Hyperliquid预编译和CoreWriter
本文旨在提供一个更深入的指南,说明HyperEVM和HyperCore如何相互作用——既帮助开发者了解如何有效地编写代码,也给审计人员提供一个清晰的框架来识别潜在风险。

一键发币: x402兼容 | Aptos | X Layer | SUI | SOL | BNB | ETH | BASE | ARB | OP | Polygon | Avalanche
当我第一次写关于Hyperliquid预编译的文章时,技术栈还处于早期阶段——功能有限,仅在测试网上可用以获取反馈。自那篇文章以来,感觉时间过得很快,发生了许多变化。现在我们有了新的术语、更详细的官方文档、主网部署、扩展的功能、不断增长的开发者社区,最重要的是,现在有协议完全在其上运行。
本文旨在提供一个更深入的指南,说明HyperEVM和HyperCore如何相互作用——既帮助开发者了解如何有效地编写代码,也给审计人员提供一个清晰的框架来识别潜在风险。
本文会故意重复一些原始文章的内容,这样读者就不需要再参考现在已过时的资源了。与任何快速发展的堆栈一样,这里的一些细节可能不完全正确,如果发现错误,我们会相应地进行更新。
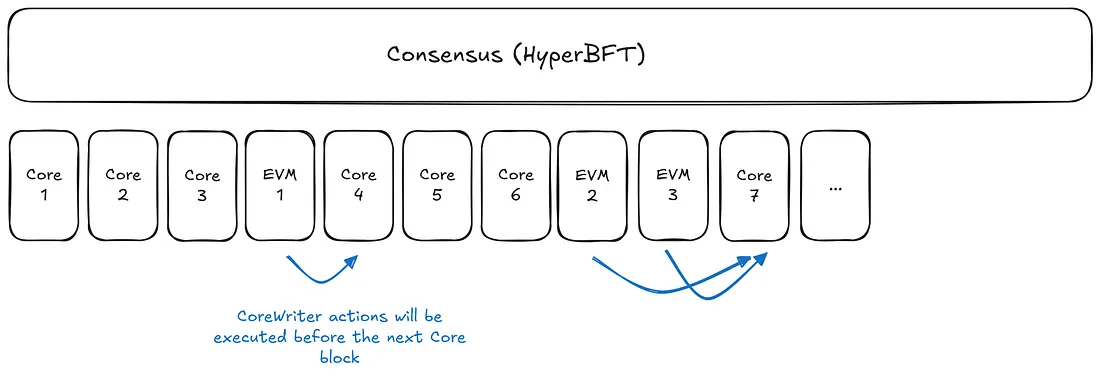
1、块序列
从概念上讲,Hyperliquid栈围绕两种不同的块类型构建:Core块和EVM块。在EVM类别中,实际上有两种不同的形式——小块和大块。
Core块以非常快的间隔生成——在写作时,大约每秒有12个块。这些块执行一组固定的、定义明确的交易,例如创建限价单、向金库存款或将质押委托给验证者等。
EVM块则不同,它们是通用的。在EVM块中可以实现的功能仅受该块的gas容量限制,因此它们是复杂智能合约逻辑和更灵活应用程序的自然家园。
建立正确的心理模型非常重要。关键点是,Core块和EVM块在独立的执行环境中按顺序运行,但遵循相同的共识机制并共享相同的全局状态。
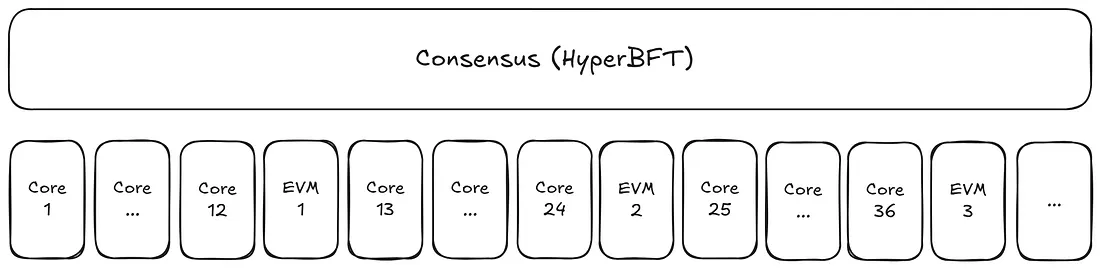
实际上,它们甚至不是真正独立的块——尽管为了清晰起见我们这样描述。随着我们深入探讨,这种区别会变得更加清晰,架构背后的理由也会更加直观。
2、双EVM块架构
这引出了Hyperliquid中最独特的设计选择之一:双EVM块架构。
双块架构的主要动机是解耦块速度和块大小,在分配吞吐量改进时。用户希望更快的块以获得更低的确认时间。开发者希望更大的块以包含更大的交易,如更复杂的合同部署。而不是强制性的权衡,双块系统将允许同时在这两个轴上取得进步。
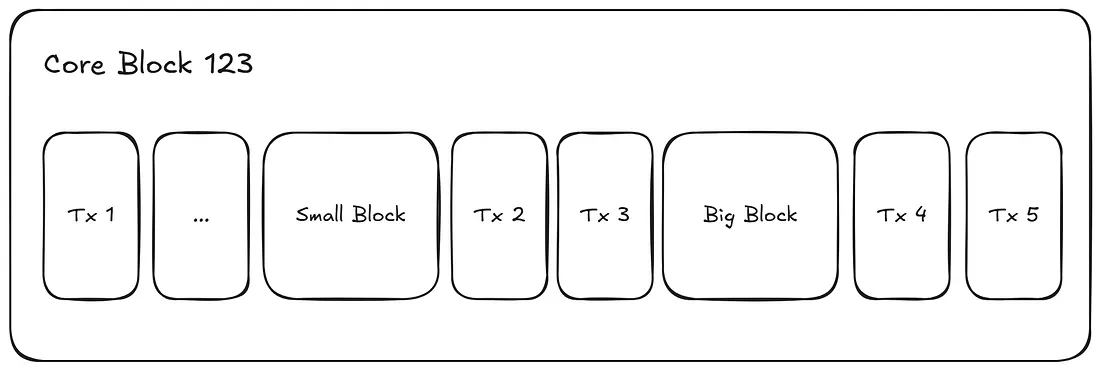
小EVM块每1秒生成一次,每个块的gas限制为200万,而大EVM块每60秒生成一次,每个块的gas限制为3000万。这意味着链保持了小块的快速节奏,同时定期提供大块的大容量。
另一个需要注意的重要特征是,由于60秒的间隔也落在1秒的边界上,每当生成一个大块时,会在它之前生成一个小块。
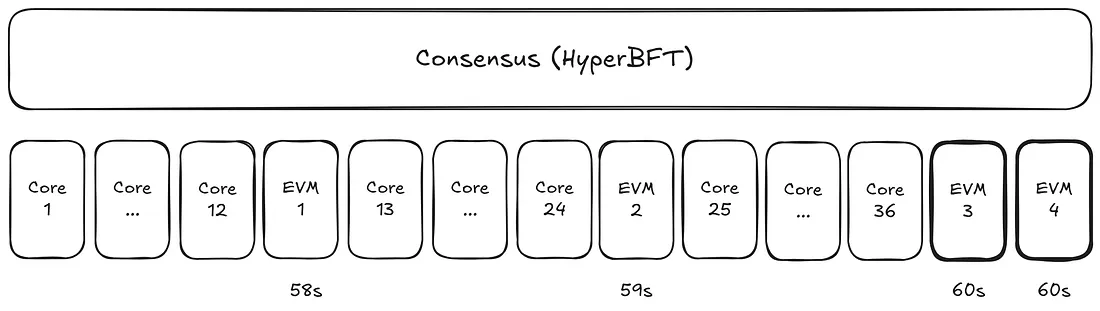
大块和小块将具有相同的block.timestamp,但block number会增加。
3、块中的块
从概念上讲,这些块是分开的,并按顺序生成。但实际上,EVM块是在Core块的范围内生成的,并且只有在Core交易完成之后才会执行。
这个微妙的细节至关重要:它解释了预编译和CoreWriter是如何融入画面的,以及在块生成过程中状态是如何被读取和写入的。
如果我们能查看一个Core块内部,它看起来会像这样。
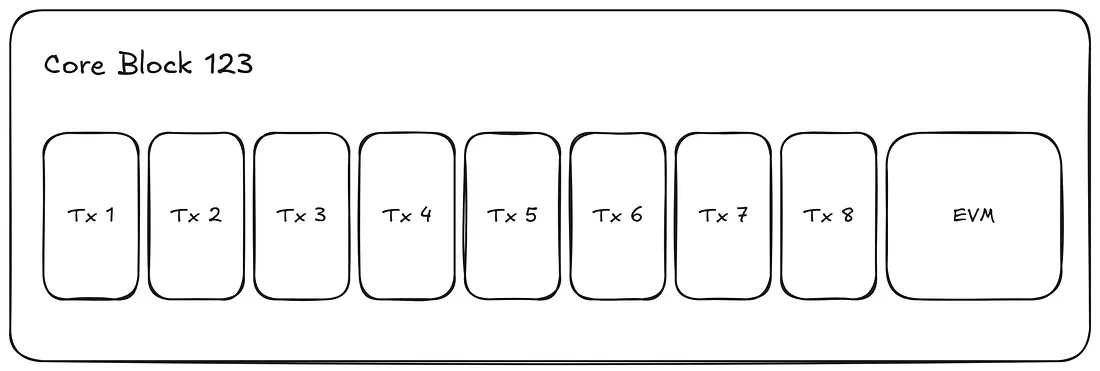
正如预期的那样,当同时生成一个小块和一个大块时,它们将在同一个Core块内生成。请注意,小块总是在大块之前生成。
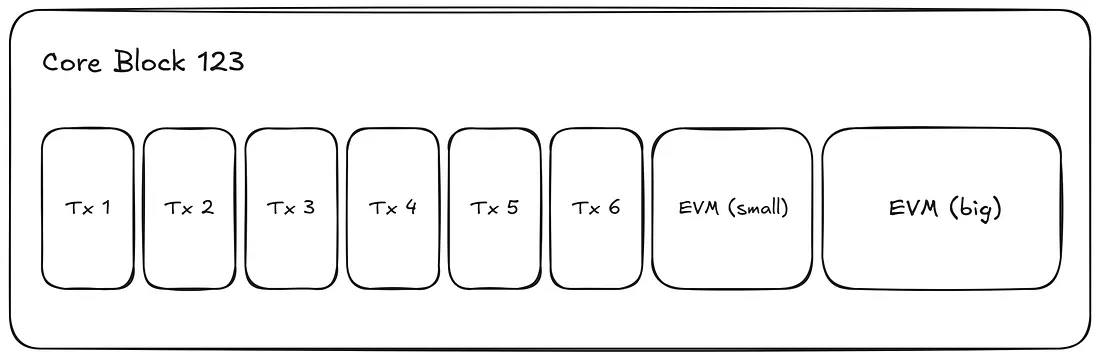
4、预编译
预编译合约,通常简称为Precompiles,为以太坊虚拟机(EVM)实现提供了一种访问原生函数的方式。它们的行为类似于智能合约,并且有一个众所周知的地址,然而,相似之处到此为止。当调用Precompiles时会发生什么,完全取决于EVM实现。
让我们看看这个例子,如何读取L1上的用户永续仓位。
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.0;
contract PositionReader {
address constant PRECOMPILE_ADDRESS = 0x0000000000000000000000000000000000000800;
struct Position {
int64 szi;
uint32 leverage;
uint64 entryNtl;
}
function readPosition(address user, uint16 perp) external view returns (Position memory) {
(bool success, bytes memory result) = PRECOMPILE_ADDRESS.staticcall(abi.encode(user, perp));
require(success, "readPosition call failed");
return abi.decode(result, (Position));
}
}
现在,任何智能合约都可以轻松读取永续仓位,并且由于块按顺序执行,可以保证读取的值是最新的。
让我们从概念上看看这一点。
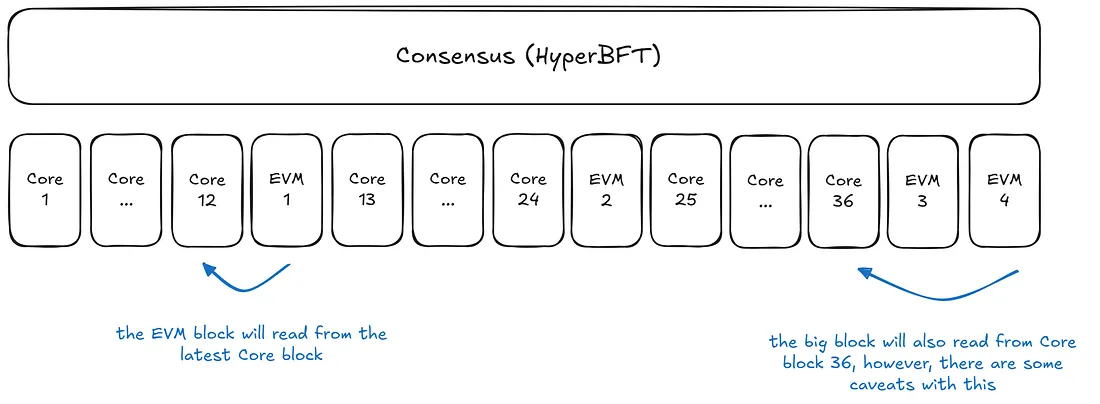
如图所示,每当一个EVM块被生成时,Precompiles总是从最新的Core块状态读取——换句话说,就是它们所在的Core块的状态。这个规则适用于小块和大块,确保所有Precompile读取都基于最新的Core状态。
特殊情况是,虽然大块从它所在的Core块读取,但它访问的状态可能已经由前面的小块执行所改变。这将在后面详细讨论。
一个重要区别是,Precompiles总是从当前状态读取,而EVM块并不严格绑定到它生成的Core块。相反,每当EVM调用一个Precompile时,它总是从当前的Core状态读取。
这是另一个需要理解的关键点,当用具体的例子来说明时会更加清晰。
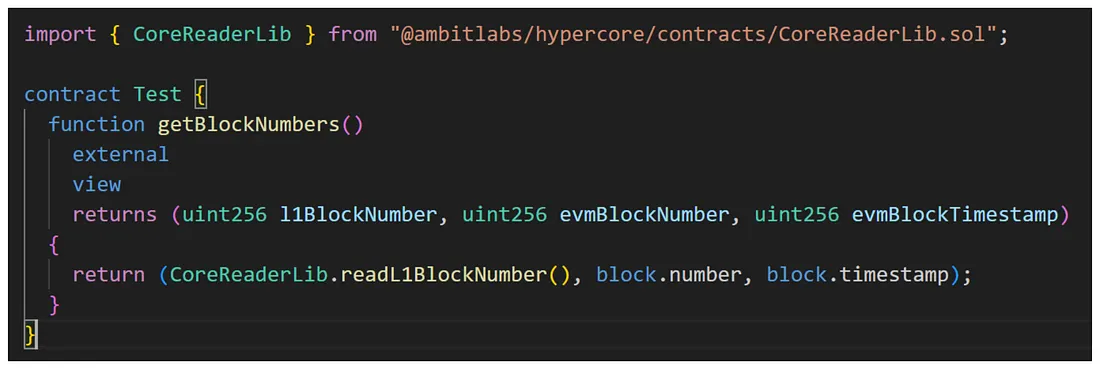
这里有一个基本的合约,返回当前L1/Core块号以及EVM块号和时间戳。
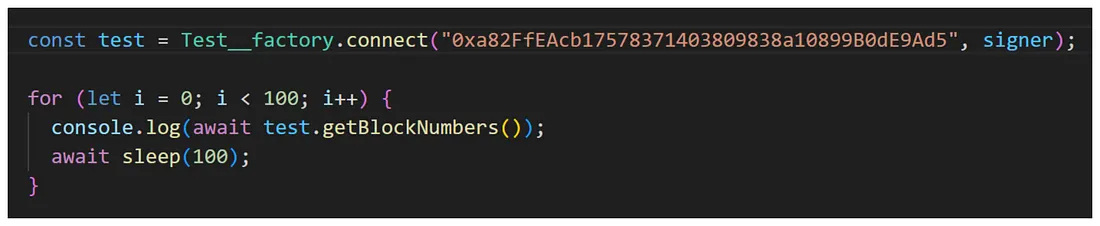
现在我们可以重复调用它,这应该允许在块之间多次调用。
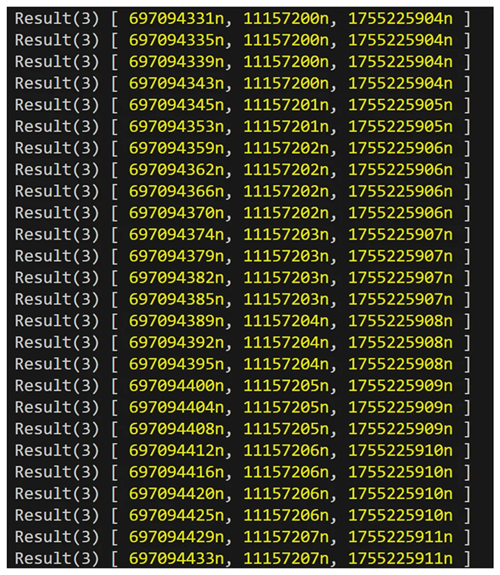
从下面的输出中可以看出,每次调用时L1块号都会增加,而EVM块号和时间戳只在新块被挖出时才前进。这表明EVM始终访问最新的Core块,即使Core块是在EVM块之后生成的。
5、CoreWriter
CoreWriter使HyperEVM上的智能合约可以直接在HyperCore上创建交易。这种机制既简单又强大。
CoreWriter部署在一个众所周知的固定地址(0x333…333)上,并提供了以下接口供交互使用。

当查看CoreWriter的实现时,这变得更有意思。

CoreWriter的实现本身是有意最小化的。它除了发出RawAction事件外几乎不做其他事情,但这种行为提供了对其内部设计的关键洞察。
5.1 CoreWriter的基础是什么?
首先,通过调整我们的心理模型,考虑块的序列是有帮助的。当生成一个EVM块时,该块中包含的任何CoreWriter操作在随后的Core块中可见,但有几个值得注意的例外情况。
进一步深入,让我们看看在EVM块中概念上是怎样的。
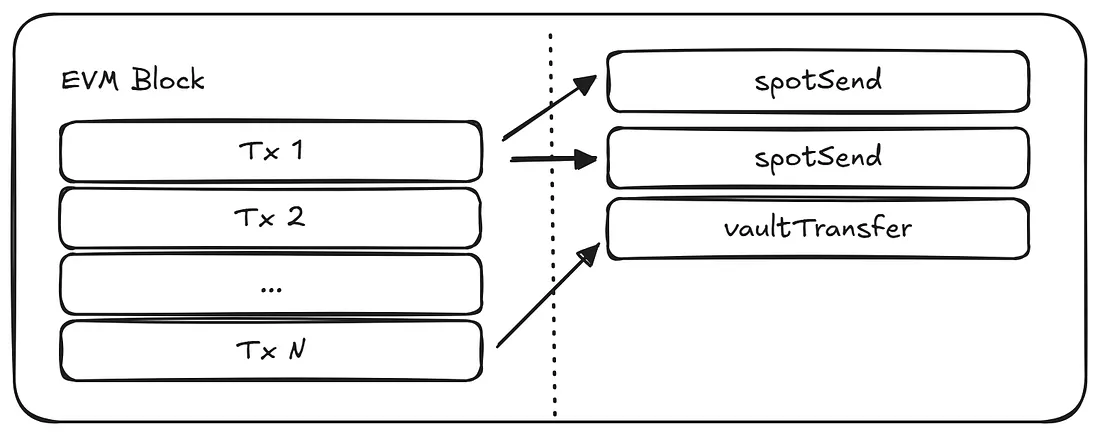
当EVM块中的交易调用CoreWriter时,产生的操作不会立即执行。相反,这些操作会被排队,并在EVM块最终确定后处理。节点观察发出的日志事件,并将它们添加到队列中以供后续执行。
我们现在可以推断出概念上如下所示。
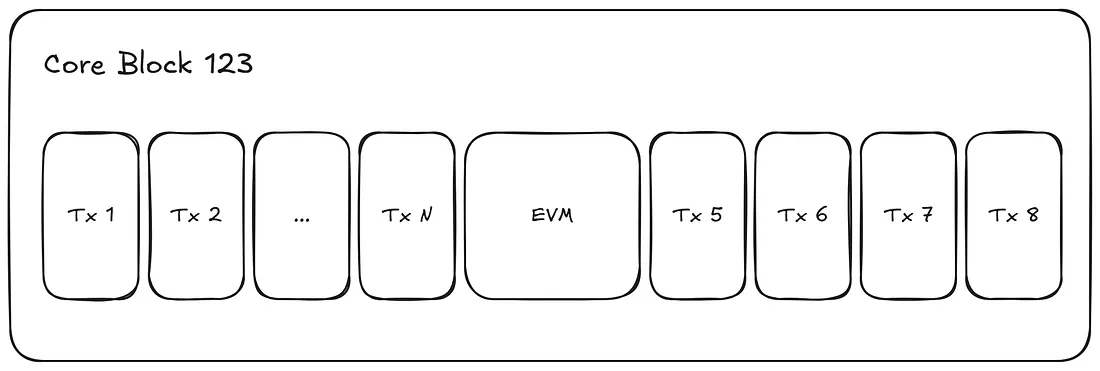
一旦EVM块最终确定,排队的CoreWriter操作就会被执行,全部在原始Core块的范围内。这确保了EVM执行和Core状态之间的关系保持一致和确定性。
在同时生成大块和小块的情况下,小块中引发的CoreWriter操作会先执行,然后是大块及其包含的任何CoreWriter操作。如前所述,这意味着大块内的Precompile调用不一定从初始的Core块状态读取,因为该状态可能已经被小块中执行的CoreWriter操作所改变。
对于一般的执行模型有一些显著的例外情况,特别是订单操作和金库转账。与标准的CoreWriter操作不同,这些操作并不是在它们被引发的同一个Core块中执行的。相反,它们在链上被有意延迟一段时间后再处理。这种设计选择防止了HyperEVM绕过L1内存池可能带来的潜在延迟优势。
在操作被延迟的情况下,只有操作本身被推迟,而不是由此产生的交易。这种区别可以通过金库转账的例子来说明。
假设一个账户在其永续余额中有100美元。CoreWriter操作被引发以将这100美元转入金库。在下一个EVM块期间,该账户的永续余额仍将显示为100美元,因为该操作尚未转换为交易。然而,稍后,该操作会被转换为Core交易,并将资金存入金库。
这种延迟引入了冲突操作的可能性。例如,在随后的EVM块中,另一个CoreWriter操作可能会被执行,以将同样的100美元从永续余额转移到现货余额。当延迟的金库转账被处理时,永续余额可能不再有足够的资金,导致金库转账失败。
总结一下,这里的理解是,操作是意图,而不是即时的状态更改。
5.2 原子性和缺乏原子性
在区块链交易的上下文中,原子性是指保留区块链状态的完整性。如果交易中的某部分失败,则整个交易将回滚,就像从未执行过一样。原子性也是开发人员的强大工具,因为它消除了处理可能部分成功的操作时存在的复杂性。
通过CoreWriter获得的原子性仅限于保证一旦你引发一个操作,它将被排队等待处理。然而,你无法保证该操作本身一定会成功。例如,如果你通过CoreWriter提交一个现货订单,而该订单最终未能成交,那么失败不会回滚原始的EVM交易。
这一点对智能合约开发人员来说很重要,因为这意味着在某些情况下,你在链上期望的状态可能与最终的Core结果不匹配。这并不意味着系统不可靠,但意味着你需要在设计中考虑到这些细微差别。幸运的是,有成熟的设计模式可以帮助你在这种模型中安全地构建——你只需更仔细地思考如何构建你的解决方案,使其在Core操作没有完全按照预期解决时仍然稳健。
6、资产转移
在HyperCore和HyperEVM之间转移资产是一种不同的交互类型。虽然在加密货币中这通常被称为“桥接”,但实际上它并不是一座桥。相反,它只是在单个Core块范围内执行的一系列状态更新,同步EVM状态到Core状态。
有了对块存在方式的新认识,资产转移就更容易理解了,因为这是一个类似的过程。
从用户的HyperEVM账户向该代币关联的系统地址(如官方文档中详细描述的)进行标准ERC-20转账,将减少HyperEVM上的余额,然后将用户的现货余额在HyperCore上增加。
就像节点观察来自CoreWriter的RawAction事件一样,它也会监控所有相关代币的系统地址发出的ERC-20 Transfer事件。这些Transfer事件以与CoreWriter操作相同的方式排队。
当EVM块执行完成后,处理顺序是确定的:
- 首先,所有排队的Transfer事件都会被应用,将EVM中的余额更新到Core中。
- 然后,任何待处理的CoreWriter操作都会被执行。
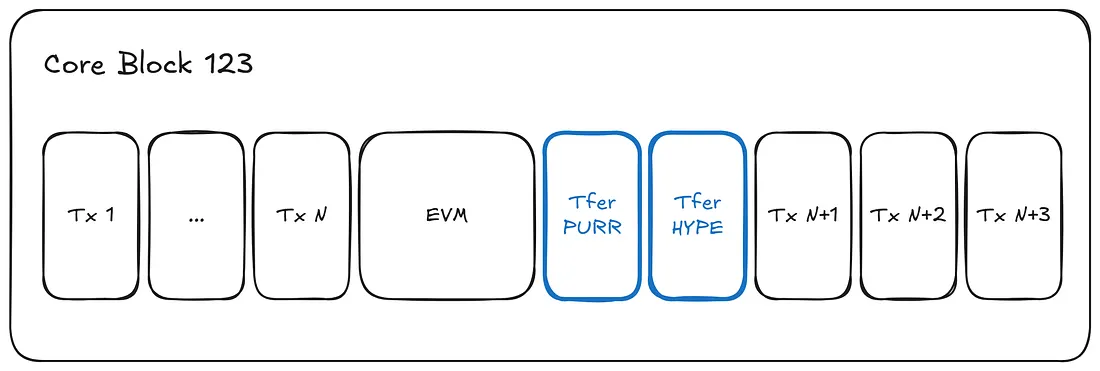
6.1 HYPE的特殊情况
当发送HYPE时,它是HyperEVM的原生gas代币,该交易不会生成任何标准的事件日志,因为它是一个基本交易。为了解决这个问题,HyperEVM使用了一个专用的系统地址:0x2222222222222222222222222222222222222222.
该合约公开了一个payable函数,当被调用时,会发出一个Receive事件。该事件作为ERC-20 Transfer日志的替代品,确保节点有一个一致的信号来跟踪价值从EVM进入Core。
除了这个事件处理的变通方法外,流程与其他资产转移完全相同。
这种设计的一个重要特性是,从HyperEVM到HyperCore的转账保证在下一个Core块中完成。换句话说,一旦EVM块完成,排队的转账事件总是在同一个Core块中处理。
6.2 反方向
我们迄今为止描述的大多数交互都是从HyperEVM到HyperCore。但是,资产转移也可以从HyperCore返回到EVM。
当通过HyperCore的Spot Send操作发送资产时,该转账首先在Core中排队,直到下一个EVM块生成。此时,排队的Spot Send转账会在EVM块本身处理之前执行。内部这只是一个对代币原生transfer方法的调用,这意味着从HyperCore发起的转账在EVM上看起来与任何其他代币转账完全相同。这种设计保持了两个系统之间的平衡同步,并确保了合约和索引器可以同样可靠地跟踪来自Core的转账。
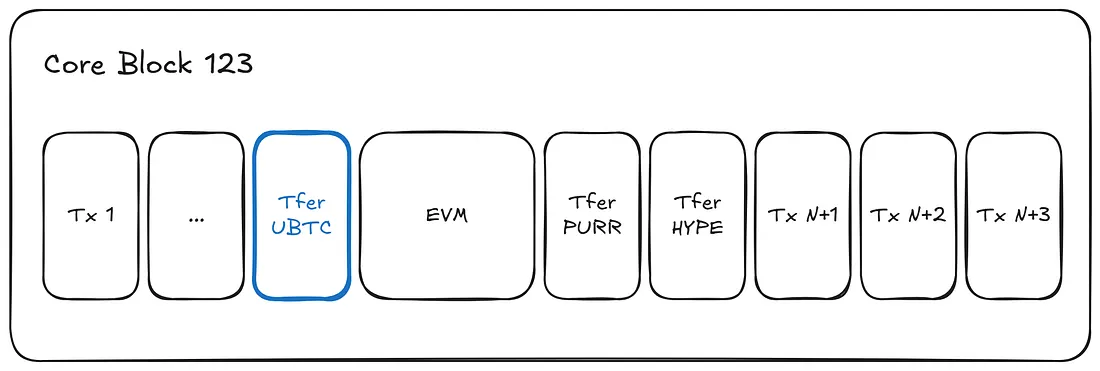
6.3 这很好,但为什么我的资产消失了?
正如我们所看到的,将资产在HyperEVM和HyperCore之间转移可能看起来像是一座桥,但实际上它是一种确定性和可靠的状态转移。这引发了一个重要的问题:为什么有时似乎你的资产消失了?答案是它们从未真正消失。发生的情况是,在转移开始但未在另一端最终确定的短暂时刻,这些资产无法在系统中完全被计算。
让我们用一个例子来简化这个问题。
考虑这样一个案例:一个智能合约将其HyperEVM余额中的1 BTC发送到该代币关联的系统地址(0x200…00N)。此时,智能合约的余额不再显示1 BTC,而是系统地址显示增加了余额。由于这是一个共享地址,无法确定该余额中有多少具体来自于该合约。这是预期的行为,就像任何其他ERC-20转账一样。
然而,正如我们已经看到的,代币转账在EVM块完成之后才会被处理到Core状态。这意味着如果在同一EVM块中——无论是同一笔交易还是后续的交易——你通过预编译查询现货余额,1 BTC的更新将不会出现。资产并没有丢失,但在这一短暂窗口内,它们无法直接被计算,因为它们正在排队等待结算到Core。
简单的解决方案是内部跟踪这些资产,并将它们与L1块号关联。


7、结束语
通过使用Precompiles和CoreWriter,Hyperliquid团队提供了一种方式,使得运行在HyperEVM上的智能合约可以读取状态并与HyperCore进行交互,从而为智能合约提供对L1上永续和现货流动性访问。想象一下,如果Binance允许智能合约开发者在其订单簿上部署……这就是Hyperliquid所实现的。这将启用新的DeFi基础结构和策略,并完全在链上运行。
原文链接:Demystifying the Hyperliquid Precompiles and CoreWriter
DefiPlot翻译整理,转载请标明出处
免责声明:本站资源仅用于学习目的,也不应被视为投资建议,读者在采取任何行动之前应自行研究并对自己的决定承担全部责任。


