Chain Indexer Framework实战
Chain Indexer Framework的架构可以分为三个部分:生产者、转换器和消费者。本指南将向你展示如何使用Chain Indexer Framework为 EVM 兼容的区块链(例如以太坊、Polygon Proof of Stake 等)构建自己的索引器!

一键发币: Aptos | X Layer | SUI | SOL | BNB | ETH | BASE | ARB | OP | Polygon | Avalanche | 用AI学区块链开发
本指南将向你展示如何为 EVM 兼容的区块链(例如以太坊、Polygon Proof of Stake 等)构建自己的索引器!
最后,你将拥有一个运行 Kafka 的 Docker 容器,它捕获你指定的所有区块链事件,以及有关如何在应用程序内转换和使用此数据的参考!
我们开工吧!
1、工作原理
Chain Indexer Framework的架构可以分为三个部分:
- Block Producers:区块生产者,扫描区块链并将原始区块数据发布到 Kafka 中。
- Transformers:数据变换器,将来自 Kafka 的原始数据转换成有意义的事件。
- Consumers:消费者,读取各种用例的转换数据,例如从前端应用程序或 API 端点。
我们将首先在 Docker 容器内设置 Kafka 实例,然后为三个组件中的每一个运行一个用 TypeScript 编写的脚本。
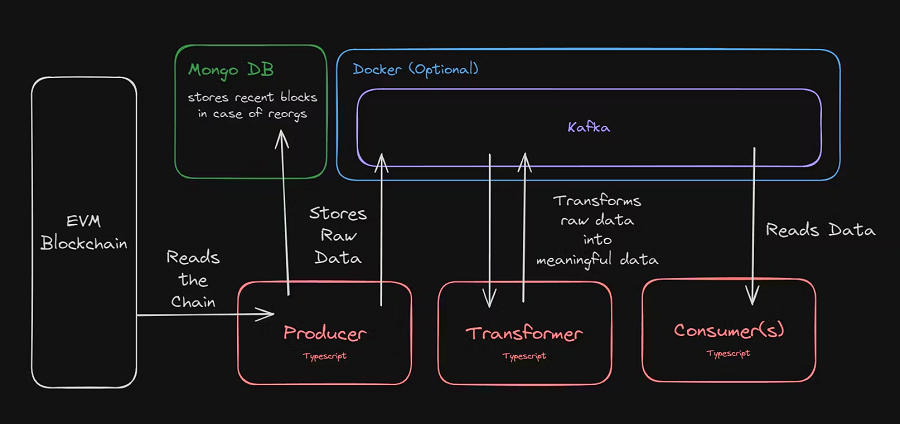
2、系统架构图
生产者从指定的区块链读取数据并将其发布到在 Docker 容器中运行的 Kafka 实例中。 同时,它还将最新的块保留在 Mongo DB 中,以备重组之用。
一旦存储在 Kafka 中,我们就能够将其转换为更有意义的数据,并可供任何消费者读取; 例如应用程序。
3、设置后端基础设施
在创建这三种服务(生产者、转换器、消费者)之前,我们需要设置连接到区块链和存储数据所需的基础设施。 在本部分中,我们将设置以下服务:
- 连接到区块链的 RPC
- 运行 Kafka 来存储原始数据的 Docker 容器
- 用于存储最新块的 Mongo 数据库。
让我们首先创建一个新目录来包含我们要做的所有工作:
# Create our base directory
mkdir chain-indexer-framework-guide
# Change into this new directory
cd chain-indexer-framework-guide
# Open in VS Code
code .4、创建 Docker Compose 文件
现在让我们通过创建 Docker Compose 文件来设置 Docker 容器。
💡你需要为本指南的这一部分安装 Docker。 按照获取 Docker 页面上的说明进行操作,并通过在终端中运行 docker --version来验证你的安装。Docker Compose 文件允许我们定义应用程序的环境。 要创建一个,让我们在此当前目录中创建一个 docker-compose.yml 文件。
💡如果你使用 VS Code,建议安装 Docker 扩展。
在 docker-compose.yml 中,设置以下 compose 文件:
---
version: "3"
services:
zookeeper:
image: confluentinc/cp-zookeeper:7.0.0
hostname: zookeeper
container_name: zookeeper
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
broker:
image: confluentinc/cp-kafka:7.0.0
container_name: broker
ports:
- "9092:9092"
depends_on:
- zookeeper
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: "zookeeper:2181"
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_INTERNAL:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://localhost:9092,PLAINTEXT_INTERNAL://broker:29092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
我们不会涵盖本指南中的所有字段(了解有关撰写文件的更多信息),但该文件将允许我们使用 Apache ZooKeeper 运行 Docker 容器来维护配置信息,并使用 Apache Kafka 来存储原始数据。
5、运行 Docker 容器
现在我们已经定义了 compose 文件,让我们运行 Docker 容器。
使用 Docker Compose 的“up”命令和 -d 标志以分离模式运行容器。
docker-compose up -d
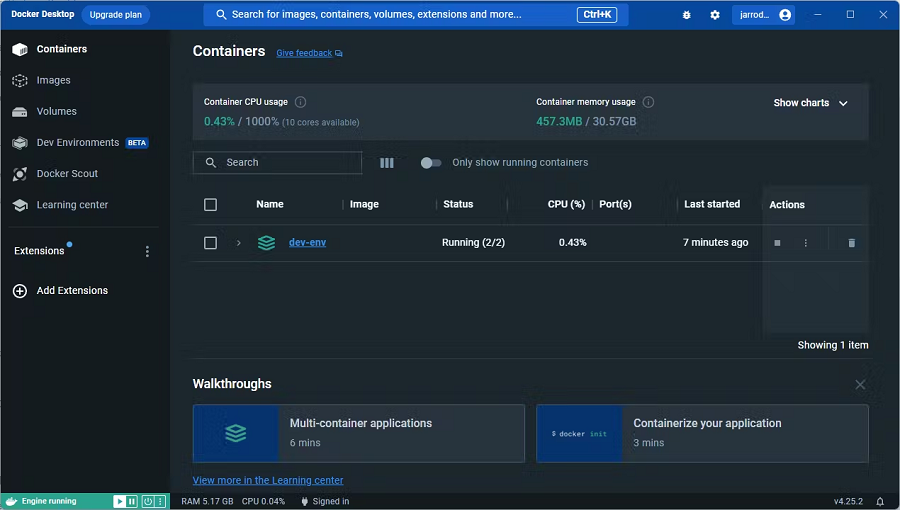
运行 docker ps命令查看所有容器的状态:

你还可以运行 Docker Desktop 以查看容器正在运行:
现在我们的 Kafka 实例已启动并运行,我们已准备好存储来自区块链的原始数据。 然而,要读取区块链数据,我们需要一种连接到链本身的方法; 接下来让我们创建一个新的 RPC 节点。
6、创建 RPC 节点
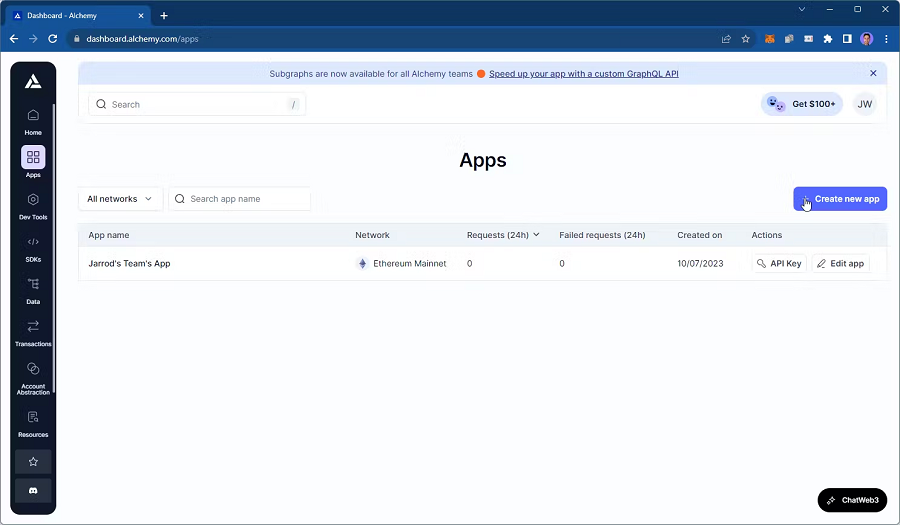
有许多解决方案提供商提供与区块链的 RPC 连接。 在本指南中,我们将使用流行的 RPC 提供程序 Alchemy 作为我们的 RPC 提供程序,因为它们提供了慷慨的免费套餐。
首先,前往 Alchemy 仪表板的“应用程序”页面,然后单击“创建新应用程序”:
选择要从中读取数据的链和网络,然后单击创建应用程序:
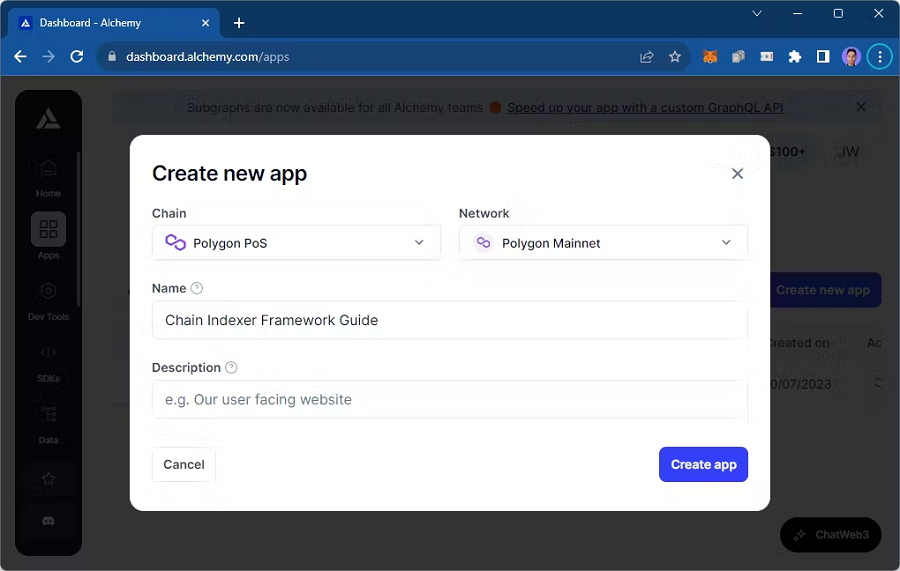
当我们编写生产者时,我们稍后会回过头来获取我们的 RPC URL。
7、创建 Mongo 数据库
接下来,让我们建立一个数据库来执行 TODO。
在本指南中,我们将使用 Mongo DB,因为链索引器框架的 Producer 有一个 mongoUrl 属性,我们可以轻松地将此数据库插入其中。
如果尚未注册 Mongo DB,请注册并部署新数据库。
以下是我选择的选项; 但您可以根据自己的喜好进行自定义:
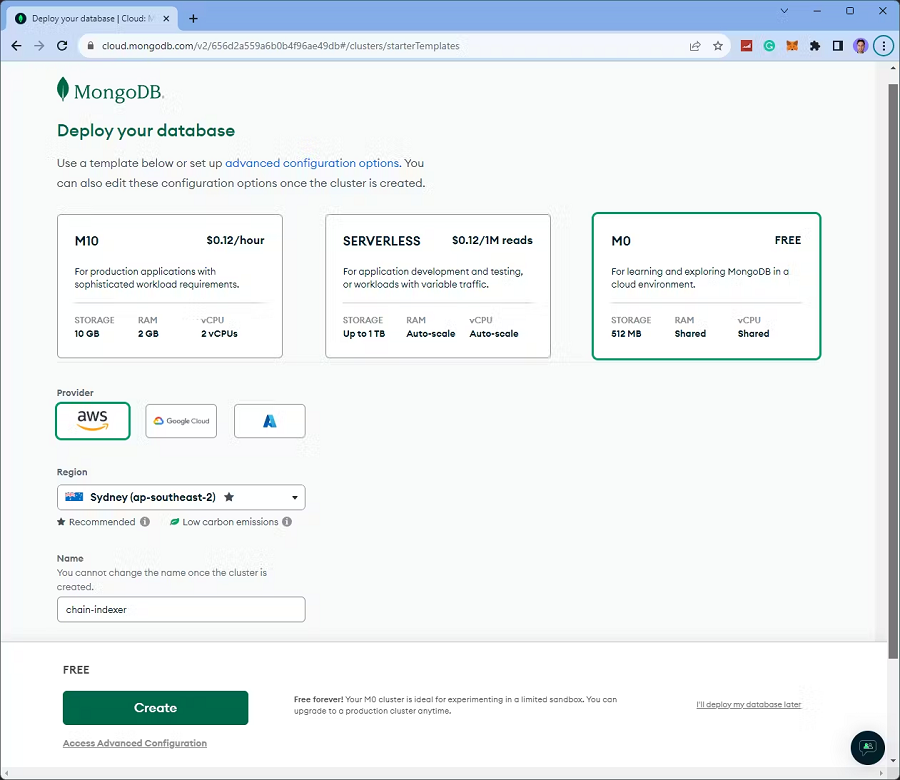
配置数据库后,完成设置过程。
首先,添加一个认证方法; 在本指南中,我们使用自动生成的简单用户名和密码。
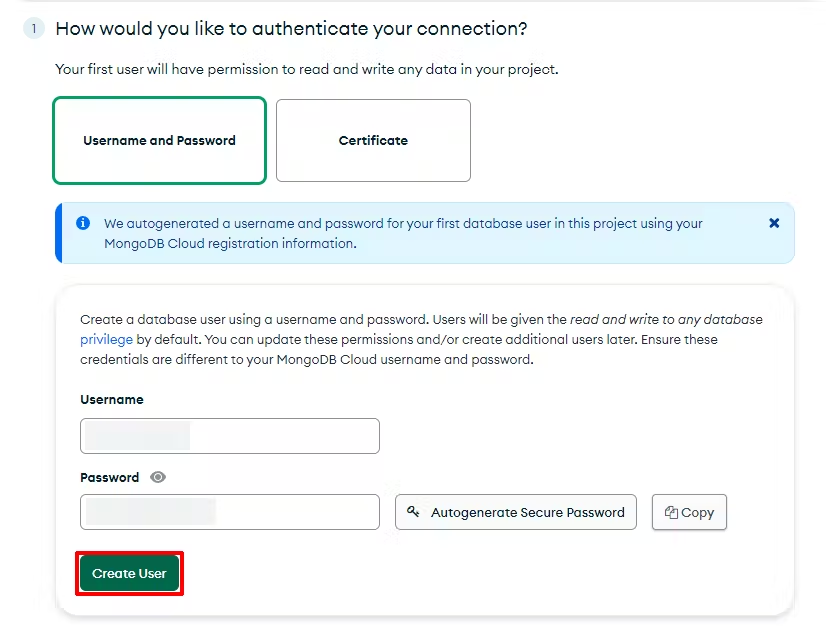
其次,配置谁可以访问你的数据库。 在本指南中,我们只是添加当前计算机的 IP 地址。 最后,单击完成并关闭。
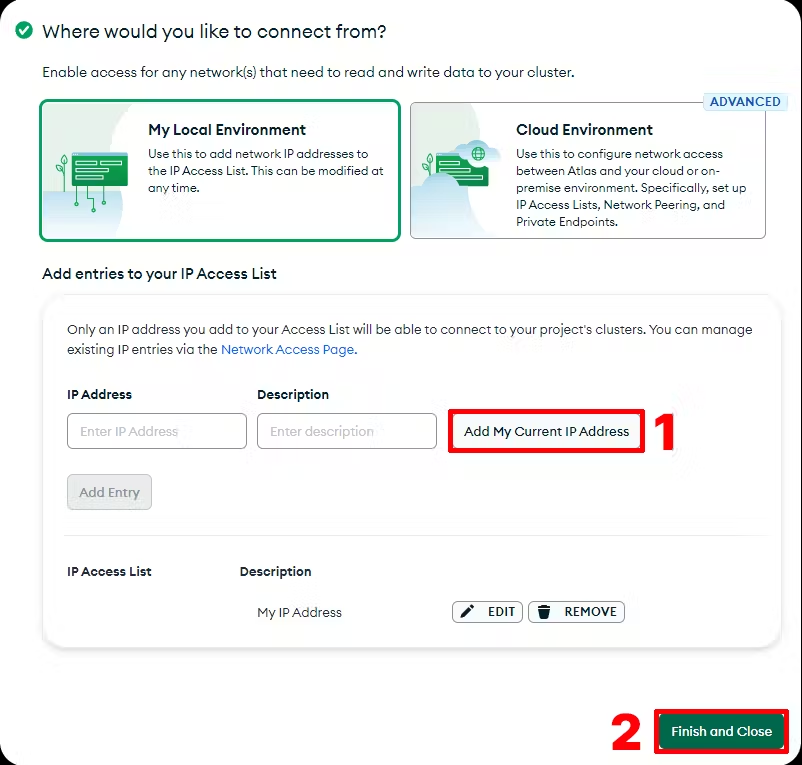
最后,基础设施设置完成! 🎉
8、设置 Node.js + TypeScript
现在我们准备好设置链索引器框架的三个组件。
通过运行以下命令来设置一个简单的 TypeScript + Node.js 项目:
npm init -y
要添加 TypeScript,请创建一个包含以下内容的 tsconfig.json 文件:
{
"compilerOptions": {
"module": "NodeNext",
"moduleResolution": "NodeNext",
"esModuleInterop": true,
"target": "ES2020",
"sourceMap": true,
"strict": true,
"outDir": "dist",
"declaration": true
},
"include": ["src/**/*"]
}
将 package.json 文件设置为以下内容:
{
"name": "producer",
"version": "1.0.0",
"type": "module",
"main": "index.js",
"scripts": {
"build": "tsc",
"start-producer": "npm run build && node --experimental-import-meta-resolve --trace-warnings dist/producer.js",
"start-transformer": "npm run build && node --experimental-import-meta-resolve --trace-warnings dist/transformer.js",
"start-consumer": "npm run build && node --experimental-import-meta-resolve --trace-warnings dist/consumer.js"
},
}
安装所需的 TypeScript 依赖项:
npm install -D typescript @types/node
在安装更多依赖项之前,你需要遵循 node-gyp 的安装说明作为安装 @maticnetwork/chain-indexer-framework 包的先决条件。 如果你使用的是 Windows,这包括在 Visual Studio 中安装当前版本的 Python 和 Visual C++ 构建环境。
接下来,通过运行以下命令来安装 @maticnetwork/chain-indexer-framework 包:
npm install @maticnetwork/chain-indexer-framework
最后,创建一个src文件夹,包含三个文件:
- producer.ts
- transformer.ts
- consumer.ts
现在我们准备出发了。 我们先从producer.ts开始吧。
9、创建生产者
在 Producer.ts 文件中,我们将连接到你在 RPC 步骤中选择的区块链并将原始数据写入 Kafka。
下面是开始在 Kafka 中存储原始数据的基本代码。 Mongo DB 用于存储最新数量的块(在 maxReOrgDepth 字段中指定),然后它们才会在 Kafka 中永久存在。
import { BlockPollerProducer } from "@maticnetwork/chain-indexer-framework/block_producers/block_polling_producer";
import { produce } from "@maticnetwork/chain-indexer-framework/kafka/producer/produce";
const producer = produce<BlockPollerProducer>({
startBlock: 50689834, // Pick any start block you want
rpcWsEndpoints: ["<your-alchemy-rpc-url-here>",],
blockPollingTimeout: 20000,
topic: "polygon.1442.blocks",
maxReOrgDepth: 256, // Maximum reorg depth on Polygon is 256
maxRetries: 5,
mongoUrl: "mongodb+srv://<your-mongo-username>:<your-mongo-password>@chain-indexer.0ymaemb.mongodb.net/",
"bootstrap.servers": "localhost:9092",
"security.protocol": "plaintext",
type: "blocks:polling",
});
producer.on("blockProducer.fatalError", (error: any) => {
process.exit(1); //Exiting process on fatal error. Process manager needs to restart the process.
});
重要的是,你需要:
- 在 rpcsWsEndpoints 字段中添加你的 HTTPS Alchemy RPC URL。
- 添加你的 Mongo URL 连接字符串作为 mongoUrl。
- 或者,根据你的喜好配置其他属性。
准备好后,可以运行以下命令来启动生产者:
npm run start-producer
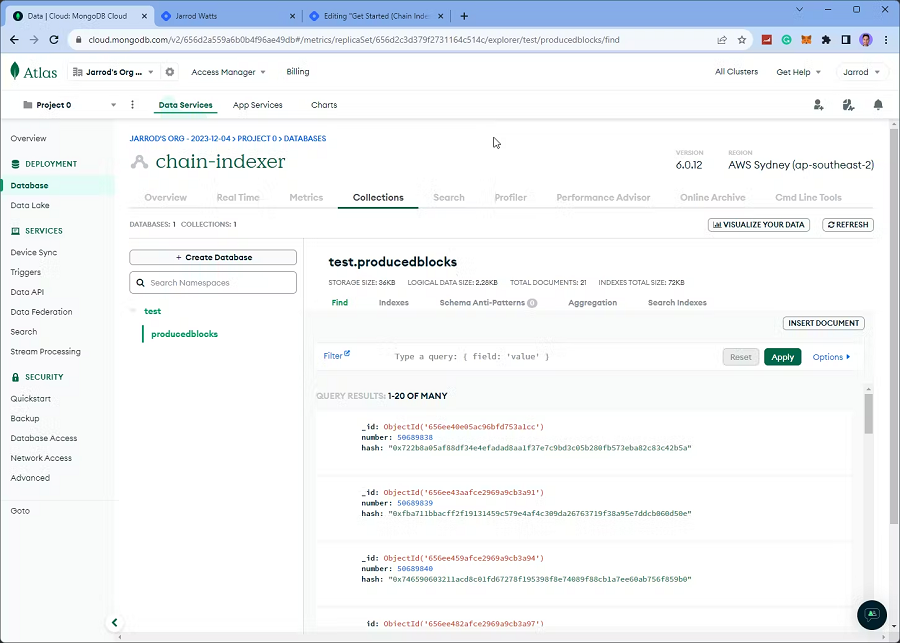
如果一切按预期工作,应该开始看到 Mongo DB 中出现一些数据,你可以在“数据库”>“集合”部分中找到这些数据:
10、添加日志记录
Chain Indexer Framework还具有日志记录功能,可以查看幕后发生的情况。 要将其添加到您的生产者中,首先导入 Logger:
import { Logger } from "@maticnetwork/chain-indexer-framework/logger";
并可以选择将日志添加到生产者发出的任何事件中,例如:
producer.on("blockProducer.fatalError", (error: any) => {
Logger.error(`Block producer exited. ${error.message}`);
process.exit(1); //Exiting process on fatal error. Process manager needs to restart the process.
});
11、转换和使用数据
现在我们的 Kafka 实例中有可用的原始数据! 你已准备好开始在应用程序中转换和使用数据。
虽然有相当多的代码可以开始执行这些步骤,但我们已经为一切奠定了基础,所以它应该相对简单!
我们没有转储所有代码供您复制和粘贴,而是在下面链接的 GitHub 上制作了一些关于如何设置不同类型的转换器和生成器的开源示例:MATIC转账 ,NFT余额 。
原文链接:Create A Blockchain Indexer with Chain Indexer Framework
DefiPlot翻译整理,转载请标明出处
免责声明:本站资源仅用于学习目的,也不应被视为投资建议,读者在采取任何行动之前应自行研究并对自己的决定承担全部责任。