高频交易:零延迟的竞赛
高频交易系统并不是为毫秒设计的——它们是针对微秒,甚至纳秒进行调优的。从网卡到FPGA位流的每个组件都专注于一个目标:将延迟降到最低。

当人们谈到高频交易(HFT)时,他们通常会想象黑箱算法在毫秒内赚取数百万美元。现实呢?它更加极端。
这些系统并不是为毫秒设计的——它们是针对微秒,甚至纳秒进行调优的。从网卡到FPGA位流的每个组件都专注于一个目标:将延迟降到最低。
在这次深入探讨中,我们将揭开一个真实世界HFT架构的层次——你可以在与纳斯达克或纽约证券交易所匹配引擎相邻的公司中找到这种架构。你将看到原始市场数据是如何被接收的,内存中的订单簿是如何工作的,基于FPGA的策略如何在纳秒内触发,以及智能订单路由器如何确保交易比人类感知更快地到达线路上。
让我们开始吧。
1、为什么速度统治市场
从根本上说,HFT是利用机器以超高速交易金融工具(股票、期货、期权)的技术。
这些系统每秒可以执行数千到数百万次交易,通常每次交易只赚取几分钱。优势不在于交易什么,而在于反应有多快。
一次毫秒级的延迟可能意味着盈利和亏损之间的区别。如果你的系统看到市场变动并比竞争对手慢100微秒反应,那么你已经出局了。
这就是为什么这些系统被设计成像一级方程式赛车一样——每一个指令路径、时钟周期和数据包遍历都至关重要。
2、市场数据摄入——消防水带
一切始于市场数据——来自纳斯达克或纽约证券交易所等交易所的实时报价、交易和订单簿更新。
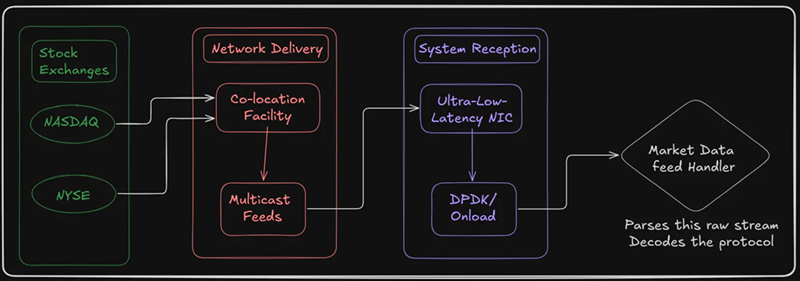
但忘记REST API或WebSocket数据流。高频交易公司使用多播数据流通过超低延迟光纤传输,通常位于靠近交易所服务器的机房设施中。
链中的第一个组件是超低延迟的网卡(Network Interface Card),能够在亚微秒时间内处理数据包。Solarflare或Mellanox ConnectX等型号在这里很常见。
这些网卡通常使用内核绕行框架,如:
- DPDK (Data Plane Development Kit)
- Solarflare Onload
- RDMA (Remote Direct Memory Access)
目标很简单:完全跳过操作系统网络栈。中断、上下文切换和系统调用是延迟的毒药。你希望数据包直接从网线流向用户空间缓冲区,时间在微秒级别。
一旦数据包到达,市场数据处理程序接管工作——解码二进制协议如ITCH、OUCH或FIX/FAST,并将其转换为系统理解的内部结构。
这必须以每秒数百万次的速度发生——且不能丢弃任何数据包。
3、内存中的订单簿
解码后,更新被输入到订单簿中,这是当前市场深度(买入价、卖出价和数量)的内存模型。
高频交易系统将此订单簿完全存储在RAM中——没有数据库,没有磁盘I/O,也没有锁定。
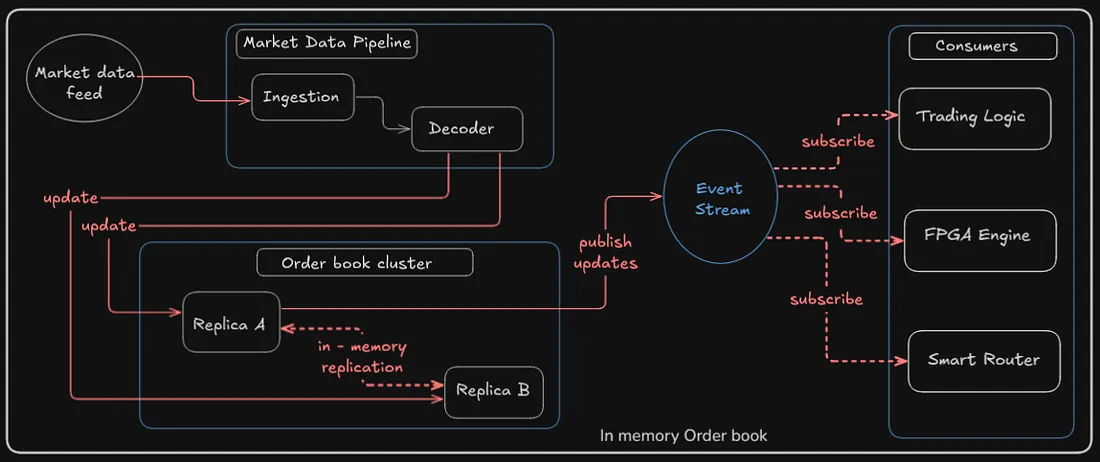
每次价格水平更新都会触发轻量级的内存修改,通常使用无锁环形缓冲区或缓存感知跳表实现。
为了冗余,公司使用内存复制的订单簿(Replica A, Replica B),以便在某个进程停滞时无缝切换。
订单簿不仅仅是数据结构——它是整个交易堆栈的心跳。每一次交易决策、每一次风险检查、每一次FPGA信号都源于这个状态。
4、事件驱动架构和纳秒时钟
一旦订单簿更新,系统就会向无锁事件队列发出事件,通常使用高性能结构如LMAX Disruptor或自定义环形缓冲区实现,以降低竞争。
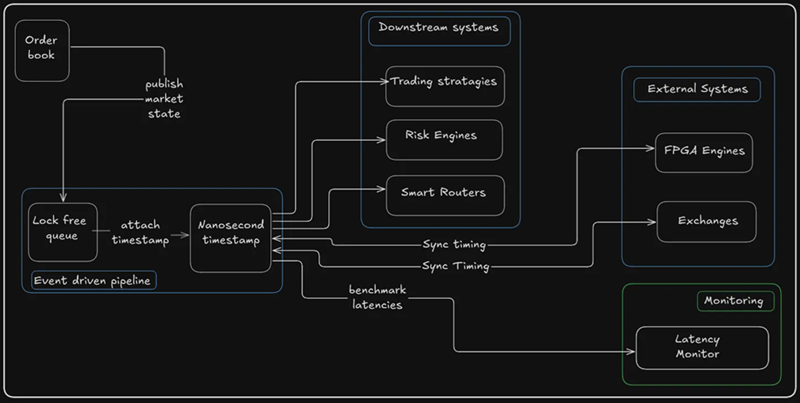
每个事件——价格变化、订单取消或交易——都会使用PTP同步硬件时钟进行纳秒级精确的时间戳。
为什么如此精确? 因为在HFT中,知道某事何时发生和知道发生了什么一样重要。纳秒时间戳让公司测量组件级延迟、检测抖动,并将内部操作与交易所时间戳精确到线路级别。
5、FPGA加速:硅芯片上的交易
现在进入硬核部分:FPGA(现场可编程门阵列)。
这些芯片允许交易逻辑以硬件速度运行,绕过CPU。它们处理从线路接收到的事件——没有操作系统,没有上下文切换,没有指令解码。想想套利、做市商或代码填充,所有都直接嵌入硅中。

这被称为从tick到交易:从进入的tick到执行交易不到一微秒。
FPGA处理:
- 协议解码
- 订单簿快照
- 策略逻辑(做市商、套利或流动性检测)
- 直接通过低延迟以太网发送订单
它们使用Verilog或VHDL进行编程,每条逻辑路径都必须是确定性的。没有垃圾收集,没有分支陷阱——只有时钟周期和门。参考一下,当CPU线程启动时,FPGA已经评估了机会并发送了一个订单。
一位高级FPGA工程师曾在LinkedIn上说过:
“在软件中,你会进行分析。在FPGA中,你会用手指计算纳秒。”
6、策略引擎:软件与硅的结合
并非每个决定都在硬件中运行。大多数交易逻辑仍然存在于基于软件的策略引擎中,使用C++或Rust编写,有时使用JIT编译组件来实现动态规则。

这些引擎消费事件流,评估当前市场状况,并决定:
- 我们是否应该收紧报价?
- 我们是否应该扩大价差?
- 我们是否应该撤回流动性?
- 我们是否应该跨场所对冲?
这些引擎是为可预测性而构建的,而不是原始吞吐量。 它们必须在有限时间内响应——每一微秒的抖动都很重要。即使是缓存缺失也会被分析并优化掉。
一些公司使用轻量级机器学习——但始终在严格的延迟预算下。TensorFlow模型在这里并不适用;我们说的是手工编写的线性回归或自定义SIMD内核。
7、智能订单路由和预交易风险检查
一旦做出交易决策,就不会盲目地将订单发送到交易所。它会通过智能订单路由器(SOR)。
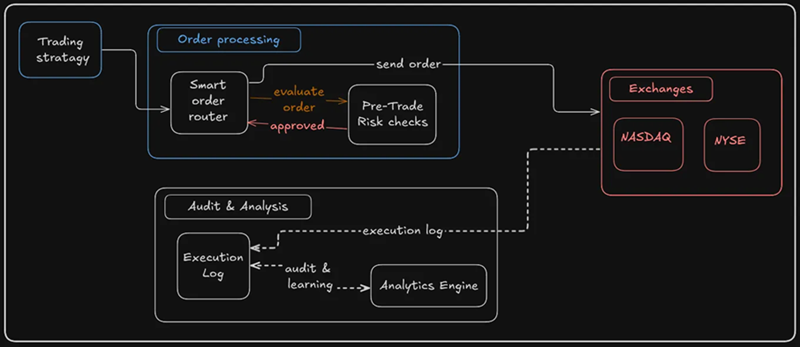
SOR决定将订单发送到哪里——纳斯达克、纽约证券交易所、BATS——根据:
- 每个场所的延迟
- 成交概率
- 流动性深度
- 费用/回扣结构
在任何数据包离开之前,它会经过预交易风险检查——自动逻辑确保仓位限制、名义上限和合理性界限。
这些风险检查发生在微秒级,通常与FPGA流水线并行运行。它们防止“恶意”订单耗尽账户或导致闪崩。
这个检查点确保速度永远不会超越安全。
9、订单管理与监控
交易执行后,交易流入订单管理系统(OMS),跟踪每个订单的生命周期:已发送、已成交、部分成交、已取消、被拒绝。

同时,一个实时监控和遥测堆栈运行,捕获:
- 从tick到交易的延迟
- 队列深度指标
- 系统健康状况
- 错误率
- 网络抖动
这些指标输入到Grafana仪表板和延迟热图中,用于交易后分析、合规性和持续优化。
一位量化工程师曾这样说道:
“如果你不测量延迟,你就是在猜测延迟。”
10、冷酷优化的美
高频交易不仅仅是金融——它是在极端约束下的系统工程。
它涉及推动硅、软件和网络的边界,以在混乱环境中实现确定性的微秒行为。
每一个优化——每一个被跳过的系统调用,每一个缓存对齐的结构——都很重要。
因为在这一游戏中,最快的系统总是赢家。
11、结束语
如果你喜欢系统设计、事件驱动架构或低延迟编程,研究HFT系统就像窥探计算领域的F1车库一样。
它们是数据工程、软硬件协同设计和实时优化的典范。
所以下次你看到一个市场波动时——记住,在它背后是一个硅、代码和物理的小宇宙……它们都在争先恐后地成为第一个。
原文链接:Inside High-Frequency Trading Systems: The Race to Zero Latency
DefiPlot翻译整理,转载请标明出处
免责声明:本站资源仅用于学习目的,也不应被视为投资建议,读者在采取任何行动之前应自行研究并对自己的决定承担全部责任。


