序数铭文详解
着Ordinal协议的创建,它提供了对比特币进行编号和记录的能力,它扩大了比特币生态系统可用的产品范围,并为比特币生态系统带来了新的活力。 本文将深入探讨 Ordinal 协议的细节。

一键发币: Aptos | X Layer | SUI | SOL | BNB | ETH | BASE | ARB | OP | Polygon | Avalanche | 用AI学区块链开发
随着Ordinal协议的创建,它提供了对比特币进行编号和记录的能力,它扩大了比特币生态系统可用的产品范围,并为比特币生态系统带来了新的活力。 在本文中,我们将深入探讨 Ordinal 协议的细节,包括每个比特币如何编号和跟踪,以及铭文如何与编号相关。 但在深入讨论这个主题之前,我们需要首先了解一些比特币的基本背景,以帮助我们更好地理解接下来的内容。
完成本文后,你将掌握比特币的交易机制和支付模型,了解Ordinals如何对每个聪实现编号和跟踪,以及铭文如何创建和交易。 此外,你还将了解不同类型钱包之间的差异。
1、比特币背景
比特币采用类似现金的交易模型,其支付基于一种称为 UTXO 的模型,与传统的基于账户余额的模型不同。 例如,在银行账户记账模型流程中,当 A 向 B 转账 100 美元时,银行会记录构成交易流程的三个步骤。 第一步从A的账户中扣除100美元,这一步的记录ID是tid1。 第二步,向 B 的账户存入 100 美元,这一步的记录 ID 为 tid2。 第三步,记录一条tid1和tid2关联的转账记录,表示A账户减少了100美元,B账户增加了100美元。 这样A和B之间的转账关系就被记录下来,以后可以查询和追溯。 现在,我们通过介绍UTXO和支付模型来解释比特币支付是如何进行的。
1.1 UTXO
在比特币区块链中,所有余额都存储在一个称为未消费交易输出(UTXO)的列表中。 每个 UTXO 都包含一定数量的比特币,以及这些比特币所有者的信息,并指示它们是否可用。 可以把它想象成一张写有持有人姓名的现金支票,只要持有人签字就可以转让给他人使用。 对于给定地址,其所有 UTXO 金额加起来就是该地址钱包的余额。 通过遍历所有UTXO,我们可以获得每个地址当前的余额。 将所有 UTXO 数量加起来就是当前流通的比特币总量。
在比特币的交易结构中,每笔交易都由多个输入和输出组成,其中每个输入都是对现有 UTXO 的引用,每个输出指定将接收资金的新地址以及相应的金额。 一旦交易启动,其输入部分引用的UTXO将被暂时锁定,以防止重复使用,直到交易完成。 只有当这笔交易被矿工成功打包到区块中并被网络确认时,相关的UTXO状态才会发生变化。 具体来说,用作交易输入的UTXO将从UTXO列表中删除,表明它们已被消耗,而交易的输出会生成新的UTXO并添加到UTXO列表中。 可以理解为,旧的现金支票被使用,然后到期,生成新的现金支票,其所有权属于新的持有者。
值得强调的是,每个UTXO在单笔交易中只能使用一次。 一旦它作为输入被消耗,它就会从 UTXO 列表中永久删除。 同时,新生成的输出作为新的UTXO添加到列表中。 UTXO 列表不断变化,并且随着每个新块的创建,它也会相应更新。 而且,通过分析区块链中的交易历史记录,我们能够重建任意给定时间点的 UTXO 列表的状态。
此外,一笔交易的总输入金额通常会略高于其总输出金额。 这种差异称为交易费或网络费,是对负责将交易打包到区块中的矿工的激励。 网络费用的大小与交易的复杂性成正比,因此包含更多输入和输出的交易通常需要更高的网络费用。
现在,为了更直观地理解比特币交易的结构,我们将通过一个具体的例子来进行说明。 比特币交易的结构如下,其中变量vin和vout分别代表比特币交易的“输入”和“输出”。 与记录账户形状数据变化的传统账户余额模型不同,比特币交易不由输入和输出表示:
const std::vector<CTxIn> vin;
const std::vector<CTxOut> vout;
const int32_t nVersion;
const uint32_t nLockTime;我们可以在blockchain.com上随机挑选一条交易记录来分析。 下图显示了哈希 ID 为 06270***345c2f2 的交易。 它包含一个输入和两个输出:

通过使用bitcoin-cli命令 getrawtransaction和 decoderawtransaction,我们可以看到上述交易的底层结构:
{
"version": 1,
"locktime": 0,
"vin": [
{
"txid": "7957a35fe64f80d234d76d83a2a8f1a0d8149a41d81de548f0a65a8a999f6f18",
"vout": 0,
"scriptSig" : "3045022100884d142d86652a3f47ba4746ec719bbfbd040a570b1deccbb6498c75c4ae24cb02204b9f039ff08df09cbe9f6addac960298cad530a863ea8f53982c09db8f6e3813[ALL] 0484ecc0d46f1918b30928fa0e4ed99f16a0fb4fde0735e7ade8416ab9fe423cc5412336376789d172787ec3457eee41c04f4938de5cc17b4a10fa336a8d752adf",
"sequence": 4294967295
}
],
"vout": [
{
"value": 0.01500000,
"scriptPubKey": "OP_DUP OP_HASH160 ab68025513c3dbd2f7b92a94e0581f5d50f654e7 OP_EQUALVERIFY OP_CHECKSIG"
},
{
"value": 0.08450000,
"scriptPubKey": "OP_DUP OP_HASH160 7f9b1a7fb68d60c536c2fd8aeaa53a8f3cc025a8 OP_EQUALVERIFY OP_CHECKSIG",
}
]
}在比特币网络中,交易输出包含两个重要信息:地址(公钥哈希)和金额(以比特币为单位)。 如果一笔交易的输出没有用于其他交易的输入,那么该交易输出称为未花费交易输出(UTXO)。 谁拥有UTXO中公钥对应的私钥,谁就有权使用或花费这个UTXO。
我们看一下上面代码中“vin”的信息,该信息表明该笔交易花费的UTXO来自于第0个输出(可以有多个输出)的另一笔交易(id为7957a3***999f6f18) 一笔交易的索引从0开始编号),我们可以从交易的历史记录中找到这条UTXO的金额(例如0.1),所以这个值0.1不需要显式写入交易中,而是 通过查找UTXO信息获得。 这笔交易的“vout”有两个输出,分别是两个新的UTXO,对应新的余额和持有者,直到另一笔交易将它们作为输入消耗。
1.2 支付模式
为了更好地理解比特币网络的支付模型,我们举一个从 A 到 B 支付 n 个比特币的支付流程示例。 下图展示了用户A向用户B发送3个比特币的过程:
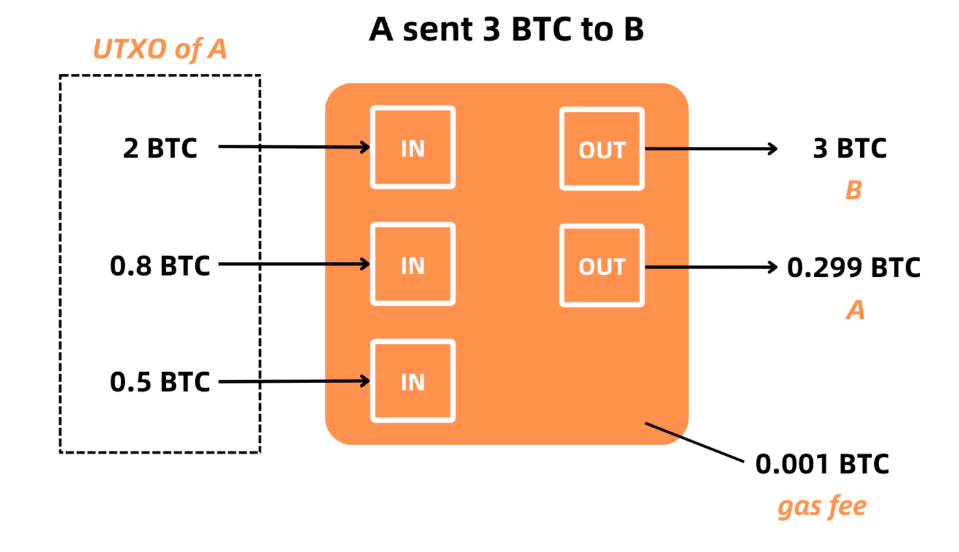
- 对于用户A来说,首先需要确定其拥有的所有UTXO的集合,即用户A可以支配的所有比特币;
- A从这组中选择一个或多个UTXO作为交易的输入,这些输入的总和为m(2+0.8+0.5=3.3 BTC),大于要支付的金额n(3 BTC) ;
- 用户A为交易设置两个输出,一个输出以n(3 BTC)金额支付到B的地址,另一个输出以m-n-fee(3.3-3-0.001=0.299 BTC)金额支付到A自己的找零地址之一 。 用户的钱包通常由多个地址组成,每个地址通常只使用一次,找零默认返回到新地址;
- 等待矿工将这笔交易打包上链确认,B就可以收到这笔交易信息。 由于区块大小有上限(约1MB),矿工会优先确认交易率高(fee_rate=fee/size)的交易,以获得最高的手续费回报。 我们可以在mempool看到实时挖矿交易费用。 如果我们希望在转账过程中得到最快的确认,我们可以选择高优先级或自定义合适的交易费率。
2、Satoshi编号和追踪
比特币总数为2100万个,每个比特币包含10^8聪(Sat)。 因此,比特币网络上有 2100 万 * 10^8 聪。 序数协议(ordinals protocol)通过对每个聪进行唯一编号来区分这些聪。 本节介绍协议如何执行此操作,以及如何跟踪每个聪所在的帐户。 另外,还将描述聪的稀有度分类。
2.1 Satoshi编号
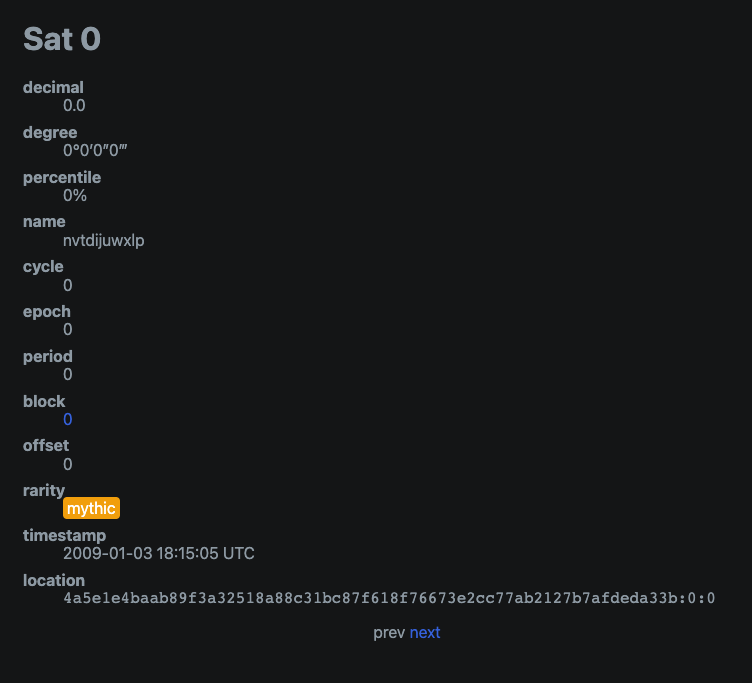
根据 Ordinals 协议,聪是根据开采顺序进行编号的。 下图显示了从第0个区块开采的第0个聪的表示。
序数有多种表示形式:
- 整数表示法:例如 2099994106992659 序数,根据聪的开采顺序分配。
- 十进制表示法:例如 3891094.16797, 第一个数字是开采聪的区块高度,第二个数字是聪在区块内的偏移量。
- 度数表示法:例如 3°111094′214″16797‴。 第一个数字是周期,从0开始编号,第二个数字是减半纪元的区块索引,第三个数字是难度调整期间的区块索引,最后一个数字是区块中sat的索引。
我们将通过一个示例来说明如何对新开采的比特币进行编号。 查看比特币区块链的区块 795952,我们可以看到第一笔交易 Tx 3a1f…b177 记录了矿工的奖励(coinbase 交易)。 该交易包含新开采的比特币,这些比特币作为对矿工的打包奖励,以及交易发起者向矿工支付的费用。 通过查看下图的输入,我们可以看到它的 UTXO id 由一串零和块高度组成。 那么输出地址就是矿工的钱包地址,金额就是上面提到的奖励和费用的总和。
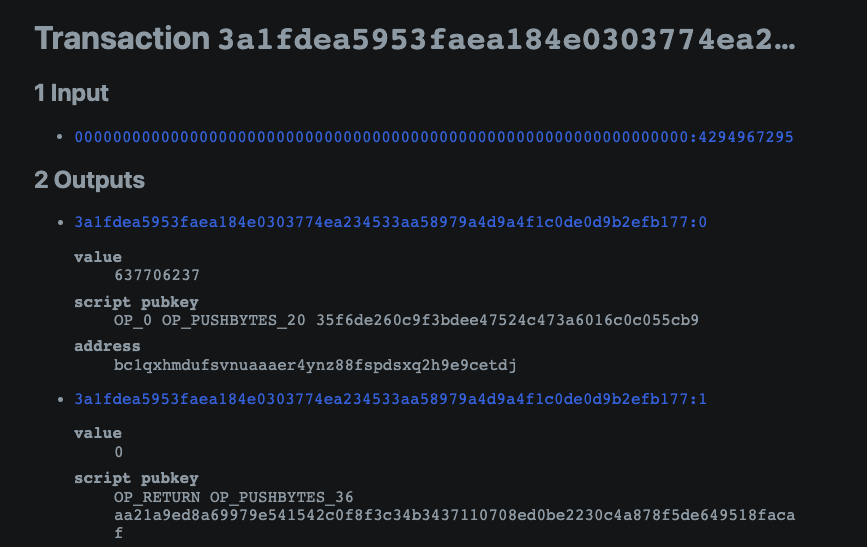
如果我们进一步查看矿工输出的部分,可以看到地址、金额和所包含的聪的分布。 如前所述,其中包含挖矿奖励和费用。 其中,绿色sats编号信息1941220000000000-1941220625000000是挖矿奖励产生的新satoshi,而其余712satoshi记录对应于区块中的所有费用。
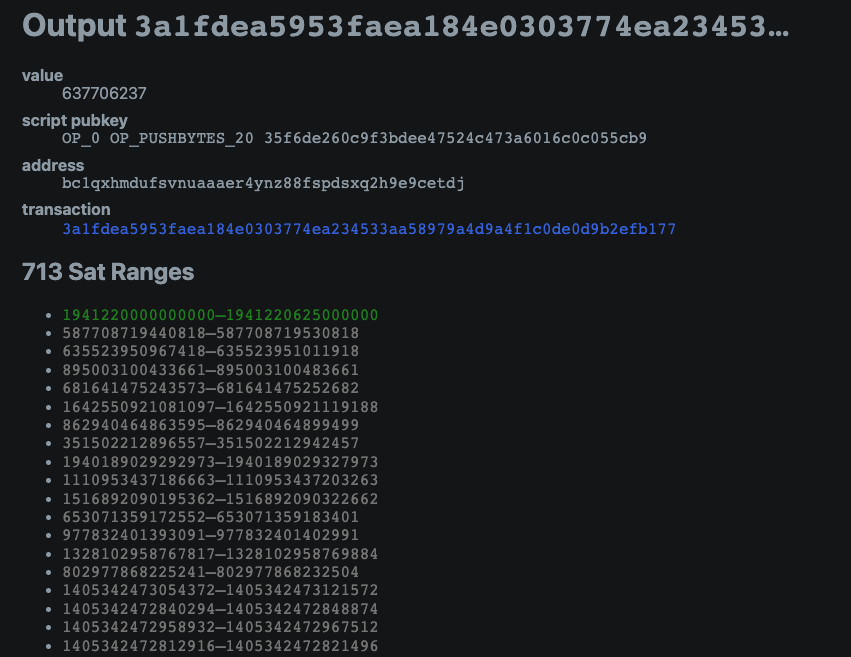
我们可以验证一下Sat 1941220000000000这个数字,它的区块编号是795952,小数点是795952.0,也就是说挖这个satoshi的区块高度是795952,这个区块内的satoshi的编号是0,后面加上稀有度标记,即 我们将在后面的部分详细描述。
2.2 Satoshi流程
因为每一个BTC都是通过挖矿奖励产生的,所以都是可追溯的。 比特币账户使用UTXO模型。 假设用户A通过挖矿获得了第100-110聪(这10聪整体存储在id为adc123的同一个UTXO中)。 当用户A想要向用户B支付5 satoshi时,他选择使用id abc123作为交易的输入,其中5 satoshi给用户B,5 satoshi作为找零返回给用户A。 5 聪的两个副本都作为一个整体存储在两个 UTXO 中,ID 分别为 abc456 和 abc789。 上述 UTXO id 和 satoshi 数量仅作为示例显示,实际上最小数量是 546sats,并且 UTXO id 不以这种形式表示。
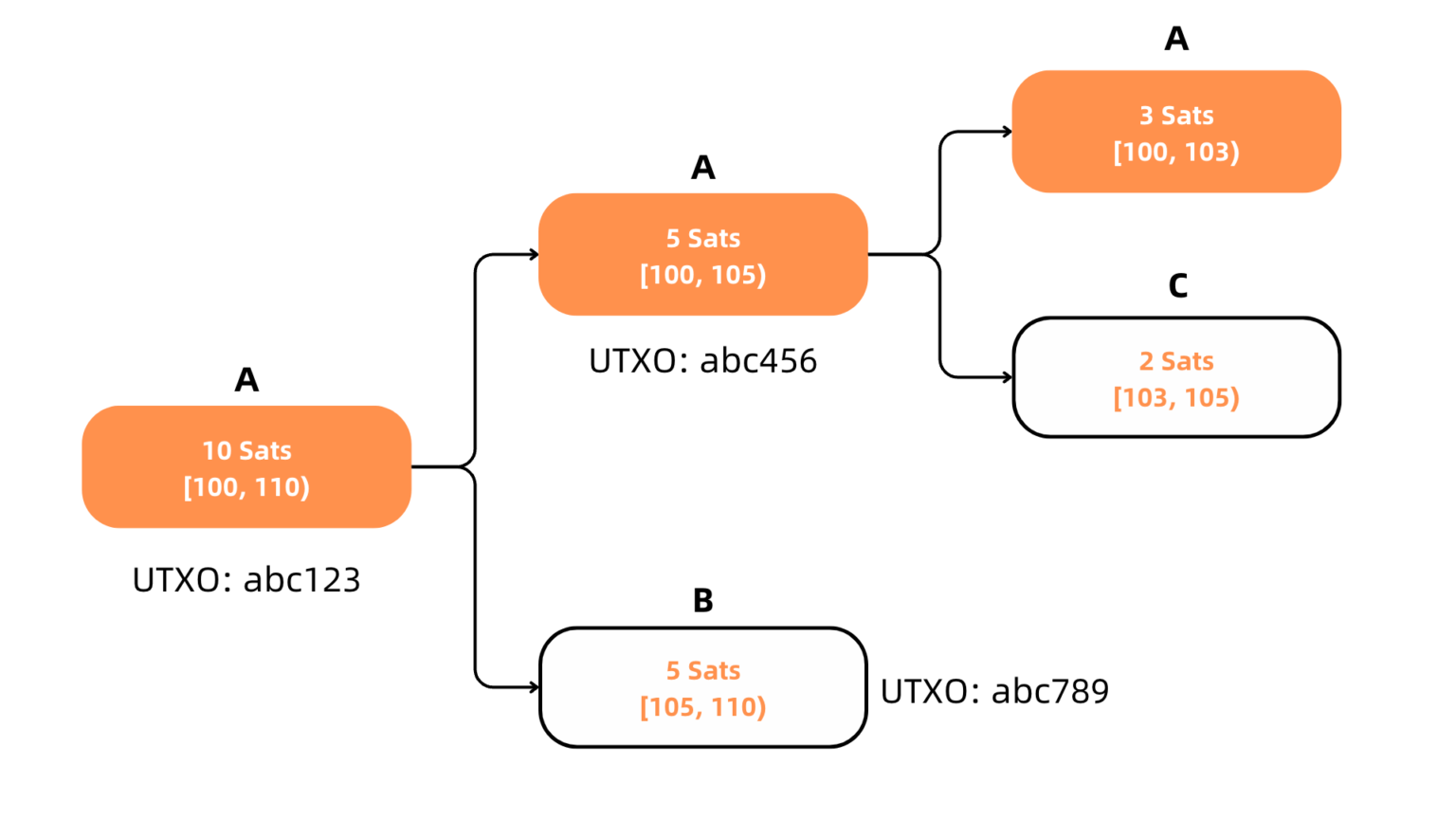
上述交易中,用户A的10聪的流向路径为
- 挖矿产生 10 聪,数字为 [100, 110)。 这意味着第100到109聪存储在id为abc123的UTXO中,其所有者是用户A。
- 当A进行转账时,这10聪被分成两部分,每部分5聪。 这里采用“先进先出”的原则,即聪的编号由其在交易输出中的索引决定。 假设输出的顺序是用户 A,然后是用户 B,那么用户 A 剩余的 5 聪编号为 [100 , 105) 并存储在 id abc456 的 UTXO 中,而用户 B 的 5 聪编号为 [105] , 110) 并存储在 ID 为 abc789 的 UTXO 中。
2.3 稀有satoshi
作为 Ordinals 协议的衍生玩法,satoshi的稀有度可以根据开采的顺序来定义。 这将导致一些特殊的中本聪具有不同的稀有度。 以下是不同中本聪的稀有度等级:
- common:普通,任何不是其区块中第一个 sat 的 sat(总供应量:2.1 千万亿)
- uncommon:罕见,每个区块的第一个周六(总供应量:6,929,999)
- rare:稀有,每个难度调整期的第一轮(总供应量:3437)epic:史诗,每个减半时期的第一个星期六(总供应量:32)
- legendary:传奇,每个周期的第一个星期六(总供应量:5)
- mythic:神话,创世区块的第一个卫星(总供应量:1)
这种稀有聪的概念可以为比特币生态系统增加更多的兴趣和价值。 不同稀有度的中本聪在市场上可能具有不同的价值,吸引着收藏家和投资者。
3、铭文方法
Ordinals 与非比特币链上的其他 NFT 显着不同。 主要区别之一是 Ordinals 的元数据不存储在特定位置。 相反,元数据嵌入在交易的见证数据中,这就是为什么我们称其为“铭文”,因为它就像铭文一样“刻”在比特币交易的特定部分上。 数据附加到特定的聪。 这个铭文过程是通过隔离见证(SegWitness)和Pay-to-Taproot(P2TR)来实现的,包括两个阶段:提交和揭示。 可以在指定的聪上刻写任何类型的内容(例如文本、图像或视频)。 下面我们将介绍另一种更直接的存储方式 OP_RETURN,并解释为什么不使用它作为铭文手段。 此外,我们还将描述什么是孤立见证人和 Pay-to-Taproot 以及它们在铭文中扮演什么角色。 最后介绍一下铭文的方式。
3.1 OP_RETURN
在Bitcoin Core客户端0.9版本中,最终通过采用RETURN运算符实现了妥协。 RETURN 允许开发者将 80 字节的非支付数据添加到交易输出中。 与伪支付不同,RETURN 创建了一个明确可验证的非消耗性输出; 此类数据不需要存储在UTXO集中。 RETURN 输出记录在区块链上,它们会消耗磁盘空间并导致区块链大小增加,但它们不会存储在 UTXO 集中,因此不会使 UTXO 内存池膨胀,也不会增加昂贵的内存成本 全节点。
虽然 OP_RETURN 是一种非常简单的将信息存储到比特币区块链的方法,但它也是一种潜在的铭文方法。 然而,OP_RETURN的局限性使其在处理元数据存储时面临一些挑战。 首先,OP_RETURN只能存储80字节的数据,这对于需要存储大量数据的情况显然无法满足。 其次,OP_RETURN数据存储在交易输出部分,虽然此类数据不存储在UTXO集中,但它们占用了区块链中的存储空间,导致区块链的大小增加。 最后,使用 OP_RETURN 会导致交易费用增加,因为发布这些交易需要支付更多费用。
3.2 隔离见证
相比之下,SegWit 提供了一种克服这些问题的新方法。 SegWit是比特币的重大协议升级,由比特币核心开发者Pieter Wuille在2015年提出,最终在2017年的0.16.0版本中正式采用。 一笔交易。 因此,SegWit 是将某些交易签名数据(见证数据)从交易中分离出来。
将签名与交易相关数据分开的主要好处是,它减少了存储在比特币区块中的数据的大小。 这为每个区块提供了额外的容量来存储更多交易,并且意味着网络可以处理更多交易并且发送者支付更低的费用。 从技术上讲,这意味着将 scriptSig 信息从基本块中取出,并将其放入新的数据结构中。 Segwit升级在交易输出中引入了新的见证字段,以确保隐私和性能。 虽然见证数据不是为数据存储而设计的,但它实际上为我们提供了存储铭文元数据等内容的机会。 让我们通过下图更形象地理解隔离见证:
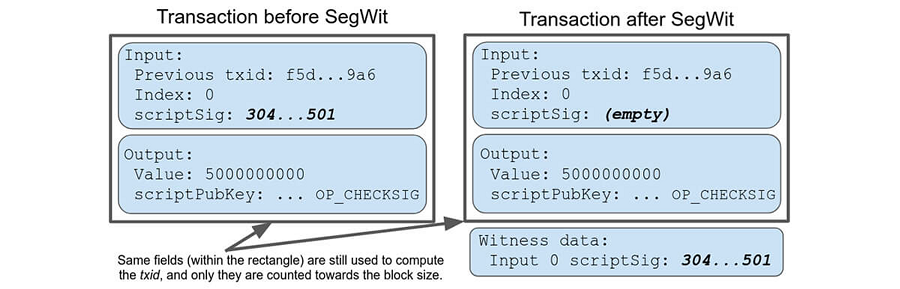
3.3 TapRoot
P2TR是比特币的一种交易输出类型,是在2021年发生的Taproot升级中引入的,它允许不同的交易条件以更私密的方式存储在区块链中。 P2TR 在序号铭文中起着至关重要的作用。 铭文本质上是将特定的数据内容嵌入到比特币交易中,而Taproot升级,特别是P2TR,使得这种嵌入的数据更加灵活和经济。
首先,由于 Taproot 脚本的存储方式,我们可以将铭文内容存储在 Taproot 脚本路径中,花费脚本的内容实际上是无限的,同时仍然获得见证数据的折扣,使得存储铭文内容相对经济。 由于 Taproot 脚本只能从现有的 Taproot 输出中使用,因此使用两阶段提交/显示过程来提交/显示铭文。 首先,在提交交易中,创建一个 Taproot 输出,该输出承诺包含铭文内容的脚本。 然后,在揭示交易中,提交交易创建的输出被消耗,从而揭示链上的铭文内容。
这种方法大大减少了资源的消耗。 如果不使用P2TR,见证人信息将存储在交易的输出中。 因此,只要该输出不被消耗,见证信息就会继续存储在 UTXO 集中。 相比之下,如果使用P2TR,则见证信息不会出现在提交阶段生成的交易中,因此不会写入UTXO集。 只有当这个 UTXO 被消耗时,见证信息才会出现在揭示阶段的交易输入中。 p2tr 允许将元数据写入比特币区块链,但永远不会出现在 UTXO 集中。 由于维护/修改UTXO集需要更多资源,因此这种方法节省了大量资源。
3.4 铭文
Ordinals 协议利用 SegWit 放宽写入比特币网络内容的大小限制的优势,将铭文内容存储在见证数据中。 Taproot 使得在比特币交易中存储任意见证数据变得更加容易,允许 Ordinals 开发人员 Casey Rodarmor 重用旧的操作码(OP_FALSE、OP_IF、OP_PUSH)作为他所描述的“信封”,以存储所谓的“铭文”的任意数据。
铸造铭文的过程包括以下两个步骤:
首先,需要创建包含已提交交易中铭文内容的脚本的 Commit-to-Taproot 输出。 存储的格式为Taproot,即前一笔交易的输出为P2TR(Pay-To-Taproot),后一笔交易的输入,特定格式嵌入在见证的Taproot脚本中; 首先,将字符串 ord 放入堆栈中,以消除铭文的歧义,避免其有其他用途。 OP_PUSH 1 表示下一次推送包含内容类型,OP_PUSH 0 表示后续数据推送包含内容本身。 大型铭文必须使用多次数据推送,因为 Taproot 的少数限制之一是单个数据推送不得大于 520 字节。 此时,铭文的数据已经对应了交易输出的UTXO,但尚未公开。
OP_FALSE
OP_IF
OP_PUSH "ord"
OP_PUSH 1
OP_PUSH "text/plain;charset=utf-8"
OP_PUSH 0
OP_PUSH "Hello, world!"
OP_ENDIF其次,有必要消耗通过在揭示交易中提交交易而创建的输出。 在此阶段,通过将与该铭文相对应的 UTXO 作为输入来启动交易。 至此,其对应铭文的内容就公开给全网了。
通过上述两个步骤,铭文内容已经与被铭文的UTXO绑定了。 再次,根据上述聪的定位,对其输入UTXO对应的第一个聪进行铭文,铭文内容包含在显示交易的输入中。 根据上面对聪的流向和追踪的介绍,这个刻有特殊内容的聪可以被转移、购买、出售、丢失和恢复。 需要注意的是,铭文不能重复,否则后面的铭文无效。
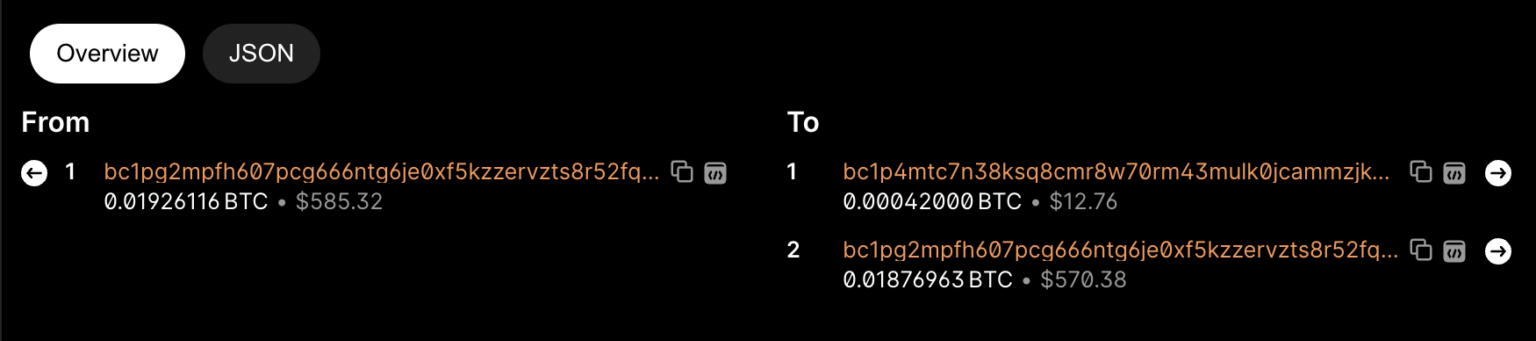
我们将通过一个小型 BTC NFT 图像的示例来详细说明这个过程,该图像由前面提到的两个主要阶段组成:提交和揭示。 首先,我们看到第一笔交易的哈希ID是2ddf9…f585c。 可以注意到,该交易的输出不包含见证数据,网页中也没有相关铭文。
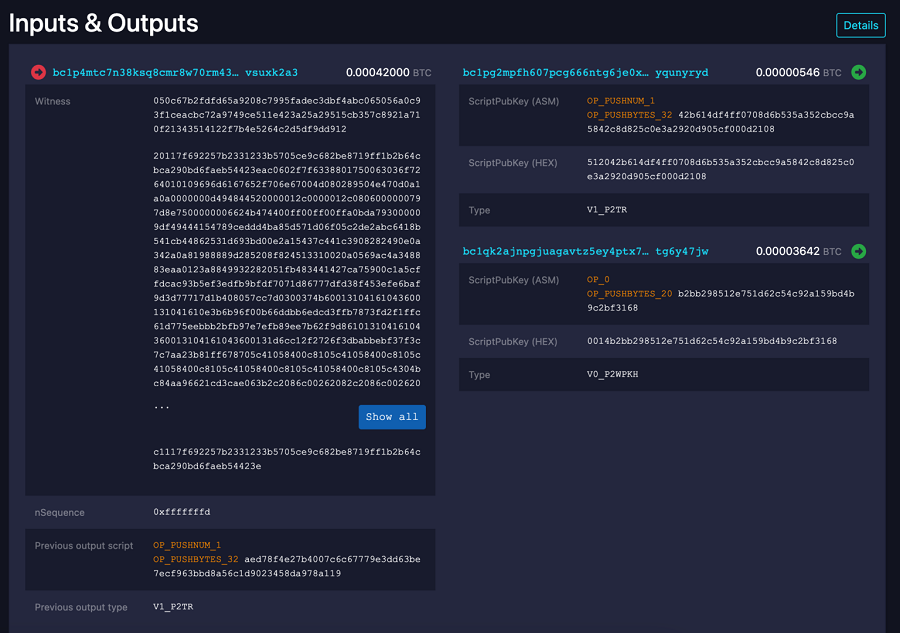
接下来我们看第二阶段的记录,其Hash ID为e7454…7c0e1。 这里我们可以看到Ordinals铭文的信息,也就是见证人铭文的内容。 这笔交易的输入地址是前一笔交易的输出地址,而0.00000546BTC(546 Satoshi)的输出则将这笔NFT发送到自己的地址。 此外,我们还可以找到该铭文所在的 Satoshi,Sat 1893640468329373。
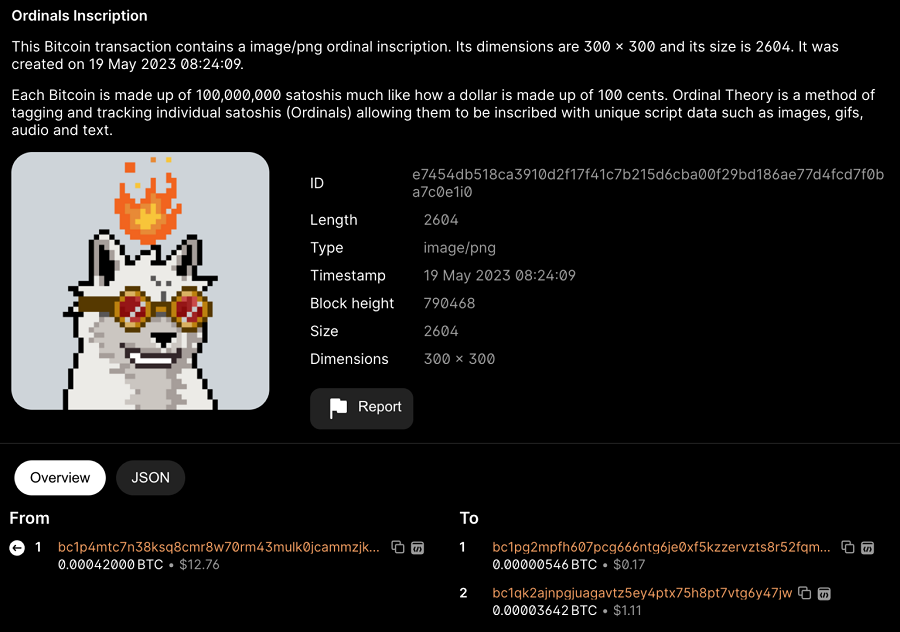
在比特币钱包中,我们可以看到这个资产。 如果我们想要交易这个NFT,我们可以直接将其发送到别人的地址,也就是说发送这个UTXO,这样就完成了铭文的流程。
4、比特币钱包
当我们了解了Ordinals是什么、聪的流向以及铭文的知识后,目前正在涌现出很多应用场景,比如BRC-20、ORC-20、BRC-721、GBRC-721等相关衍生协议。 要求我们有相应的钱包来支持并展示出代币信息或者NFT小图片。 本节我们将介绍不同比特币钱包地址的概念和特点。
比特币地址以 1、3 或 bc1 开头。 就像电子邮件地址一样,它们可以与其他比特币用户共享,他们可以使用它们将比特币直接发送到他们的钱包。 从安全角度来看,比特币地址不包含任何敏感内容。 它可以在任何地方发布,而不会影响帐户的安全。 与电子邮件地址不同,我们可以根据需要经常创建新地址,所有这些地址都会将资金直接存入您的钱包。 事实上,许多现代钱包会自动为每笔交易创建一个新地址,以最大限度地保护隐私。 钱包只是地址和解锁其中资金的密钥的集合。 首先我们需要知道比特币钱包的地址是如何创建的。
4.1 比特币私钥和公钥
比特币使用椭圆曲线Secp256k1,其中“私钥”是1到n-1之间的随机数,n是一个非常大的数(256位),n用科学计数法表示约为1.15792*10^77。 这个范围是如此之大,以至于几乎不可能猜出其他人的私钥。 这个随机整数私钥可以用 256 位表示,并且有多种编码方式。 如果WIF、WIF压缩形式的私钥未加密,则可以对其进行解码以获得原始的“随机整数”。 另一种方式是BIP38,它提出使用AES算法对私钥进行加密。 通过该方案获得的私钥以字符6P开头,而这个私钥必须作为密码输入才能导入到各种比特币钱包中,这就是我们通常使用的私钥。
然后我们将使用椭圆曲线公式 K = kG 从私钥 k 生成比特币的公钥 K。 G是基点,是secp256k1的参数。 K的两个坐标就是公钥的两种表达方式,分别是“未压缩格式”和“压缩格式”。
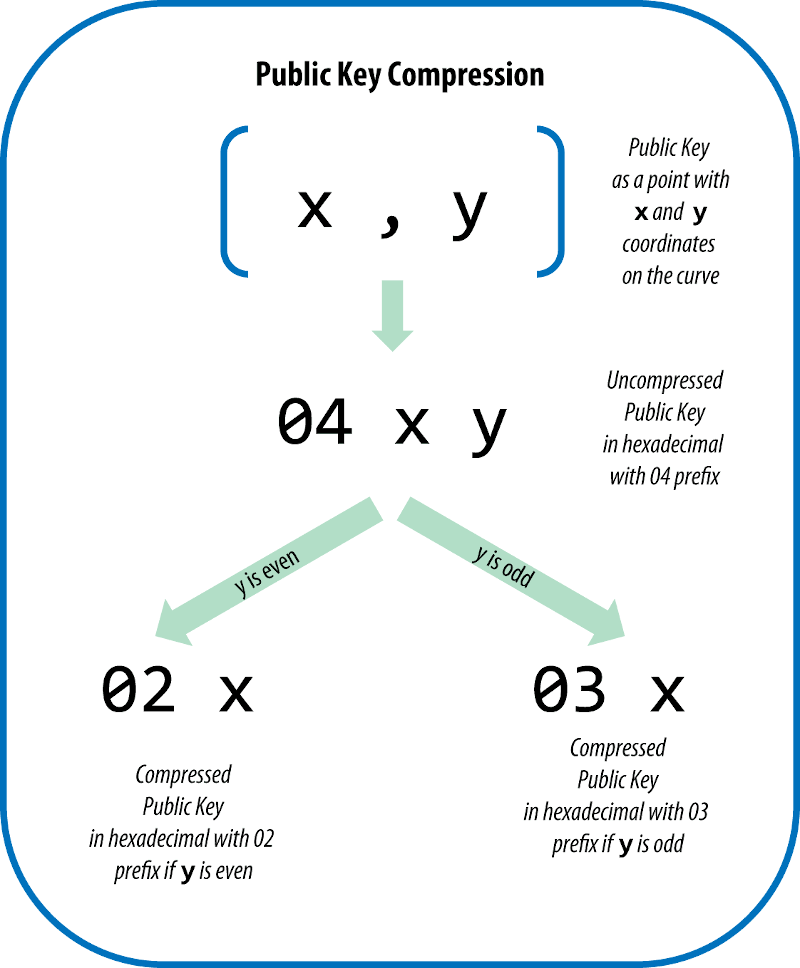
- 未压缩,是两个坐标 x 和 y 的直接串联,前面带有 0x04 前缀;
- 压缩形式,当y为偶数时编码为02 x,当y为奇数时编码为03 x;
4.2 比特币地址
各种类型的比特币地址可以如下图所示,有四种表示形式:
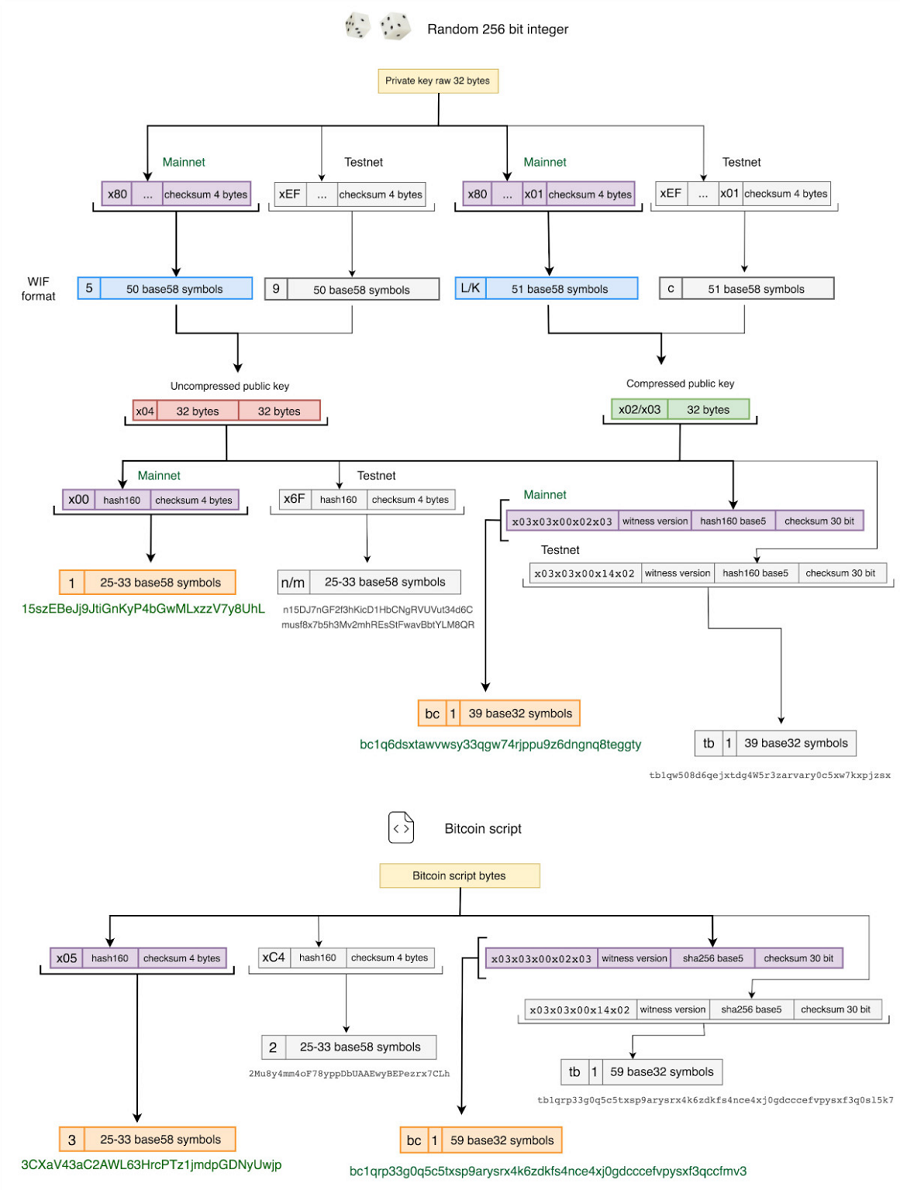
- 旧版 (P2PKH) 格式
示例:1Fh7ajXabJBpZPZw8bjD3QU4CuQ3pRty9u
该地址以“1”开头,是比特币的原始地址格式,至今仍在使用。 也称为P2PKH,全称Pay To PubKey Hash,是通过哈希计算公钥而获得的。
- 嵌套隔离见证(P2SH)格式
示例:3KF9nXowQ4asSGxRRzeiTpDjMuwM2nypAN
嵌套 P2SH,它采用现有的 P2SH 地址(以“3”开头)并用 SegWit 地址包装它。
- 原生SegWit (Bech32) 格式
示例:bc1qf3uwcxaz779nxedw0wry89v9cjh9w2xylnmqc3
BIP0173 中提出了以 bc1 开头的地址,它们是本机隔离见证地址。 bech32编码地址,一种专门为SegWit开发的地址格式。 bech32 于 2017 年底在 BIP173 中定义,该格式的主要特征之一是它不区分大小写(地址中仅包含 0-9、az),使其有效避免 输入时混乱且更具可读性。 由于地址中需要的字符较少,因此地址使用 Base32 而不是传统的 Base58 进行编码,使计算更容易、更高效。 数据可以更紧密地存储在二维码中。 bech32 提供更高的安全性、更好的校验和和错误检测代码优化,并最大限度地减少无效地址的机会。
Bech32 地址本身与 SegWit 兼容。 将 SegWit 地址放入 P2SH 地址不需要额外的空间,因此 Bech32 格式地址的费用较低。 Bech32 地址比旧的 Base58 地址(Base58Check 编码用于将比特币中的字节数组编码为人类可编码的字符串)地址有几个优点:更小的 QR 码; 更好的防错能力; 更安全; 不区分大小写; 仅由小写字母组成,因此更易于阅读、键入和理解。
- Taproot格式(P2TR)
Bech32 有一个缺点:如果地址的最后一个字符是 p,则在 p 之前插入或删除任意数量的字符 q 不会使其校验和无效。
为了缓解Bech32的这个缺点,BIP0350中提出了Bech32m地址:
- 对于版本0的原生隔离见证地址,使用之前的Bech32;
- 对于版本 1(或更高版本)本机隔离见证地址,使用新的 Bech32m。
对于 Bech32m 地址,当使用版本 1 时,它们始终以 bc1p(即 Taproot 地址)开头。 具体来说,就像本地隔离见证一样,钱包可以由种子短语和加密短语组成。 它们用于生成扩展的公钥和私钥,这些密钥用于派生分层确定性钱包中的任意路径地址。 主要用途是存储BRC-20以及BTC的NFT等。
DefiPlot翻译整理,转载请标明出处
免责声明:本站资源仅用于学习目的,也不应被视为投资建议,读者在采取任何行动之前应自行研究并对自己的决定承担全部责任。