols if col in train_df.columns])
features_test = test_df.drop(columns=[col for col in excluded_cols if col in test_df.columns])
features_test.to_csv('test_features.csv')
features_train.to_csv('train_features.csv')
feature_names = features_train.columns
# 准备标签编码器以固定类别,避免未见类问题
le_1w, le_1m, le_3m = LabelEncoder(), LabelEncoder(), LabelEncoder()
fixed_classes = ['Down', 'Neutral', 'Up']
le_1w.fit(fixed_classes)
le_1m.fit(fixed_classes)
le_3m.fit(fixed_classes)
# 帮助函数,用于对 train_df 进行训练并在 test_df 上进行评估,针对给定的目标列
def train_and_eval_for_target(target_col, label_encoder):
# 训练标签/特征
y_train_raw = train_df[target_col]
X_train = features_train
# 因为 train_df 已经完全 dropna(),所以 X_train 和 y_train_raw 都是非空的
Y_train = label_encoder.transform(y_train_raw)
# 测试标签/特征:使用 test_df 提供准确性(过滤具有可用目标的行)
y_test_raw = test_df[target_col]
valid_test_idx = y_test_raw.dropna().index
if len(valid_test_idx) == 0:
# 对于这个时间范围,测试集中没有可用的标签
model = xgb.XGBClassifier(use_label_encoder=False, eval_metric="mlogloss", random_state=42)
model.fit(X_train, Y_train)
return model, "No test labels available.", float('nan')
X_test = features_test.loc[valid_test_idx]
y_test = y_test_raw.loc[valid_test_idx]
Y_test = label_encoder.transform(y_test)
model = xgb.XGBClassifier(use_label_encoder=False, eval_metric="mlogloss", random_state=42)
model.fit(X_train, Y_train)
y_pred = model.predict(X_test)
# 使用测试数据帧构建报告/准确性
# target_names 从 fixed_classes 导出以确保顺序
cl_report = classification_report(Y_test, y_pred, target_names=label_encoder.classes_, zero_division=0)
# print(f"Classification report for {target_col}:")
# print(cl_report)
acc_score = accuracy_score(Y_test, y_pred)
return model, cl_report, acc_score
# 使用新的拆分逻辑训练每个目标的模型
model_1w, cl_report_1w, acc_score_1w = train_and_eval_for_target("target_1w_class", le_1w)
model_1m, cl_report_1m, acc_score_1m = train_and_eval_for_target("target_1m_class", le_1m)
model_3m, cl_report_3m, acc_score_3m = train_and_eval_for_target("target_3m_class", le_3m)
def get_top_feature_importances(model):
importances = model.feature_importances_
return importances
features_importance_1w = get_top_feature_importances(model_1w)
features_importance_1m = get_top_feature_importances(model_1m)
features_importance_3m = get_top_feature_importances(model_3m)
results_to_return = \
{
'1w':
{
'model': model_1w,
'feature_names': feature_names,
'acc_score': acc_score_1w,
'cl_report': cl_report_1w,
'features_importance': features_importance_1w
},
'1m': {
'model': model_1m,
'feature_names': feature_names,
'acc_score': acc_score_1m,
'cl_report': cl_report_1m,
'features_importance': features_importance_1m
},
'3m': {
'model': model_3m,
'feature_names': feature_names,
'acc_score': acc_score_3m,
'cl_report': cl_report_3m,
'features_importance': features_importance_3m
}
}
return results_to_return
results = return_model_and_results(all_stocks_df)
# results
print(results['1w']['acc_score'])
print(results['1m']['acc_score'])
print(results['3m']['acc_score'])
初始结果并不令人兴奋:
1w : 0.6657852987837123
1m : 0.3643574828133263
3m : 0.41459545214172394
看起来我们的模型都不成功,只有 1 周模型达到了约 66%。那么,让我们使用下面的代码绘制每个模型的分类报告,以获得进一步的见解。
def parse_classification_report(report_str):
lines = [l.strip() for l in report_str.strip().splitlines() if l.strip()]
rows = []
header_found = False
for l in lines:
if not header_found and l.lower().startswith("precision"):
header_found = True
continue
if any(l.lower().startswith(x) for x in ["accuracy", "macro avg", "weighted avg"]):
continue
parts = l.split()
if len(parts) == 5:
cls, prec, rec, f1, supp = parts
rows.append((cls, float(prec), float(rec), float(f1), int(supp)))
return pd.DataFrame(rows, columns=["class", "precision", "recall", "f1", "support"])
def plot_classification_report_bars(df, title):
metrics = ["precision", "recall", "f1"]
x = np.arange(len(df))
width = 0.25
offsets = np.linspace(-width, width, num=len(metrics))
colors = ['#1f77b4', '#ff7f0e', '#2ca02c']
plt.figure(figsize=(8, 5))
for i, m in enumerate(metrics):
plt.bar(x + offsets[i], df[m].values, width, label=m, color=colors[i])
plt.xticks(x, df["class"].values)
plt.ylim(0, 1)
plt.ylabel("Score")
plt.title(title)
plt.legend()
plt.grid(axis='y', linestyle='--', alpha=0.4)
plt.tight_layout()
plt.show()
def plot_classification_reports_subplots(cr_items, results_dict):
"""
在单个图表中将多个分类报告数据框作为子图进行绘制。
cr_items: 元组列表 (label, df, period_key)
results_dict: 包含每个 period_key 的指标的字典
"""
# 过滤掉 None 数据框
valid = [(label, df, key) for (label, df, key) in cr_items if df is not None]
if not valid:
print("没有要绘制的分类报告。")
return
metrics = ["precision", "recall", "f1"]
colors = ['#1f77b4', '#ff7f0e', '#2ca02c']
n = len(valid)
fig, axs = plt.subplots(1, n, figsize=(max(8*n, 8), 5), sharey=True)
if n == 1:
axs = [axs]
for ax, (label, df, key) in zip(axs, valid):
x = np.arange(len(df))
width = 0.25
offsets = np.linspace(-width, width, num=len(metrics))
for i, m in enumerate(metrics):
ax.bar(x + offsets[i], df[m].values, width, label=m, color=colors[i])
ax.set_xticks(x)
ax.set_xticklabels(df["class"].values)
ax.set_ylim(0, 1)
acc = None
if key in results_dict and isinstance(results_dict[key], dict):
acc = results_dict[key].get('acc_score', None)
title = f"{label} (Acc: {acc:.3f})" if acc is not None else label
ax.set_title(title)
ax.set_ylabel("Score")
ax.grid(axis='y', linestyle='--', alpha=0.4)
# 使用一个单一的图例为所有子图
handles, labels = axs[0].get_legend_handles_labels()
fig.legend(handles, labels, loc='upper center', ncol=len(metrics))
fig.suptitle("按类别划分的分类报告 —— 所有周期")
plt.tight_layout(rect=[0, 0, 1, 0.92])
plt.show()
cr_1w_df = parse_classification_report(results['1w']['cl_report']) if '1w' in results else None
cr_1m_df = parse_classification_report(results['1m']['cl_report']) if '1m' in results else None
cr_3m_df = parse_classification_report(results['3m']['cl_report']) if '3m' in results else None
# 组合图表,为所有可用周期绘制子图
plot_classification_reports_subplots([
("1 Week", cr_1w_df, '1w'),
("1 Month", cr_1m_df, '1m'),
("3 Months", cr_3m_df, '3m'),
], results)
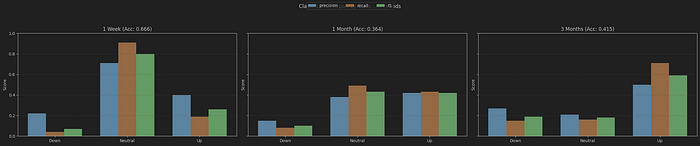
报告表明,由于 5% 的规则,大多数股票在一周内保持中性——这意味着它们大部分时间没有上涨或下跌超过 5%。因此,成功率看起来很高,因为模型建议我们在那一周不做任何行动。这不是很聪明,对吧?
另一个有趣的一点是,对于 3 个月的模型,即使整体分数不是特别出色,它在预测三个月内上涨超过 5% 的股票方面相对较好。但不要忘记,股市往往会上涨,这也是这个指标看起来积极的原因之一。
我们还可以在这个实验旅程中包括的另一件事是看看哪些技术指标对模型来说更重要。
def plot_grouped_feature_importances(results_dict, top_n=15):
periods = ['1w', '1m', '3m']
# 确保所有周期都存在
periods = [p for p in periods if p in results_dict]
if not periods:
print("在结果中没有找到有效的周期。")
return
# 假设特征名称在各周期中是一致的
feature_names = list(results_dict[periods[0]]['feature_names'])
data = {'feature': feature_names}
for p in periods:
data[p] = results_dict[p]['features_importance']
df_imp = pd.DataFrame(data)
df_imp['max_imp'] = df_imp[periods].max(axis=1)
df_top = df_imp.sort_values('max_imp', ascending=False).head(top_n)
x = np.arange(len(df_top))
width = 0.25
offsets = np.linspace(-width, width, num=len(periods))
plt.figure(figsize=(max(12, top_n * 0.6), 6))
colors = ['#1f77b4', '#ff7f0e', '#2ca02c']
for i, p in enumerate(periods):
plt.bar(x + offsets[i], df_top[p].values, width, label=p, color=colors[i % len(colors)])
plt.xticks(x, df_top['feature'].values, rotation=65, ha='right')
plt.ylabel('特征重要性')
plt.title('按周期划分的特征重要性(分组)')
plt.legend(title='周期')
plt.grid(axis='y', linestyle='--', alpha=0.4)
plt.tight_layout()
plt.show()
plot_grouped_feature_importances(results, top_n=15)
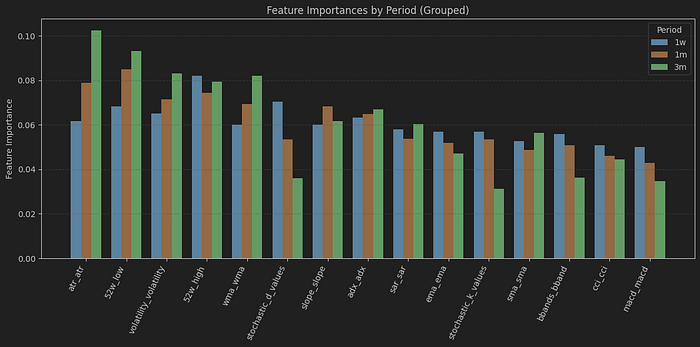
我对这张图的一些观察:
- 1 周模型(蓝色),它非常擅长预测中性(哈哈),显得有些困惑,因为指标的重要性非常相似。值得注意的是,52 周高点排在首位,突显了这一指标的一般重要性。
- 关于 1 个月模型(橙色)以及 3 个月模型(绿色),我们观察到它在预测上涨趋势方面有有趣的准确性,52 周高点和低点,以及 ATR 和波动率是这一预测中最关键的指标。
2、现在让我们玩一玩
尽管到目前为止的结果并不令人鼓舞,但我很兴奋地探索一些“假设”场景以获得更深入的见解。这是学习过程的一部分,我期待着发现新的可能性!
对于每种情况,我不会再次展示代码。你可以直接前往我提到的参数部分来获取结果,甚至可以自己“玩”更多。
如果我给模型输入原始数字呢?
例如,RSI 列将保留原始值,这意味着 27 不会被转换为 -1。一般来说,我们应该“协助”训练,利用我们的专业知识。但如果输入原始数字,事情会变得多糟糕?
你只需要运行代码,跳过那部分即可。
1w : 0.6460317460317461
1m : 0.3772486772486772
3m : 0.3772486772486772
与之前的相比,我们看到使用标准化数据的训练表现略好,证实了理论所提出的内容。
如果我为每只股票单独训练模型呢?
而不是用七只股票训练模型,我会为每只股票单独训练。要做到这一点,只需去股票代码列表并只保留一只股票。结果如下:
['MSFT.US']
1w : 0.8555555555555555
1m : 0.32222222222222224
3m : 0.26296296296296295
['AAPL.US']
1w : 0.7296296296296296
1m : 0.31851851851851853
3m : 0.3037037037037037
['META.US']
1w : 0.5777777777777777
1m : 0.3037037037037037
3m : 0.2074074074074074
['GOOGL.US']
1w : 0.6777777777777778
1m : 0.43703703703703706
3m : 0.3888888888888889
['NVDA.US']
1w : 0.3874538745387454
1m : 0.3726937269372694
3m : 0.5350553505535055
['AVGO.US']
1w : 0.46494464944649444
1m : 0.4317343173431734
3m : 0.5129151291512916
['AMZN.US']
1w : 0.6826568265682657
1m : 0.24354243542435425
3m : 0.2767527675276753
对于所有股票,1 周模型表现更好,得分在 70% 到 80% 之间(除了 NVDIA 和 AVGO),而 1 个月和 3 个月模型表现更差——再次,除了 NVDIA 和 AVGO!它们在 3 个月模型中得分超过 50%。
在哪些指标更重要方面,结果几乎相同;然而,我注意到 52 周高点和低点的重要性增加了。
如果我们用较短的时间段进行训练和测试呢
我们生活在一个快节奏的世界里,所以我很好奇,考虑技术指标如何影响价格基于 2020 或 2021 年的数据有多相关。因此,我决定也使用 2023 年的数据进行测试,并专注于最近几个月。
start_date = "2022-01-01"
end_date = "2025-08-15"
with 95%
['MSFT.US', 'AAPL.US', 'META.US', 'GOOGL.US', 'NVDA.US', 'AVGO.US', 'AMZN.US']
1w : 0.46153846153846156
1m : 0.2548076923076923
3m : 0.8942307692307693
在这种情况下,3 个月模型表现极佳,准确率超过 80%,并且在上涨趋势中超过 85%。
3、结束语
正如我一开始所说,这是一个实验,而实验有时可能会令人兴奋,有时(就像这次一样)会给我们提供思考的空间,并激发更多可能带来令人兴奋结果的想法。从这次实验中我了解到以下几点:
- 52 周高点和低点指标对于理解股票走势非常有帮助。这并不奇怪,因为分析师在快速总结股票价格时通常首先提到它们。
- 模型相当聪明——它最初使用了像 ATR 和波动率这样的波动指标(可能是因为它注意到了那里的模式),然后转向了简单的趋势跟随工具如 WMA 和斜率。有趣的是,动量如 RSI 或 MACD 并不在前十名中。
- 持续训练模型非常重要。当我训练模型后只使用了一段时间,我发现长期目标(3 个月)的结果更好,这让我感到非常兴奋。
最后,我想分享的是,这个话题确实为探索打开了令人兴奋的机会!使用代码(你也可以在这里找到),你可以研究不同的股票(也许是一些低价股!),在指标本身上尝试各种参数,尝试不同的训练时间段,或者甚至添加新的特征如行业分类。有一点是肯定的:代码已经在那里,所以请随意复制、增强并尽情实验!
原文链接:What Happens When You Feed Dozens of Technical Indicators to a Machine Learning Model?
DefiPlot翻译整理,转载请标明出处
免责声明:本站资源仅用于学习目的,也不应被视为投资建议,读者在采取任何行动之前应自行研究并对自己的决定承担全部责任。


