构建Solana代币风险模型
在这篇博客中,我们将揭示我们专为Solana上的代币风险预测设计的机器学习API——Egeria的内部工作原理。

一键发币: Aptos | X Layer | SUI | SOL | BNB | ETH | BASE | ARB | OP | Polygon | Avalanche | 用AI学区块链开发
比特币以其安全性而闻名,但并非所有数字货币都具有同样的可靠性。尽管有光鲜的成功故事,许多代币最终被证明是骗局。
这些骗局通常被称为“拉地毯”(rug pulls)。当一个代币的创建者突然携款潜逃时,就会发生这种情况,导致投资者一无所获。
Solana是一个Layer 1区块链,包含了大量的代币,这些代币可以快速且几乎零成本地创建。这对于创新来说是好事,但也为不良行为者提供了机会,他们可以创建代币只是为了在资金开始流入后立即拉地毯。
在这篇博客中,我们将揭示我们专为Solana上的代币风险预测设计的机器学习API——Egeria的内部工作原理。
想亲自动手吗?我们还将引导你构建Egeria的一个简化版本,使你能够自己制作代币风险评估工具。
1、设置环境
在深入之前,让我们准备好我们的环境。我们将安装所需的依赖项、模块,并收集构建模型所需的数据。为了方便起见,请考虑使用Google Colab来设置你的笔记本。查看我们的笔记本,以获取示例指导你完成过程!
安装依赖项:
# 安装必要的模块。
!pip install -U pandas
!pip install -U scikit-learn
!pip install -U numpy
!pip install -U matplotlib
!pip install xgboost==2.0.3
!pip install pandas==2.2.1
!pip install joblib==1.3.2
注意:如果你在VSCode上使用Jupyter Notebook,只需将!替换为%。
太棒了!有了这些模块,我们就有了构建数据集、构建预处理器、训练模型、评估其性能并保存以供日后使用的工具。以下是简要概述: Pandas:用于数据操作和分析,提供适合处理结构化数据(如数据框)的数据结构和函数。我们用它来读取数据集。
Numpy:用于数值计算,提供高效的数值数据存储和操作,以及优化的数学函数,我们用numpy来计算概率分数。
SciKit-Learn:全面的机器学习库,具有一致的API、丰富的文档和各种用于监督和无监督学习任务的算法。我们使用sklearn训练回归模型并与XGBoost进行比较。
XGBoost:强大的梯度提升算法实现,以其效率和可扩展性著称,特别适用于结构化/表格数据,并在回归任务中表现出色。
Joblib:专门用于保存和加载Python对象的工具,特别适用于科学计算和机器学习模型,提供高效的序列化接口。
现在我们已经拥有了所有必需的依赖项,让我们开始整理数据。
2、数据收集
为了有效地训练一个ML模型,拥有大量的数据至关重要。
由于我们正在训练一个监督学习模型,因此需要一个标记的数据集。标记的数据集是一组数据实例,其中每个实例与一个或多个类别或标签相关联。这使得模型可以从标签中学习模式,并将其应用于未见过的数据。
为了构建我们的数据集,我们需要一组混合的代币,其中一些是高风险的,一些是安全的。如果数据集不平衡,即高风险标记的代币多于非高风险代币,那么模型可能会偏向于预测所有代币都是高风险的,从而降低识别真正优质代币的能力。我们将利用Vybe API来获取代币数据。
💡 什么是Vybe API?Vybe API是为开发人员和团队设计的API,用于访问DeFi、AI、交易等专业端点。你可以通过它以极高的速度和效率集成和构建项目,充分利用Solana的功能来推进你的项目。
你可以访问用于获取数据的脚本这里。
我将在另一篇详细的博客文章中深入探讨如何使用VYBEAPI获取数据。
3、数据预处理
现在我们已经从Vybe获取了原始数据,是时候清理和预处理它了。我们不能直接将原始数据输入到模型中,因为有一些不需要的列和属性需要删除。
def preprocess_data(df):
df = df.drop(['address', 'lastTradeUnixTime', 'mc'], axis=1)
X = df.drop('Risk', axis=1)
y = df['Risk'].map({'Danger': 1, 'Warning': 1, 'Good': 0}).astype(int)
return train_test_split(X, y, test_size=0.4, random_state=42)
在上述代码片段中,我们删除了一些不贡献于模型的列。像‘address’、‘lastTradeUnixTime’、‘mc’和‘Risk’这样的列不会直接提高模型的性能,所以我们把它们删掉了。
数据预处理对于准备原始数据进行机器学习任务至关重要。它涉及解决诸如缺失值、分类变量和特征缩放等问题。提供的代码定义了一个名为build_preprocessor的函数,该函数将预处理步骤封装到数值和分类特征的管道中。这些管道使用策略如均值插补法对数值特征进行缺失值处理,使用最频繁插补法对分类特征进行缺失值处理。此外,数值特征被标准化,分类特征被独热编码(one-hot encoding)。
💡 什么是独热编码?独热编码是一种将分类数据转换为二进制向量的方法,其中只有一个元素是激活的。
这些管道使用ColumnTransformer组合在一起,指定应对其应用哪些特征,并允许任何剩余的列保持不变。这种方法简化了预处理工作流程,使其更高效且易于维护,适用于机器学习项目。
def build_preprocessor(X_train):
numeric_features = ['decimals', 'liquidity', 'v24hChangePercent', 'v24hUSD', 'Volatility', 'holders_count']
categorical_features = ['logoURI', 'name', 'symbol']
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='mean')),
('scaler', StandardScaler())
])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('onehot', OneHotEncoder(handle_unknown='ignore'))
])
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)
],
remainder='passthrough'
)
return preprocessor
现在我们已经准备好预处理器,可以将其应用于数据。
4、模型训练
def train_model(X_train, y_train, preprocessor):
model = Pipeline(steps=[
('preprocessor', preprocessor),
('classifier', xgb.XGBClassifier(n_estimators=100, learning_rate=0.1, max_depth=3, random_state=42))
])
model.fit(X_train, y_train)
return model
提供的train_model函数将训练过程封装在一个Pipeline中,该Pipeline集成了先前定义的预处理器。这个预处理器会对数据应用诸如插补和编码的转换,然后将其输入到XGBoost分类器中。通过调整超参数,如估计器数量、学习率和最大深度,XGBoost分类器可以有效学习预处理后的数据。使用Pipeline,我们可以确保预处理和模型训练之间的无缝集成,简化整个工作流并增强可重复性。
5、为什么选择XGBoost?
在选择XGBoost作为本项目模型时,我们选择了以其多功能性、鲁棒性和在广泛数据类型和复杂性下的优越性能而闻名的模型。与较简单的模型如逻辑回归相比,XGBoost在处理具有多种特征类型的复杂数据集方面表现出色,这使其特别适合于现实世界中的机器学习任务中经常遇到的挑战。
XGBoost的一个关键优势在于其通过内置的正则化技术减轻过拟合的能力,这是复杂模型常见的问题。通过在其目标函数中结合L1和L2正则化项,XGBoost有效地惩罚过于复杂的模型,从而提高泛化能力并防止过拟合。
此外,XGBoost采用集成学习方法,结合多个弱学习者的预测(通常是决策树)以生成稳健且准确的最终预测。通过梯度提升等技术,XGBoost迭代改进前序模型的弱点,重点关注预测不太准确的实例。这种逐步细化过程使XGBoost能够逐渐学习数据中的复杂模式,从而在预测性能上优于许多其他机器学习算法。
因此,对于我们的项目,这可能涉及大型且复杂的包含大量数据的任务,准确性与泛化能力至关重要,XGBoost成为最优选择,提供了一种灵活、稳健且具有强大预测能力的组合。
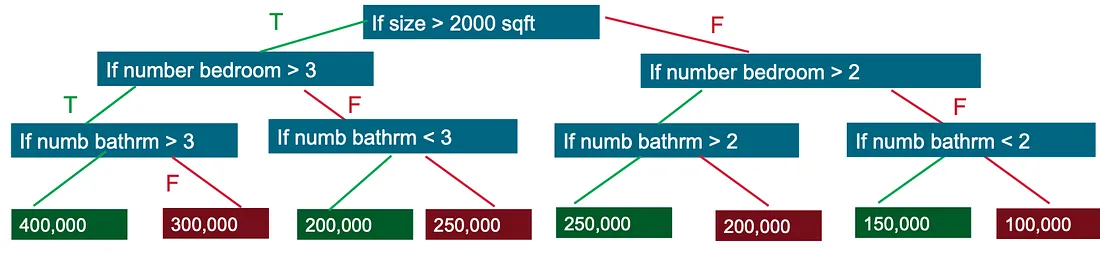
💡 决策树通过评估一系列真假特征问题的树形结构来创建一个模型,预测标签,并估计做出正确决策所需的最少问题数。决策树可用于分类以预测类别,或回归以预测连续的数值。
同样地,我们的模型使用决策树的真假特征问题方法,例如波动性、流动性等特征。
6、模型评估
好了,我们已经做好了菜肴,现在是品尝的时候了,看看效果如何:
为了评估分类模型的有效性,我们将使用混淆矩阵可视化其性能。这个矩阵提供了关于模型如何预测测试数据集中类别的见解,其中真实值已知。以下是混淆矩阵的样子:
实际\预测类别 | 正面 | 负面 |
---------------------------------------
正面 | 真阳性 | 假阳性 |
负面 | 假阴性 | 真阴性 |
- 真阳性(TP):模型正确预测正面类别。
- 假阳性(FP):模型错误预测正面类别。
- 假阴性(FN):模型错误预测负面类别。
- 真阴性(TN):模型正确预测负面类别。
通过检查这些值,我们将深入了解模型在根据风险级别对代币进行分类方面的表现。让我们深入分析结果! 📊
def evaluate_model(model, X_test, y_test):
y_pred= model.predict(X_test)
accuracy= accuracy_score(y_test, y_pred)
classification_report_result= classification_report(y_test, y_pred)
conf_matrix= confusion_matrix(y_test, y_pred)
print(f'模型准确率: {accuracy}')
print('分类报告:\\n', classification_report_result)
print("混淆矩阵:\\n", conf_matrix)
太棒了!你已经组装了所有必要的函数来构建你的模型。让我们将它们组合成一个主函数,并使用单个输入运行它。另外,我们还会保存模型以备后用。
def main():
file_path= 'preProcessedTokens.json'# 更新此路径df= load_data(file_path)
X_train, X_test, y_train, y_test= preprocess_data(df)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
preprocessor= build_preprocessor(X_train)
model= train_model(X_train, y_train, preprocessor)
evaluate_model(model, X_test, y_test)
# 保存模型和预处理器
joblib.dump(model, "predictModel.pkl")
joblib.dump(preprocessor, "mainPreprocessor.pkl")
# 示例单个项目的预测
single_item_corrected= {
"decimals": 6,
"liquidity": 62215.15524335994,
"logoURI": "https://img.fotofolio.xyz/?url=https%3A%2F%2Fbafkreifhqihaiwyo4g2aogdu4qyfqftkxy3aq4xxbhoxdkbkufrobsnjwm.ipfs.nftstorage.link",
"name": "SBF",
"symbol": "SBF",
"v24hChangePercent":-49.17844813082829,
"v24hUSD": 18220.724466666383,
"Volatility": 76.06539722778419,
"holders_count": 0
}
# 转换为DataFrame
single_item_df= pd.DataFrame(single_item_corrected, index=[0])
prediction= model.predict(single_item_df)# 预测
print(f'单个项目预测结果: {prediction}')
if __name__== "__main__":
main()
大功告成!你自己的ML模型已经准备好分析代币的风险了。注意到那些带有.pkl扩展名的新文件了吗?这些是我们模型的保存文件。我们可以使用它们来运行模型,并设置FastAPI端点将其集成到你的应用程序中。
在下一篇博客中,我们将看到如何使用VYBE API抓取我们需要训练模型的所有数据。
原文链接:Building a Solana Token Risk Model the Hard Way
DefiPlot翻译整理,转载请标明出处
免责声明:本站资源仅用于学习目的,也不应被视为投资建议,读者在采取任何行动之前应自行研究并对自己的决定承担全部责任。