Dencun升级之五:EIP-4844
在 Dencun 升级系列的第五篇也是最后一篇文章中,我们介绍了EIP-4844,也称为“proto-danksharding”,它将大大降低通过“blob”将 L2 汇总数据发布到以太坊主网的成本。

一键发币: SUI | SOL | BNB | ETH | BASE | ARB | OP | POLYGON | 跨链桥/跨链兑换
在 Dencun 升级系列的第五篇也是最后一篇文章中,我们介绍了EIP-4844,也称为“proto-danksharding”,它将大大降低通过“blob”将 L2 汇总数据发布到以太坊主网的成本。
EIP-4844 代表了以太坊以去中心化方式进行扩展的过程中迈出的切实而重要的一步。 更具体地说,它通过引入新的“blob-carrying”交易类型来帮助扩展以太坊。 Rollup 排序器(以及可能的其他排序器)将使用这种新的交易类型以比目前更便宜的价格将数据发布到以太坊主网。 此外,该 EIP 通过确保每个块包含的 blob 的大小和数量受到限制来保持去中心化,从而使以太坊节点的计算和存储需求不会急剧增加。 在未来的升级中,这些限制可以减少,以进一步扩展以太坊。
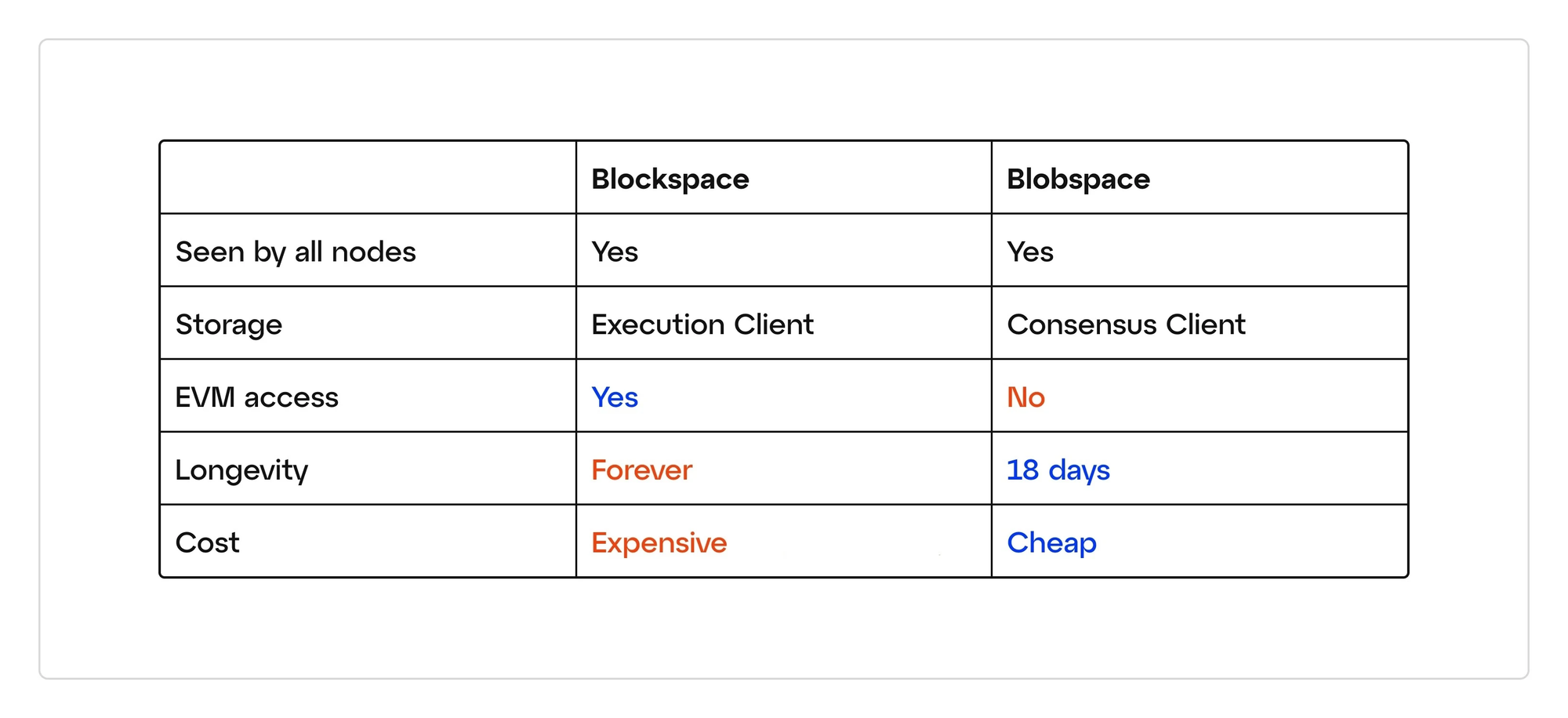
Blob 数据之所以比类似大小的常规以太坊调用数据便宜,是因为 Blob 数据本身实际上无法被以太坊的执行层(EL,又名 EVM)访问。 相反,EL 只能访问对 blob 数据的引用,并且 blob 本身内的数据将仅由以太坊共识层(CL,又名信标节点)下载和存储,并且仅在有限的时间内( 通常约为 18 天)。
通过其携带 blob 的交易格式,EIP-4844 提高了以太坊的可扩展性,保留了去中心化,最重要的是,为未来实施更复杂、更有影响力的可扩展性升级奠定了基础; 即完整的 Danksharding。
1、什么是 Blob?
在深入探讨以太坊社区如何达成 EIP-4844 或原始 danksharding(作为扩展以太坊的逻辑下一步)之前,我们将首先扩展此 EIP 引入的主要功能 - 携带 blob 的交易(以及 blob 本身) 。
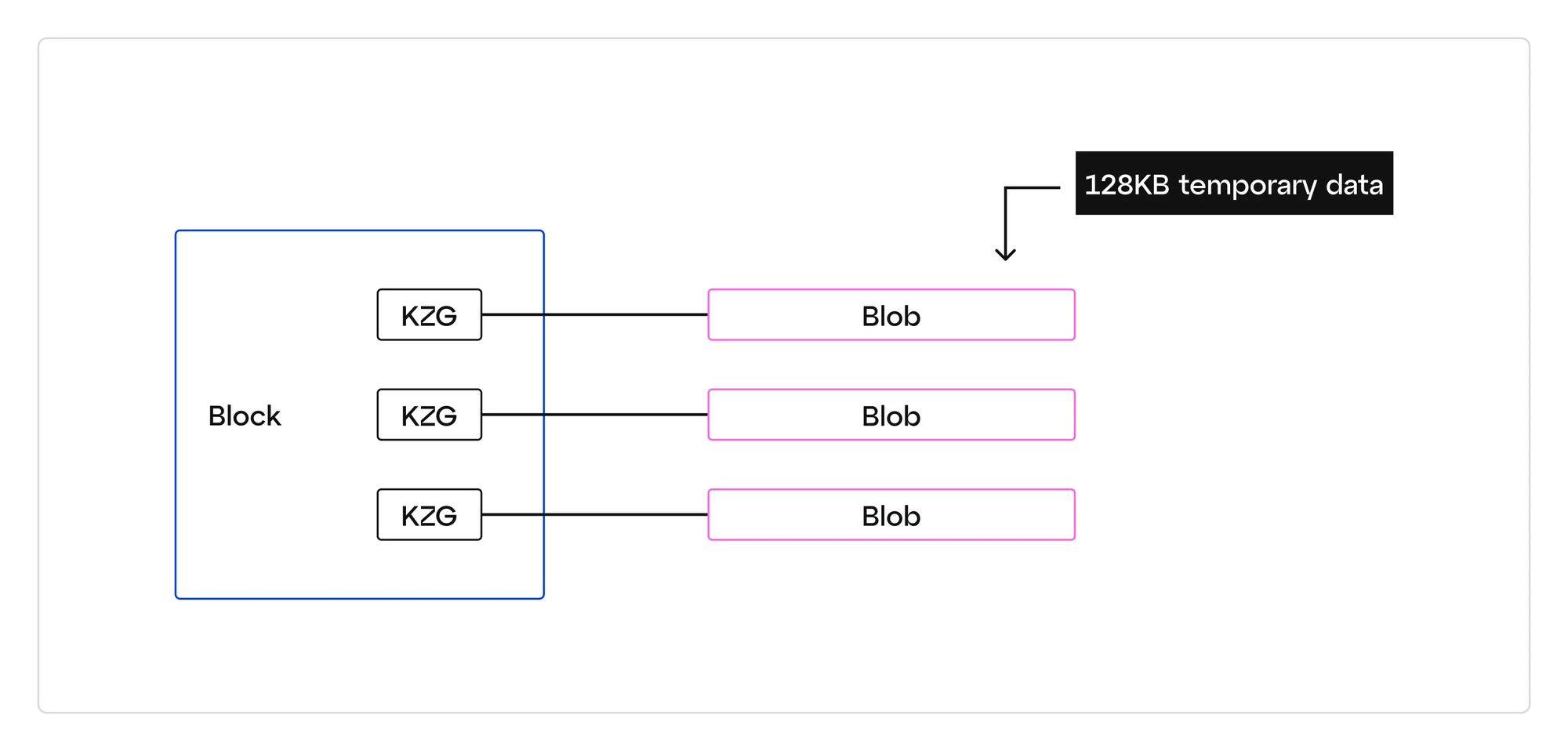
在今天的以太坊中,区块中充满了标准的以太坊交易。 在 Cancun-Deneb 分叉之后,区块可以被这些典型的以太坊交易和所谓的 Blob 携带交易的组合所填充。
Blob 可以被想象为充满数据的“边车”,它们将沿着块行驶。 填充以太坊区块的交易不一定需要有 blob,但是如果没有相关的 blob 携带交易进入区块,那么 blob 就不能包含在网络中。 虽然 blob 到底如何使用(以及由谁使用)还有待观察,但假设以太坊第 2 层汇总的排序器将是“blobspace”的主要消费者,并且 blob 将主要包含在 这些汇总。 此外,我们可以将这些 blob 视为“压缩”数据结构,例如 .zip 文件。
携带 blob 的交易包含两个典型以太坊交易所没有的新字段:
- 定义交易提交者愿意支付多少费用以将其携带 blob 的交易包含在块中的出价 (max_fee_per_blob_gas),以及
- 对事务中包含的 blob 的引用列表 (blob_versioned_hashes)。
值得注意的是,携带 blob 的交易实际上并不包含 blob 数据; 仅在 blob_versioned_hashes 字段(上面的第 2 项)中对其进行引用。 从技术上讲,此引用是 KZG 对 blob 承诺的哈希值,但就我们的目的而言,将其视为每个 blob 唯一的指纹并可用于将每个 blob 与包含 blob 的交易联系起来就足够了 。
由于给定块中仅存在对每个 blob 的引用,因此每个 blob 中包含的 L2 事务不会也不可能由以太坊的执行层(又名 EVM)执行。 这就是为什么给定大小的 blob 数据(每个 blob 128KB)可以通过汇总排序器比类似大小的常规以太坊调用数据更便宜地发布到以太坊 - blob 数据不需要由第 1 层重新执行( 在这种情况下是以太坊)。 构成每个 blob 的实际数据仅在以太坊的共识层(即信标节点)上流通和存储,并且仅在有限的时间内(4096 个纪元,或约 18 天)。
从技术上讲,blob 是由 4096 个字段元素组成的数据向量,每个字段元素的大小为 32 字节。 Blob 以这种方式构建,以便我们可以创建在携带 Blob 的交易中找到的对它们的简洁加密引用,并且可以将 Blob 表示为多项式。 将 blob 表示为多项式使我们能够应用一些巧妙的数学技巧,即纠删码和数据可用性采样,最终减少每个以太坊共识节点验证 blob 中的数据所需执行的工作量。 对实现这一切的数学的完整解释超出了本文的范围,但 Domothy 的 Blockspace 101 文章提供了一个易于理解的起点。
2、利用 Blob
汇总排序器将如何利用 blob?
最终,汇总排序器需要将一些数据发布到以太坊主网。 如今,他们通过将批量交易数据发布为以太坊调用数据来实现这一点,这是一种任意数据类型,并且可能非常昂贵。 实施 EIP-4844 后,汇总定序器可以签署并广播新的“携带 blob”交易类型,而不是将其数据作为 calldata 提交到主网,并实现相同的目标 - 将其数据发布到,并因此受到保护: 以太坊主网。
- EIP-4844 的新预编译
Proto-Danksharding 还引入了两个新的预编译,即 blob 验证预编译和点评估预编译,分别供 optimistic 和 zk-rollups 使用。 这些预编译用于验证 blob 中的数据是否与包含 blob 的事务中包含的 blob 引用相匹配(即 KZG 对 blob 承诺的版本化哈希)。
为了更具体地概述每个汇总将如何使用这些预编译,我们将引用 EIP-4844 本身:
“乐观汇总只需要在提交欺诈证明时实际提供基础数据。 欺诈证明提交功能将要求欺诈 blob 的完整内容作为调用数据的一部分提交。 它将使用 blob 验证功能根据之前提交的版本化哈希来验证数据,然后像今天一样对该数据执行欺诈证明验证。”
“ZK rollups 将为他们的交易或状态增量数据提供两个承诺:blob 中的 KZG 和使用 ZK rollup 内部使用的任何证明系统的一些承诺。他们将使用等价协议的承诺证明,使用点评估预编译,以 证明 KZG(协议确保指向可用数据)和 ZK rollup 自己的承诺引用相同的数据。”
3、Blob市场
虽然可以附加到块的 Blob 数量是动态的(范围为 0-6),但每个块将定位 3 个 Blob。 这一目标是通过与 EIP-1559 类似的定价激励机制进行的; 当一个块附加三个以上的 Blob 时,Blob 的定价会变得更加昂贵。 相反,当附加到给定块的 Blob 数量少于三个时,Blob 价格会变得更便宜。
具体来说,从一个区块到下一个区块的 Blob 交易成本最多可增加或减少 12.5%。 每个区块的这些价格变动接近 +/- 12.5% 的程度是通过所有附加 Blob 使用的 Gas 总量来计算的,这必然会随着 Blob 的增加而缩放,因为所有 Blob 的大小都是 128KB,无论它们是否 是否完全填满。
此定价计算通过运行的 Gas 计数来进行:如果区块持续托管超过 3 个 blob,则价格将持续上涨。
由于 blob 市场通过上述动态定价模型波动,第 2 层合约将需要 blob 市场的近实时定价信息,以确保正确的会计。 除了 EIP-4844 之外,相应的 EIP-7516 将用于创建操作码 BLOBBASEFEE,汇总和第 2 层将利用该操作码从块头查询当前的 blob 基本费用。 这是一个便宜的查询,只需要 2 个gas。
4、Blob过期
Blob 是暂时的,设计为在 4096 个 epoch 内保持可用,即大约 18 天。 到期后,大多数共识客户端将无法再检索 blob 中的特定数据。 然而,其先前存在的证据将以 KZG 承诺的形式保留在主网上(我们将在稍后解释)。 您可以将其视为残留的指纹或化石。 可以读取这些加密证明来证明特定的 blob 数据曾经存在,并且包含在以太坊主网上。
为什么选择18天? 这是增加状态大小的成本和活跃性之间的折衷,但做出这个决定也是考虑到乐观汇总,它有 7 天的防错窗口。 因此,此防错窗口是 blob 必须保持可访问的最短时间量,但最终分配了更多时间。 为了简单起见,选择了 2 的幂(4096 个纪元源自 2^12)。
尽管该协议不会强制 Blob 存储超过 18 天,但某些节点运营商和服务提供商很可能会存档这些数据。 也就是说,尽管协议没有强制要求永久包含在链上,但一个强大的 blob 存档市场很可能会在链外出现。
5、Blob大小
附加到块的每个 blob 可以保存 128KB 的临时数据,尽管给定的第 2 层可能无法完全填充给定的 blob。 重要的是,即使第 2 层确实完全填充了一个 Blob,附加到该块的 Blob 的“大小”也将始终为 128KB(仍必须考虑未使用的空间)。 因此,考虑到每个块的潜在 blob 范围,EIP-4844 可能会将与块关联的数据增加最多 768KB(每个 blob 128KB x 6 个可能的 blob)。
紧随 EIP-4844 之后,第 2 层将不会集体填充斑点。 事实上,第 2 层批处理到 blob 空间中的数据不会与其他第 2 层批处理的数据没有关系。 值得注意的是,协议升级或未来的创新,例如共享排序器或 blob 共享协议,可能允许 L2 共同填充给定的 blob。
当然,目前的区块空间就是这种情况,其中协议、汇总、dApp 和用户交易根据大小和优先费适当地捆绑在一起。 如果公共内存池的集体化通常满足持续满或接近满的块,则在引入 blob 共享形式之前,汇总可能会不太频繁地达到 128KB blob 空间限制。
不仅每个 blob 将有一个定序器或组织器(目前在我们的集中式定序器世界中),而且与块空间相比,blob 空间相对便宜的性质在短期内可能会减少填塞和效率最大化。 这样,在 rollup 市场和 rollup 本身进一步成熟之前,blobspace 效率可能不会立即接近最大值。
第 2 层也不会被迫使用 blobspace,有些人可能会选择偶尔继续使用块空间,甚至其他数据可用性平台。 人们可以根据数据检索的需要以及每种存储类型的市场价格想象出许多创造性的发布解决方案。
无论如何,附加六个完整 blob 的块并不代表块大小的无关紧要的增加。 如果现在的块大小可以达到约 1.875MB,并且完整的 blob 集可以增加约 0.75MB,那么我们应该注意到块大小增加约 40% 的可能性。
然而,我们必须相应地注意到,区块大小的增加仅发生在链头部的滚动约 18 天的基础上。 因此,网络上的节点不需要有意义地增加其长期存储容量; 18 天只是以太坊状态历史的一小部分。
以下计算可用于预测每个节点所需存储空间的目标增加量:
- 目标 3 个 blob,每个 128KB:每个块 384KB
- 每个 epoch 32 个区块 x 4096 个 blob 过期时间:131,072 个包含 blob 的区块
- 384KB x 131,072 块:存储增加 48GB
6、KZG 承诺和 KZG 仪式
我们之前将 blob 与附加到块的“边车”或“主车”进行了比较。进一步类比,将 KZG 承诺的散列视为连接两辆车的杆是合适的; 每个 blob 都需要自己的 KZG 承诺来与区块一起运行。
在 EIP-4844 后的共识过程中,验证者将需要下载整个 blob 以检查它们是否可用并验证 KZG 承诺是否正确。 实施完整的 Danksharding 后,他们只需要查看 Blob 的一小部分即可进行相同的验证。
然而,如果 blob 数据需要提交给 EVM,无论是在 Proto-Danksharding 中还是在 Danksharding 下,KZG 承诺本身都可以用来证明该数据的各个元素是正确的,而无需提供整个 128KB blob 。
作为生成与每个 blob 相关的 KZG 承诺的先决条件,社区进行了 KZG 可信设置仪式来创建必要的加密参数,否则未来的 KZG 承诺将不可能实现。 这个仪式向所有人开放,其主要目的是创造具有内部关联性的随机性,而没有人可以预测或重现。
事实上,仪式不仅向所有人开放,而且任何选择参加仪式的人都产生了一部分必要的先决条件,只有当这些先决条件一起使用时,才允许创建将 blob 附加到区块所需的 KZG 承诺。 为了揭示这些密码参数背后的秘密,从而打破 KZG 承诺方案,每个参与者都需要串通并连接他们各自的信息来重建整体。
因此,只有一个人需要诚实地丢弃他们的计算部分,以使其无法重新创建。 因此,任何为仪式做出贡献的个人都可以认为该设置是无需信任的,因为他们只需要相信自己。
7、以太坊可扩展性的演变
下图显示了过去几年来,以太坊社区围绕扩展的构思过程是如何进展的,从完整分片到原始 Danks 分片:
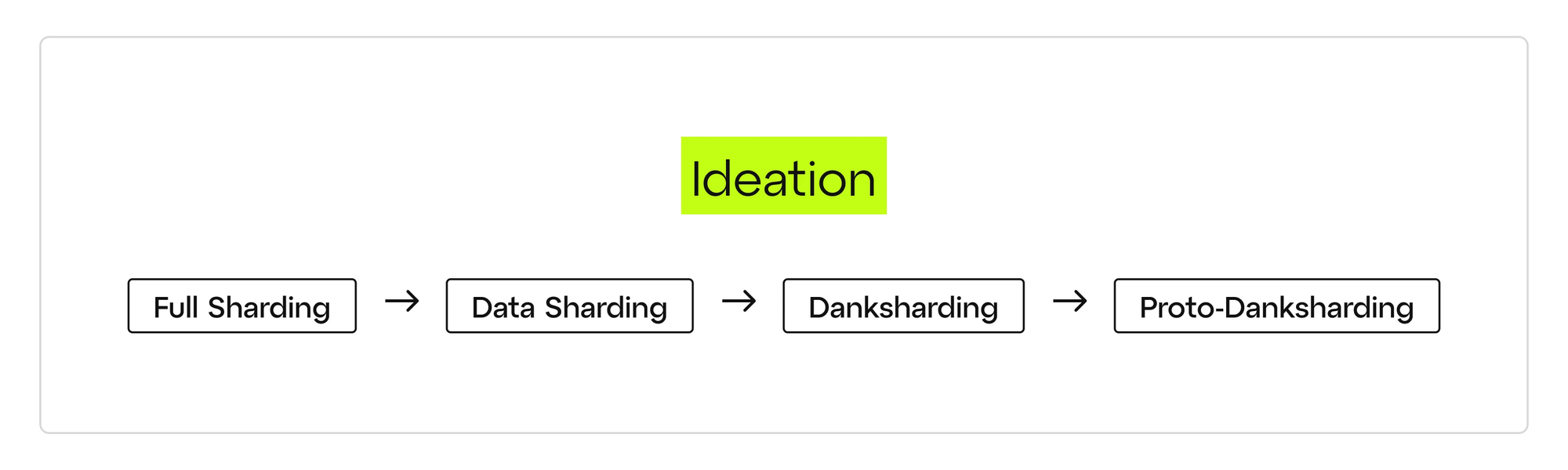
随着时间的推移,关于分片优化实施的共识逐渐转向更加务实和以 Rollup 为中心的方法。 EIP-4844 代表了理想的最终目标和现实的近期实施之间的折衷,同时仍然为实现理想的最终状态留下了技术跑道。
7.1 完全分片
分片(sharding)的概念最初是作为以太坊的水平扩展解决方案提出的,自链诞生以来,就在以太坊社区内进行了讨论和完善。 在其原始形式中,实施完全分片(又名完全执行分片)意味着将以太坊区块链分割成与信标链并行运行的多个分片(或迷你区块链)。 每个分片的运行方式与合并后的以太坊区块链类似,每个分片都有不同的块和块提议者,并且每个分片都由随机分配的、不断变化的以太坊活跃验证器集子集来保护。 这些验证器子集的任务是执行和验证交易、证明区块以及在分配的分片中提议区块。 信标链将充当该分片系统的协调器,将验证器随机分配给分片。
至关重要的是,完全分片将使以太坊的执行层(EL)和共识层(CL)都被分片,以实现网络的可扩展性目标。 这曾经是,现在仍然是以太坊区块链实现去中心化扩展的可行途径。 然而,在实践中,实施完整分片需要回答许多尚未解答的研究问题,例如分片之间的通信、分片的经济安全性等。 实施完全分片的复杂性和未知性为替代扩展解决方案(那些可以更快实施的解决方案)的出现创造了机会。
7.2 汇总和数据分片
熟悉以太坊生态系统的人可能意识到,自 2020 年以来,包括 Rollup 在内的第 2 层解决方案 (L2) 已成为以太坊的主要扩展解决方案。 Rollup,无论是 Optimistic 还是 zk-rollups,都是在以太坊主网(又名第 1 层或 L1)“之上”运行的独立区块链。 与 L1 区块链一样,rollup 也有自己的内部状态,并且对用户和开发人员很有吸引力,因为它们的交易成本比以太坊主网上便宜得多。 这是因为在 Rollup 中,用户交易是分批进行的,并且仅由每个 Rollup 的所谓排序器定期将单个交易发布到以太坊主网上的智能合约。
将交易执行外包给这些 optimistic 和 zk-rollups 有效地消除了以太坊节点自己执行这种计算成本高昂的执行工作的需要,但仍然允许以太坊节点通过对每个 rollup 的排序器的数据施加约束来保护和验证 L2 交易 可以发帖。 在乐观汇总的情况下,假定排序器发布的所有数据都是正确的。 然而,在某些数据(例如从 L2 到 L1 的资金桥接/释放)可以采取行动之前,会强制执行延迟。 在此延迟期间,任何人都可以(至少在理论上)提交故障证明以证明定序器发布了恶意或不正确的数据。 值得注意的是,在实践中,当今占主导地位的 Optimistic Rollup 要么没有启用这种故障证明机制,要么只允许白名单实体提交故障证明。 在 zk-rollups 的情况下,L1 合约将从排序器接受的唯一数据是带有加密有效性证明的数据,该证明为数据的正确性提供了数学保证。
随着汇总生态系统的蓬勃发展,L2 解决方案可以越来越多地满足交易执行的需求。 这样,rollup 的存在使得以太坊执行层的分片不再必要。 然而,验证这些 L2 事务仍然需要按需访问验证所需的数据。 因此,以太坊可扩展性的焦点从以太坊 EL 和 CL 的完全分片(即扩展执行和数据可用性)转移到相对简单的分片以太坊 CL(即扩展数据可用性)的任务。
7.3 Dank分片
正如我们在上面看到的,L2 汇总的引入意味着以太坊可以将执行外包给这些协议外扩展解决方案,并放弃完全分片。 Danksharding——以以太坊研究员 Dankrad Feist 命名——代表了一种进一步的简化,消除了对以太坊 CL 进行分片的需要。
Danksharding 没有将以太坊的验证节点拆分为独立处理和验证所有以太坊和 L2 数据的分片,而是提出了一种新的交易类型,其中包含对大型附加数据“blob”的引用(注意:这些都是相同的“blob-carrying”) 我们将通过 EIP-4844 获得的交易)。 通过以巧妙的方式构造这些 blob,以便它们可以表示为多项式,以太坊的验证节点可以利用所谓的多项式承诺方案 ,通过数据可用性采样来验证 blob 数据在概率上可用,而无需 下载并验证整个 blob。 最终,这允许以太坊协议发布引用大量 blob 数据的块,同时保持验证节点较小,从而可以保留去中心化。
值得注意的是,以这种方式保持以太坊的验证节点较小需要提议者/构建者分离(PBS),其中块构建器处理并执行所有块和 blob 数据,负责提议新块的验证器只需选择并提议提交最高的块头 bid 和所有其他验证器只需通过数据可用性采样来验证块数据。 由于以太坊验证器不会在主网上包含区块,除非它们可以验证区块的数据可用,这使得汇总排序器几乎不可能将其数据发布到主网上,同时保留部分或全部数据。
如前所述,Danksharding 消除了将以太坊验证器分成负责验证以太坊区块链的单独分片的子组的需要。 事实上,Danksharding 有点用词不当,或许更适合称为 Danksampling,因为从技术上讲,分片并没有按照最初的设计那样进行。 Blob 验证的一部分将概率性地分配给单个节点分组,而不是由多个以太坊验证节点分组水平完成验证。 区块验证将保持不变。
因此,Danksharding 的引入意味着,我们不仅可以避免以太坊执行层的分片(由于引入了 L2 汇总),而且由于引入了巧妙构建的 blob、数据可用性,我们还可以在技术上避免共识层的分片。 采样和 PBS。 虽然手段有很大不同,但数据分片和 Danksharding 能够提供类似的结果 - 保持以太坊去中心化的扩展。
7.4 原型dank分片
尽管如此,我们并未在 Cancun-Deneb 升级中实施 Danksharding。 EIP-4844 通常被称为“Proto-Danksharding”,以以太坊研究人员 Protolambda 和 Dankrad Fiest 命名。 它作为 Danksharding 的初步版本,将为 Danksharding 的全面实施奠定大部分必要的加密基础。
一旦 EIP-4844 到位,实施 Danksharding 的剩余工作将仅限于共识层。 之后,执行层团队或汇总本身将不再需要从 Proto-Danksharding 过渡到 Danksharding。 汇总将简单地提供更多更大的 blob 来处理。
总而言之,除了完全分片(Full Sharding)已经脱离了普遍共识,并且随着执行需求越来越多地从主网转移到汇总(rollups)而不太可能被实施之外,分片和去中心化扩展可能会以相反的顺序实施 以太坊社区思考了这个问题。 然而,目前,与完全实现的 Danksharding 相比,即使是数据分片也常常被认为是多余和不必要的。
下图显示了以太坊上分片最有可能的实现路径:
在实践中,我们可以看到以太坊社区在以太坊历史上逐渐摆脱单一设计,并拥抱模块化扩展架构。 以太坊以汇总为中心的路线图不需要在主网上进行执行优化,但也不禁止它。 重要的是,数据分片,甚至完全分片仍然是未来的可能性。
7.5 Dank分片之路
EIP-4844 上线后,每个节点都需要下载每个 blob。 为了超越原始 danksharding 并进入 Danksharding,节点只需在称为数据可用性采样的过程中下载这些 blob 的一部分,这一点很重要。 通过这样做,我们可以增加可以附加到每个块的 blob 数量,而不增加每个节点操作员感受到的负载 - 这是真正的分片。
以同样的方式,Proto-danksharding 的目标是 3 个 blob,但允许最多 6 个 blob,Danksharding 渴望目标 8 个 blob,最多 16 个。
但我们还没有完成! 除了增加可能附加到块的 blob 数量之外,Danksharding 还将增加每个 blob 的大小。 在称为纠删码的过程中,每个节点不必验证整个 blob,而只需验证它的一部分。
如果数据可用性采样减少了给定节点必须验证的 blob 数量,则纠删码会减少节点必须验证的 blob 数量。 尽管如此,还有其他更微妙的技术问题必须解决,其中之一就是创建更具弹性的网络拓扑。 这里有一些额外的阅读材料,供感兴趣的人阅读。
免责声明:本站资源仅用于学习目的,也不应被视为投资建议,读者在采取任何行动之前应自行研究并对自己的决定承担全部责任。