用DuckDB 构建个人市场数据库
在这篇文章中,我将引导读者通过构建一个个性化的股票市场数据库的过程,在本地环境中提供一种快速且可扩展的方法,以启动许多可以指导自己投资决策的创新项目。

一键发币: x402兼容 | Aptos | X Layer | SUI | SOL | BNB | ETH | BASE | ARB | OP | Polygon | Avalanche
我热衷于利用 Python 和机器学习来在股票市场中获得优势,以做出明智的投资决策。到目前为止,我已经构建了几个这样的项目,但在获取、存储和使用数据方面,我一直从头开始,这可能是最重要的一步。
在这篇文章中,我将引导读者通过构建一个个性化的市场数据库的过程,在本地环境中提供一种快速且可扩展的方法,以启动许多可以指导自己投资决策的创新项目。
1、动机
如引言中所述,我已经开发并继续开发一些将机器学习和分析技术与金融数据结合的应用程序。每一个项目都依赖于一个数据工程任务。因此,我问自己,为什么我不建立一个可以在这些项目中通用的解决方案?
在这个职业阶段,作为一名数据科学专业人士,我已经完成了许多涉及从 CSV 或类似文件中摄取数据的项目。虽然这绝对没有问题,特别是对于数据领域的初学者来说,但如果你想要构建更高级和专业的应用程序,这不是一个可扩展的解决方案。
经过探索多个选项后,我决定使用开源数据库管理系统 DuckDB。这是我的用例的完美选择,因为 DuckDB 可以直接在应用程序中工作,像任何其他 Python 包一样安装,并且不依赖于服务器。它优化了分析工作负载,速度快,并提供了许多其他好处。
2、文件夹结构和环境设置
我在 GitHub Codespaces 中构建了这个项目,但你可以在任何开发环境中完成相同任务。请注意,我将展示的语法是针对 Linux 环境 的。首先,创建一个文件夹,打开终端,并确保你位于刚刚创建的文件夹中。在 Codespace 中,你可以右键单击刚刚创建的文件夹并点击“在集成终端中打开”。一旦进入终端,我们将创建一个虚拟环境。创建虚拟环境可确保你始终拥有用于项目的正确版本和依赖项。
## 创建虚拟环境
python3 -m venv .venv
## 激活虚拟环境
source .venv/bin/activate
接下来,创建一个名为 data 和 db 的文件夹。我们稍后会在本文中再次提到这些;然而,这就是原始数据文件和我们将创建的数据库所在的位置。
现在,让我们创建一个 requirements.txt 文件。这将包含项目所需安装的所有库。
## requirements.txt 内容
requests
tenacity
python-dotenv
pandas
pyarrow
duckdb
tqdm
一旦创建了 requirements 文档,并且在激活的虚拟环境中,运行以下命令安装库。
pip install -r requirements.txt
接下来,我们将创建一个环境文件 (.env)。这就是我们存储 Financial Modeling Prep (FMP) API 密钥的地方。如果你正在跟随或构建,你需要一个 FMP API 密钥。请注意,你不需要将 API 密钥放在引号中;只需输入即可。
## .env 内容
FMP_API_KEY=<YOUR_API_KEY_HERE>
太好了!让我们做一个快速检查点。截至目前,我们已经安装了依赖项并设置了 API 密钥。当前的项目结构应该如下所示:
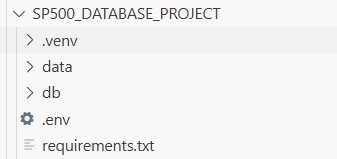
3、构建源(src)文件
这将是我们的项目的主“引擎”。以下 Python 程序将导入数据,正确存储它们,并创建初始数据库。我们将逐一介绍它们。
首先,在主目录中创建一个名为 “src” 的文件夹。将其视为我们自己的 Python 库,专为此项目而设。让我们开始构建。
第一个文件是 init.py。这个文件将完全空白。那么它的作用是什么?这是 Python 中的标准惯例,通常与主执行文件一起使用。当一个目录中存在 init.py 时,Python 会识别它,并允许将该目录中的所有内容直接导入到正在构建的主执行文件中。这使代码更加有组织,并且能够进行更动态的更改,而无需构建一个包含所有自定义函数的大执行文件,不仅适用于这个项目,也适用于任何项目。
3.1 config.py
配置文件将创建我们需要的所有主要变量。在这种情况下,变量用于 API 密钥和原始文件以及数据库的路径。请注意,我们正在创建原始 Parquet 文件,因为它们非常适合数据库,并且比 CSV 更高效。唯一的缺点是它们不能读取为 t,但这就是数据库的作用。
import os
from dotenv import load_dotenv
load_dotenv(override=False)
FMP_API_KEY = os.getenv("FMP_API_KEY", "").strip()
if not FMP_API_KEY:
raise RuntimeError("FMP_API_KEY not set. Add a Codespaces Secret or .env file.")
FMP_BASE = "https://financialmodelingprep.com/stable"
DATA_DIR = os.path.abspath(os.path.join(os.path.dirname(__file__), "..", "data"))
PARQUET_DIR = os.path.join(DATA_DIR, "parquet")
DB_DIR = os.path.abspath(os.path.join(os.path.dirname(__file__), "..", "db"))
DUCKDB_PATH = os.path.join(DB_DIR, "market.duckdb")
os.makedirs(PARQUET_DIR, exist_ok=True)
os.makedirs(DB_DIR, exist_ok=True)
3.2 fmp_client.py
此文件的主要功能是 fetch_sp500_constituents(),用于导入有关当前在 S&P 500 中的公司的几条信息。我们主要关心的是获取符号,但拥有其他变量也很有帮助,尤其是在未来扩展此数据库时。注意 _get 函数;这是用于直接调用 FMP API 端点。包装器函数允许我们在由于高流量或其他原因导致初始调用失败时尝试多次调用 API。
from typing import List, Dict
import requests
from tenacity import retry, wait_exponential, stop_after_attempt
from .config import FMP_API_KEY, FMP_BASE
HEADERS = {
"User-Agent": "sp500-data-import/0.1 (+github-codespaces)"
}
@retry(wait=wait_exponential(multiplier=1, min=1, max=20), stop=stop_after_attempt(5))
def _get(url: str, params: Dict = None) -> requests.Response:
"""Wrapper with retries & basic timeouts."""
resp = requests.get(url, params=params or {}, headers=HEADERS, timeout=30)
resp.raise_for_status()
return resp
def fetch_sp500_constituents() -> List[Dict]:
"""
Returns a list of dicts like:
{
"symbol": "...", "name": "...", "sector": "...",
"subSector": "...", "headQuarter": "...", "dateFirstAdded": "...",
"cik": "...", "founded": "..."
}
"""
url = f"{FMP_BASE}/sp500-constituent"
params = {"apikey": FMP_API_KEY}
r = _get(url, params=params)
data = r.json()
if not isinstance(data, list):
raise ValueError("Unexpected response for constituents endpoint.")
return data
3.3 prices_client.py
看起来熟悉吗?这个模块的行为与 fmp_client.py 类似,只是它用于导入给定符号的价格,特别是股息调整后的价格。
from typing import List, Dict
import requests
from tenacity import retry, wait_exponential, stop_after_attempt
from .config import FMP_API_KEY, FMP_BASE
HEADERS = {"User-Agent": "sp500-data-import/0.2 (+github-codespaces)"}
@retry(wait=wait_exponential(multiplier=1, min=1, max=20), stop=stop_after_attempt(5))
def _get(url: str, params: Dict = None) -> requests.Response:
resp = requests.get(url, params=params or {}, headers=HEADERS, timeout=30)
resp.raise_for_status()
return resp
def fetch_dividend_adjusted_prices(symbol: str) -> List[Dict]:
"""
Returns a list of dicts like:
{ "symbol": "AAPL", "date": "YYYY-MM-DD", "adjOpen": ..., "adjHigh": ..., "adjLow": ..., "adjClose": ..., "volume": ... }
"""
url = f"{FMP_BASE}/historical-price-eod/dividend-adjusted"
params = {"symbol": symbol, "apikey": FMP_API_KEY}
r = _get(url, params=params)
data = r.json()
if not isinstance(data, list):
raise ValueError(f"Unexpected response for {symbol}")
return data
3.4 rate_limit.py
我所使用的大多数 API 都有某种速率限制。关于我的 FMP 访问,有不同的速率限制,所以我们需要确保它可以动态处理。这个文件可以用来创建一个名为 MinuteRateLimiter 的对象,其中可以指定 API 使用情况并在每分钟内重置。
import time
import threading
from collections import deque
class MinuteRateLimiter:
"""
Allows up to `max_calls` within the trailing `window_seconds`.
Thread-safe. Call `acquire()` just before each API request.
"""
def __init__(self, max_calls: int = 750, window_seconds: int = 60):
self.max_calls = max_calls
self.window = window_seconds
self.lock = threading.Lock()
self.calls = deque() # timestamps (monotonic)
def acquire(self):
while True:
with self.lock:
now = time.monotonic()
# Drop old timestamps
while self.calls and now - self.calls[0] > self.window:
self.calls.popleft()
if len(self.calls) < self.max_calls:
self.calls.append(now)
return
# Need to wait until the oldest falls out of the window
sleep_for = self.window - (now - self.calls[0]) + 0.01
time.sleep(max(sleep_for, 0.05))
3.5 storage.py
这就是我们将导入的数据发送到我们的数据库 (market.duckdb) 的地方。正如你可能记得的那样,config.py 负责创建数据库的占位符文件。
import os
import duckdb
import pandas as pd
from typing import List, Dict
from .config import PARQUET_DIR, DUCKDB_PATH
CONSTI_PARQUET = os.path.join(PARQUET_DIR, "sp500_constituents.parquet")
def write_constituents_parquet(rows: List[Dict]) -> str:
"""Write/replace the constituents parquet with a normalized schema."""
if not rows:
raise ValueError("No rows to write.")
df = pd.DataFrame(rows)
# Keep a consistent schema & sensible column order
preferred_cols = [
"symbol", "name", "sector", "subSector",
"headQuarter", "dateFirstAdded", "cik", "founded"
]
for c in preferred_cols:
if c not in df.columns:
df[c] = pd.NA
df = df[preferred_cols].drop_duplicates(subset=["symbol"]).sort_values("symbol")
# Normalize dtypes
df["dateFirstAdded"] = pd.to_datetime(df["dateFirstAdded"], errors="coerce")
df["founded"] = pd.to_numeric(df["founded"], errors="coerce")
df.to_parquet(CONSTI_PARQUET, index=False)
return CONSTI_PARQUET
def ensure_duckdb() -> duckdb.DuckDBPyConnection:
"""Open (and create if needed) the DuckDB database and return a connection."""
con = duckdb.connect(DUCKDB_PATH)
return con
def register_parquet_tables(con: duckdb.DuckDBPyConnection) -> None:
"""
Create views that point to the parquet files.
In DuckDB you can query Parquet directly; views just make it ergonomic.
"""
# Inline the path; prepared parameters aren't allowed in CREATE VIEW.
# Escape any single quotes to keep SQL happy on odd paths.
from .config import PARQUET_DIR # if you want
constituents_path = CONSTI_PARQUET.replace("'", "''")
con.execute(f"""
CREATE OR REPLACE VIEW v_sp500_constituents AS
SELECT * FROM read_parquet('{constituents_path}');
""")
def bootstrap_duckdb() -> None:
"""One‑time bootstrap; safe to run repeatedly."""
con = ensure_duckdb()
register_parquet_tables(con)
con.close()
3.6 import_symbols.py
尽管我们只有几行代码,但请注意,这个特定的文件仅依赖于我们已经创建的模块。我们通过 fetch_sp500_constituents 从 FMP API 端点获取符号,并使用 write_constituents_parquet 和 bootstrap_duckdb 将其写入数据库。
from .fmp_client import fetch_sp500_constituents
from .storage import write_constituents_parquet, bootstrap_duckdb
def run():
rows = fetch_sp500_constituents()
path = write_constituents_parquet(rows)
bootstrap_duckdb()
print(f"✅ Wrote constituents to {path} and (re)registered DuckDB view.")
3.7 import_prices.py
正如你所看到的,导入价格将是一个更复杂的过程。首先,我们必须获取符号并确保价格数据的目录存在。同时注意 _merge_incremental 函数。每当运行此应用程序时,都会导入历史价格数据。当几天后再次运行此应用程序时会发生什么?已导入的价格历史保持不变;新导入的重复项被删除,从而保留了我们之前没有的历史记录。请注意,这只会适用于在脚本运行时包含在 S&P 500 指数中的符号。现在看一下 run 函数。这将一切协调在一起,并以并行方式运行过程。请注意,我们还创建了一个 MinuteRateLimiter 对象的实例,以确保我们遵守 API 限制。
import os
from typing import List, Dict, Tuple
import pandas as pd
import duckdb
from concurrent.futures import ThreadPoolExecutor, as_completed
from tqdm import tqdm
import threading
from .config import PARQUET_DIR, DUCKDB_PATH
from .storage import ensure_duckdb
from .prices_client import fetch_dividend_adjusted_prices
from .rate_limit import MinuteRateLimiter
PRICES_DIR = os.path.join(PARQUET_DIR, "prices")
os.makedirs(PRICES_DIR, exist_ok=True)
_write_lock = threading.Lock() # protect file writes per symbol
def _symbol_file(symbol: str) -> str:
return os.path.join(PRICES_DIR, f"{symbol.upper()}.parquet")
def _load_existing(symbol: str) -> pd.DataFrame:
path = _symbol_file(symbol)
if os.path.exists(path):
return pd.read_parquet(path)
return pd.DataFrame(columns=["symbol","date","adjOpen","adjHigh","adjLow","adjClose","volume"])
def _normalize(df: pd.DataFrame) -> pd.DataFrame:
# enforce column order & dtypes
cols = ["symbol","date","adjOpen","adjHigh","adjLow","adjClose","volume"]
for c in cols:
if c not in df.columns:
df[c] = pd.NA
df = df[cols]
df["date"] = pd.to_datetime(df["date"], errors="coerce")
# Sort oldest -> newest for readability
df = df.dropna(subset=["date"]).drop_duplicates(subset=["date"]).sort_values("date")
# Optional: cast volume to Int64
df["volume"] = pd.to_numeric(df["volume"], errors="coerce").astype("Int64")
for c in ["adjOpen","adjHigh","adjLow","adjClose"]:
df[c] = pd.to_numeric(df[c], errors="coerce")
return df
def _merge_incremental(existing: pd.DataFrame, new: pd.DataFrame) -> pd.DataFrame:
if existing.empty:
return _normalize(new)
# Outer concat then drop duplicates on date
merged = pd.concat([existing, new], ignore_index=True)
merged = _normalize(merged)
return merged
def _download_and_write(symbol: str, limiter: MinuteRateLimiter) -> Tuple[str, int]:
# Rate-limit before request
limiter.acquire()
data = fetch_dividend_adjusted_prices(symbol)
df_new = pd.DataFrame(data)
df_existing = _load_existing(symbol)
df_merged = _merge_incremental(df_existing, df_new)
path = _symbol_file(symbol)
with _write_lock:
df_merged.to_parquet(path, index=False)
return symbol, len(df_merged)
def load_symbols_from_duckdb() -> List[str]:
con = ensure_duckdb()
try:
rows = con.execute("SELECT symbol FROM v_sp500_constituents ORDER BY symbol").fetchall()
return [r[0] for r in rows]
finally:
con.close()
def register_prices_view():
con = ensure_duckdb()
try:
# Use a glob pattern to union all per-symbol price files
# read_parquet supports wildcard; missing files are fine if directory exists.
prices_glob = os.path.join(PRICES_DIR, "*.parquet").replace("'", "''")
con.execute(f"""
CREATE OR REPLACE VIEW v_prices AS
SELECT
CAST(date AS DATE) AS date,
UPPER(symbol) AS symbol,
adjOpen, adjHigh, adjLow, adjClose, volume
FROM read_parquet('{prices_glob}');
""")
finally:
con.close()
def run(max_workers: int = 16):
symbols = load_symbols_from_duckdb()
if not symbols:
raise RuntimeError("No symbols found in v_sp500_constituents. Run the symbols import first.")
limiter = MinuteRateLimiter(max_calls=740, window_seconds=60) # small buffer under 750
results = []
with ThreadPoolExecutor(max_workers=max_workers) as ex:
futures = {ex.submit(_download_and_write, sym, limiter): sym for sym in symbols}
with tqdm(total=len(futures), desc="Downloading prices", unit="sym") as pbar:
for fut in as_completed(futures):
sym = futures[fut]
try:
s, n = fut.result()
results.append((s, n))
except Exception as e:
results.append((sym, f"ERROR: {e}"))
finally:
pbar.update(1)
register_prices_view()
# Simple summary
ok = sum(1 for r in results if isinstance(r[1], int))
err = sum(1 for r in results if isinstance(r[1], str))
print(f"✅ Price import complete. Success: {ok}, Errors: {err}")
if err:
print("Examples of errors:", [r for r in results if isinstance(r[1], str)][:5])
4、Main.py 和 Prices.py
让我们做一个快速检查点。截至目前,我们的文件夹结构应该如下所示:
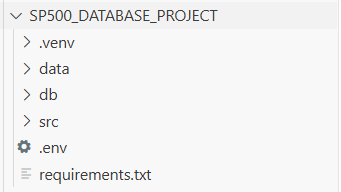
4.1 main.py
经过简要分析,这个文件似乎只是导入当前的 S&P 500 成分股。虽然这是事实,但它要么创建或刷新成分股的 parquet 文件,具体取决于是否是第一次运行。此外,这个脚本创建或刷新的文件是下一个脚本将直接引用以提取价格历史记录的文件。
from src.import_symbols import run as import_symbols_run
if __name__ == "__main__":
print("=== S&P 500 Data Import — Constituents ===")
import_symbols_run()
print("Done.")
4.2 prices.py
如前所述,这里是运行使用自定义 import_prices 模块导入价格数据的过程的地方。如果你回到 import_prices.py,你会注意到 _symbol_file 函数,它从 main.py 创建的 parquet 文件中提取符号。看看这一切是如何连接在一起的?
import argparse
from src.import_prices import run as run_prices
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Import dividend-adjusted historical prices for S&P 500")
parser.add_argument("--workers", type=int, default=16, help="Max parallel downloads (default: 16)")
args = parser.parse_args()
print("=== S&P 500 Data Import — Prices ===")
run_prices(max_workers=args.workers)
print("Done.")
5、初始执行和测试
现在,按顺序执行 main.py 和 prices.py 文件。
python main.py
python prices.py
假设没有错误,数据和 db 文件夹现在将填充成分股数据、价格数据和 duckdb 文件。
5.1 test_duckdb.py
测试是任何应用程序的重要组成部分。你不会在没有至少一次试驾的情况下购买一辆汽车,同样,对于任何类型的软件应用程序也是如此;至少应该是这样。在这个项目中,我们可以执行多种类型的测试;但目前,我们将运行一组简单的集成测试。更具体地说,我们将确保数据库可以摄取并从 parquet 文件中返回请求的信息,通过确认至少拉取了一个成分股,确保至少导入了一行价格,并最终查看某只股票的最新数据。要执行测试,请运行以下命令。此命令搜索目录中以“test_”开头的函数、文件或文件夹。这可能是一个 Python 文件,但如你所见,它正在执行 SQL 命令。请注意如何使用 duckdb.connect() 函数创建连接,通过 execute() 函数执行查询,最后使用 close() 关闭数据库连接。这是最终的文件结构:
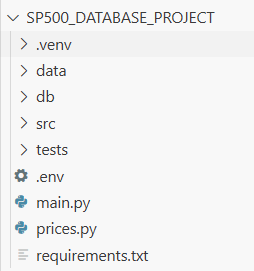
pytest -v
import duckdb
DB_PATH = "db/market.duckdb"
def test_constituents_exist():
con = duckdb.connect(DB_PATH)
count = con.execute("SELECT COUNT(*) FROM v_sp500_constituents").fetchone()[0]
con.close()
assert count > 0, "No constituents found. Did you run main.py?"
def test_prices_exist():
con = duckdb.connect(DB_PATH)
count = con.execute("SELECT COUNT(*) FROM v_prices").fetchone()[0]
con.close()
assert count > 0, "No price rows found. Did you run prices.py?"
def test_aapl_recent_rows():
con = duckdb.connect(DB_PATH)
df = con.execute("""
SELECT date, adjClose
FROM v_prices
WHERE symbol='AAPL'
ORDER BY date DESC
LIMIT 5
""").fetchdf()
con.close()
assert not df.empty, "No recent AAPL rows found"
6、结束语
希望你能从这个项目中找到一些实用价值!这段旅程远未结束。截至构建这个数据库应用,它将成为我未来构建和撰写的所有金融应用的官方起点。Financial Modeling Prep API 有许多其他数据点可以包含,将这些数据点纳入这个工具将是一段漫长而值得的旅程。敬请期待更多!
原文链接:How I Built a Personal Market Database with DuckDB and Parquet (Step by Step)
DefiPlot翻译整理,转载请标明出处
免责声明:本站资源仅用于学习目的,也不应被视为投资建议,读者在采取任何行动之前应自行研究并对自己的决定承担全部责任。


