用 NLP 和知识图谱分析加密社区
本文介绍一种解决方案,说明如何将 NLP 的强大功能与知识图谱结合起来,自动从Crypto相关文章中提取有价值的见解。
一键发币: x402兼容 | Aptos | X Layer | SUI | SOL | BNB | ETH | BASE | ARB | OP | Polygon | Avalanche
每天都有数百万篇文章和论文发表。虽然这些文章中隐藏着大量知识,但几乎不可能全部阅读。即使你只关注特定领域,也很难找到所有相关文章并阅读它们以获得有价值的见解。
但是,有些工具可以帮助你避免体力劳动并自动提取这些见解。当然,我说的是各种 NLP 工具和服务。
在这篇博文中,我将介绍一种解决方案,说明如何将 NLP 的强大功能与知识图谱结合起来,自动从相关文章中提取有价值的见解。
此解决方案适用于多种用例。例如,你可以创建一个业务监控工具来调查互联网对你自己公司或竞争对手的评价。如果你是投资者,你可以通过分析围绕你可能感兴趣的公司或加密货币的新闻来确定潜在的投资。不仅如此,你还可以将提取的信息提供给机器学习模型,以帮助你发现股票或加密货币的伟大投资。
我相信还有更多我还没有想到的应用程序。
在我之前的文章中,我已经提到过如何手动开发数据管道。虽然构建有效抓取互联网文章并使用 NLP 模型处理它们的数据管道可能需要数月时间,但我发现 Diffbot 解决方案可以在数小时内帮助你解决该问题。
Diffbot 的使命是通过抓取和分析整个互联网来构建世界上最大的知识图谱。然后,它提供 API 端点来搜索和检索相关文章或主题。如果你愿意,还可以使用他们的 API 来丰富数据,因为他们的知识图谱包含有关各种组织、人员、产品等的信息。
除此之外,他们还提供自然语言处理 API,可从文本中提取实体和关系。如果你读过我之前的任何博客文章,你已经知道我们将使用 Neo4j(一种原生图形数据库)来存储和分析提取的信息。
1、检索有关加密货币的文章
如前所述,我们将使用 Diffbot API 检索有关加密货币的文章。如果你想关注这篇文章,可以在他们的页面上创建一个免费试用帐户,这足以完成此处介绍的所有步骤。登录他们的门户后,你可以探索他们的可视化查询生成器界面并检查可用的内容。
Diffbot 的知识图谱 API 提供了大量数据。因此,你不仅可以搜索各种文章,还可以使用他们的 KG API 检索有关组织、产品、人员、工作等的信息。
下面的示例将检索带有标签加密货币的最新 5000 篇文章:
DIFF_TOKEN = "<Insert your Diffbot token>"
search_query = 'query=type%3AArticle+tags.label%3A"cryptocurrency"++sortBy%3Adate'
article_count = 5000
articles_per_request = 50
def get_articles(query, offset):
"""
Fetch relevant articles from Diffbot KG endpoint
"""
search_host = "https://kg.diffbot.com/kg/dql_endpoint?"
url = f"{search_host}{query}&token={DIFF_TOKEN}&from={offset}&size={articles_per_request}"
return requests.get(url).json()['data']
articles = []
for offset in range(0,article_count, articles_per_request):
articles.extend(get_articles(search_query, offset))我已在他们的可视化构建器中构建了搜索查询,并将其简单地复制到我的 Python 脚本中。这就是获取与你的用例相关的任意数量文章所需的所有代码。
2、使用 Google 翻译 API 翻译外文文章
检索到的文章来自世界各地,使用多种语言。
在下一步中,我们将使用 Google 翻译 API 将它们翻译成英文。你需要启用 Google 翻译 API 并创建 API 密钥。
请务必检查他们的定价,因为使用他们的翻译 API 最终比我预期的要多一点。我在其他网站上查看过定价,翻译一百万个字符通常需要 15 到 20 美元。
GOOGLE_API_KEY = "<insert your Google API KEY>"
translate_url = "https://translation.googleapis.com/language/translate/v2"
def translate(text, language):
"""
Translate text to English with Google Translate API.
If the text is already in English, simply return it.
"""
if language == 'en':
return text
data = {'q': text, 'target': 'en', 'format':'text', 'source': language, 'key': GOOGLE_API_KEY}
try:
response = requests.post(translate_url, data=data).json()
return response['data']['translations'][0]['translatedText']
except Exception as e:
print(response)
return None
# Google Translate API has a limit of 100kb per request
max_character_length = 95_000
for row in articles:
row['date'] = row.get('date').get('timestamp') if row.get('date') else None
row['translatedText'] = translate(row['text'][:max_character_length], row['language'])在进入 NLP 提取部分之前,我们将文章导入 Neo4j。
3、将文章导入 Neo4j
我建议你下载 Neo4j Desktop 或使用免费的 Neo4j AuraDB 云实例,这足以存储有关这 5000 篇文章的信息。首先,我们必须定义与 Neo4j 实例的连接。
# Define Neo4j connections
from neo4j import GraphDatabase
host = 'bolt://localhost:7687'
user = 'neo4j'
password = 'letmein'
driver = GraphDatabase.driver(host,auth=(user, password))
def run_query(query, params={}):
with driver.session() as session:
result = session.run(query, params)
return pd.DataFrame([r.values() for r in result], columns=result.keys())导入的图形模型将具有以下架构:
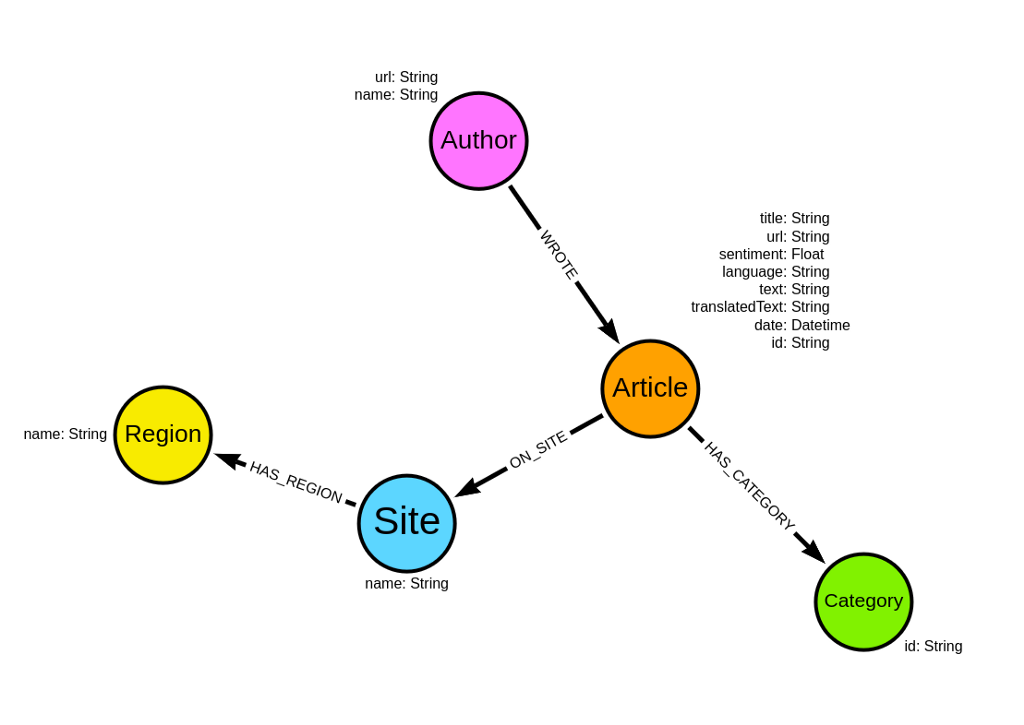
我们有一些关于文章的元数据。例如,我们知道论文的总体情绪以及发表时间。此外,对于大多数文章,我们知道谁写了它们以及在哪个网站上。最后,Diffbot API 还会返回文章的类别。
在继续之前,我们将在 Neo4j 中定义唯一约束,这将加快导入和后续查询的速度:
run_query("CREATE CONSTRAINT IF NOT EXISTS ON (a:Article) ASSERT a.id IS UNIQUE;")
run_query("CREATE CONSTRAINT IF NOT EXISTS ON (e:Entity) ASSERT e.id IS UNIQUE;")
run_query("CREATE CONSTRAINT IF NOT EXISTS ON (c:Category) ASSERT c.id IS UNIQUE;")
run_query("CREATE CONSTRAINT IF NOT EXISTS ON (a:Author) ASSERT a.url IS UNIQUE;")
run_query("CREATE CONSTRAINT IF NOT EXISTS ON (r:Region) ASSERT r.name IS UNIQUE;")
run_query("CREATE CONSTRAINT IF NOT EXISTS ON (s:Site) ASSERT s.name IS UNIQUE;")现在我们可以继续将文章导入 Neo4j:
import_articles_query = """
UNWIND $data as row
MERGE (a:Article {id: row.id})
SET a.title = row.title,
a.url = row.url,
a.sentiment = row.sentiment,
a.date = CASE WHEN row.date IS NOT NULL THEN datetime({epochMillis:row.date}) ELSE Null END,
a.language = row.language,
a.text = row.text,
a.translatedText = row.translatedText
MERGE (s:Site {name: row.siteName})
MERGE (a)-[:ON_SITE]->(s)
FOREACH (_ in case WHEN row.author_url IS NOT NULL THEN [1] ELSE [] END |
MERGE (au:Author {url: row.author_url})
ON CREATE SET au.name = row.author
MERGE (au)-[:WROTE]->(a))
FOREACH (_ in case WHEN row.publisherRegion IS NOT NULL THEN [1] ELSE [] END |
MERGE (r:Region {name: row.publisherRegion})
MERGE (s)-[:HAS_REGION]->(r))
WITH a, row.categories as categories
UNWIND categories AS category
MERGE (c:Category {id:category.id})
ON CREATE SET c.name = category.name
MERGE (a)-[:HAS_CATEGORY]->(c)
"""
run_query(import_articles_query, {'data': articles})我不会详细介绍上述 Cypher 查询的工作原理。相反,如果你感兴趣,可以参阅多篇博客文章,了解 Cypher 的介绍和图形导入。
我们可以检查一篇博客文章来验证图形模式模型:
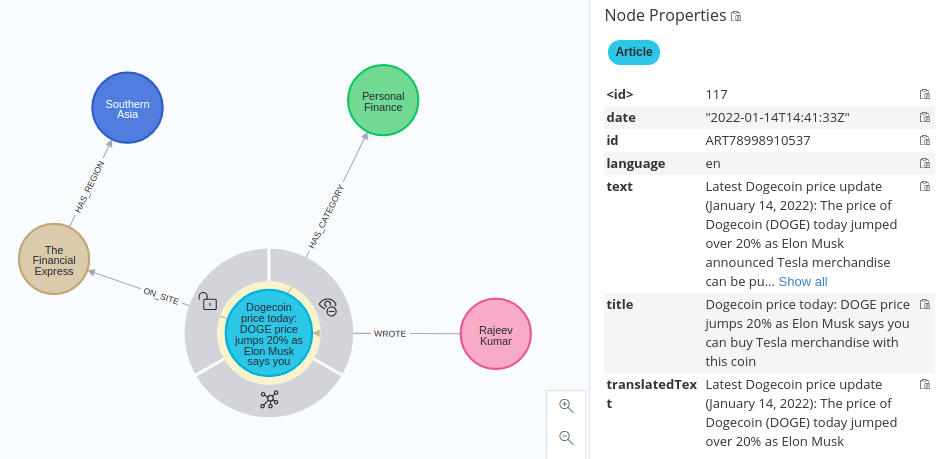
在进入文章的分析部分之前,我们将使用 NLP API 来提取实体和关系,或者用 Diffbot 的话说,事实。 Diffbot 网站提供了一个在线 NLP 演示,你可以在其中输入任何文本并评估结果。我输入了我们刚刚导入 Neo4j 的一篇文章的示例内容:
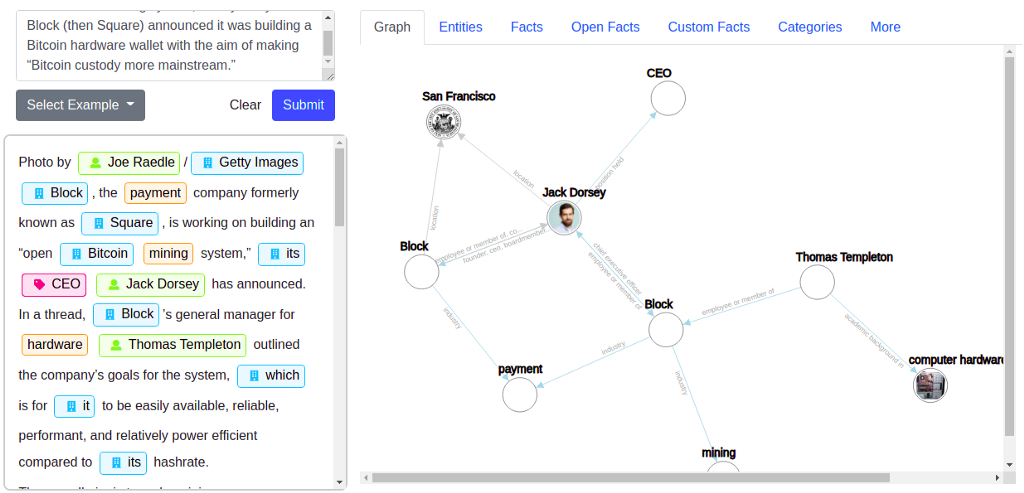
NLP API 将识别文本中出现的所有实体以及它们之间的可能关系,甚至以图形形式呈现。在这个例子中,我们可以看到 Jack Dorsey 是 Block 的首席执行官,该公司总部位于旧金山,负责支付和采矿业务。 Jack 在 Block 的同事是 Thomas Templeton,他有计算机硬件方面的背景。
要处理响应中的实体并将其存储到 Neo4j,我们将使用以下代码:
allowed_types = ['organization', 'person', 'location', 'product']
entity_confidence = 0.7
entity_query = """
MATCH (a:Article {id: $article_id})
WITH a
UNWIND $entities as e
MERGE (entity:Entity {id: e.id})
ON CREATE SET entity.name = e.name
WITH a, entity, e
CALL apoc.create.addLabels(entity, e.types) YIELD node
MERGE (a)-[m:MENTIONS]->(entity)
SET m.confidence = e.confidence,
m.salience = e.salience,
m.sentiment = e.sentiment
"""
def clean_and_store_entities(batch, response):
for article, nlp in zip(batch, response):
article_id = article['id']
# Skip processing if there are not entities found
if (not 'entities' in nlp) or (not nlp['entities']):
continue
entities = pd.DataFrame.from_dict(nlp['entities'])
# Filter allowed entity types and capitalize type names
entities['types'] = [[type['name'].capitalize() for type in types if type['name'] in allowed_types]
for types in entities['allTypes']]
# Filter entities without a type and confidence greater than entity confidence
entity_import = entities[[len(e['types']) > 0 and e['confidence'] >= entity_confidence for i,e in entities.iterrows()]]
# Filter persons who have only a single word
entity_import = entity_import[entity_import.apply(lambda x: ('Person' not in x['types']) or (len(x['name'].split(' '))) > 1, axis=1)]
# Define entity id
entity_import['id'] = [l['allUris'][0] if 0 < len(l['allUris']) else l['name'] for i, l in entity_import.iterrows()]
entity_params = {'article_id': article_id, 'entities': entity_import.to_dict('records')}
# Import to Neo4j
run_query(entity_query, entity_params)此示例将仅导入允许类型(例如组织、人员、产品和位置)且其置信度大于 0.7 的实体。据我所知,Diffbot 的 NLP API 还具有实体链接功能,其中实体链接到 Wikipedia、Crunchbase 或 LinkedIn。我们还将额外的实体类型作为附加标签添加到实体节点。
接下来,我们必须准备清理关系并将其导入 Neo4j 的函数:
skipProperties = ['gender', 'founding date', 'academic degree', 'age',
'cause of death', 'date of birth', 'date of death']
rel_confidence = 0.7
rels_query ="""
UNWIND $data as row
MATCH (s:Entity {id: row.source})
MATCH (t:Entity {id: row.target})
CALL apoc.merge.relationship(s, row.type,
{},
{},
t,
{}
)
YIELD rel
RETURN distinct 'done';
"""
def clean_and_store_rels(batch, response):
relParams = []
for article, nlp in zip(batch, response):
article_id = article['id']
if not 'facts' in nlp or len(nlp['facts']) == 0:
continue
facts = pd.DataFrame.from_dict(nlp['facts'])
# define confidence level
facts = facts[facts['confidence'] >= rel_confidence]
# Skip unrelated facts
facts = facts[facts['property'].apply(lambda x: x['name'] not in skipProperties)]
# skip if facts is empty
if len(facts) == 0:
continue
# Construct data
for i, row in facts[['entity', 'property', 'value']].iterrows():
source = row['entity']['name'] if len(row['entity']['allUris']) == 0 else row['entity']['allUris'][0]
target = row['value']['name'] if len(row['value']['allUris']) == 0 else row['value']['allUris'][0]
type = row['property']['name'].replace(' ', '_').upper()
relParams.append({'source':source,'target':target,'type':type})
run_query(rels_query, {'data': relParams})我省略了 skipProperties 列表中定义的属性的导入。对我来说,将它们存储为节点属性而不是实体之间的关系更有意义。但是,在此示例中,我们将在导入期间忽略它们。
现在我们已经准备好了导入实体和关系的函数,我们可以继续处理文章了。你可以在一个请求中发送多篇文章。我选择按 50 条内容批量处理请求:
step = 50
total = len(articles)
for offset in range(0, total, step):
batch = [el for el in articles[offset:offset + step] if el['translatedText']]
# Prepare payload
payload = [{'content': el['translatedText']} for el in batch]
# Make the request to Diffbot API
nlp_response = nlp_request(payload)
# Clean and store entities and facts in Neo4j
clean_and_store_entities(batch, nlp_response)
clean_and_store_rels(batch, nlp_response)通过遵循这些步骤,你已成功在 Neo4j 中构建了知识图谱。例如,我们可以可视化 Jack Dorsey 的邻里关系:
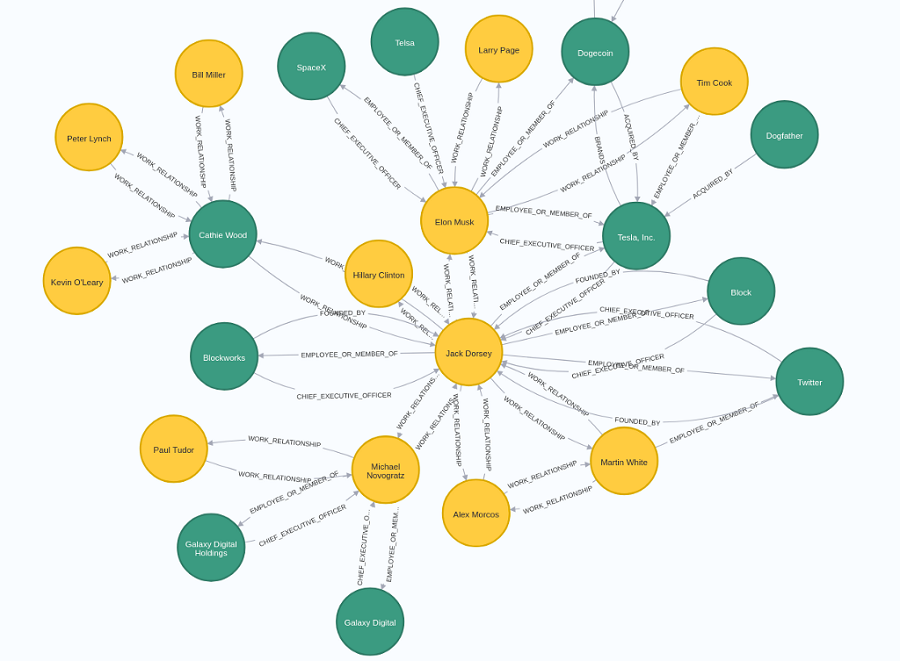
NLP 提取出 Jack Dorsey 是 Block 的首席执行官,并且与 Alex Morcos、Martin White 等人有工作关系。当然,并非所有提取的信息都是完美的。
我觉得有趣的是,NLP 将 Elon Musk 识别为 Dogecoin 的员工,无论如何这与事实相差不远。我没有尝试过事实的置信度,但你可以增加阈值以减少噪音。然而,这是一场精确度和召回率之间的游戏。
这只是示例子图。由于有太多可用信息,很难决定到底要显示什么。
4、图分析
在这篇文章的最后一部分,我将带你了解一些可以与这样的知识图一起使用的示例应用程序。首先,我们将评估文章的时间线:
MATCH (a:Article)
RETURN date(a.date) AS date,
count(*) AS count
ORDER BY date DESC
LIMIT 10结果如下:
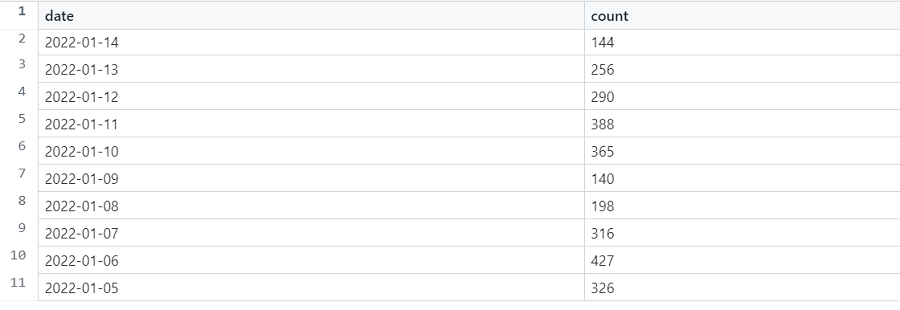
每天,全球有 150 到 450 篇关于加密货币的文章,这支持了我最初的说法,即这些文章的数量太多了,读不完。接下来,我们将评估文章中提到最频繁的实体。
MATCH (e:Entity)
RETURN e.name AS entity,
size((e)<-[:MENTIONS]-()) AS articles
ORDER BY articles
DESC LIMIT 5结果如下:

正如你从围绕加密货币的文章中所预料的那样,最常提到的实体是:
- 加密货币
- 比特币
- 以太坊
- 区块链
情绪既可以在文章层面也可以在实体层面上获得。例如,我们可以按地区分组检查有关比特币的情绪:
MATCH (e:Entity {name:'bitcoin'})<-[m:MENTIONS]-()-[:ON_SITE]->()-[:HAS_REGION]->(region)
WITH region.name AS region, m.sentiment AS sentiment
RETURN region, avg(sentiment) AS avgSentiment,
stdev(sentiment) AS stdSentiment,
max(sentiment) AS maxSentiment,
min(sentiment) AS minSentiment,
count(*) AS articles
ORDER BY articles DESC
LIMIT 5结果如下:

情绪总体上是积极的,但根据标准差值,不同文章之间的情绪波动很大。我们可以进一步探索比特币情绪。相反,我们将研究哪些人的平均情绪最高和最低,以及哪些人也出现在北美的大多数文章中。
MATCH (e:Person)<-[m:MENTIONS]-()-[:ON_SITE]->()-[:HAS_REGION]->(region)
WHERE region.name = "North America"
RETURN e.name AS entity,
count(*) AS articles,
avg(m.sentiment) AS sentiment
ORDER BY sentiment * articles DESC
LIMIT 5
UNION
MATCH (e:Person)<-[m:MENTIONS]-()-[:ON_SITE]->()-[:HAS_REGION]->(region)
WHERE region.name = "North America"
RETURN e.name AS entity,
count(*) AS articles,
avg(m.sentiment) AS sentiment
ORDER BY sentiment * articles ASC
LIMIT 5结果如下:
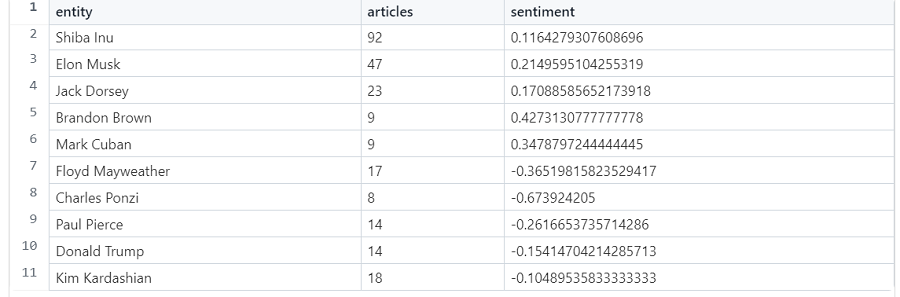
现在,我们可以探索一下例如出现马克·库班 (Mark Cuban) 的文章标题。
MATCH (site)<-[:ON_SITE]-(a:Article)-[m:MENTIONS]->(e:Entity {name: 'Mark Cuban'})
RETURN a.title AS title,
a.language AS language,
m.sentiment AS sentiment,
site.name AS site
ORDER BY sentiment DESC
LIMIT 5结果如下:
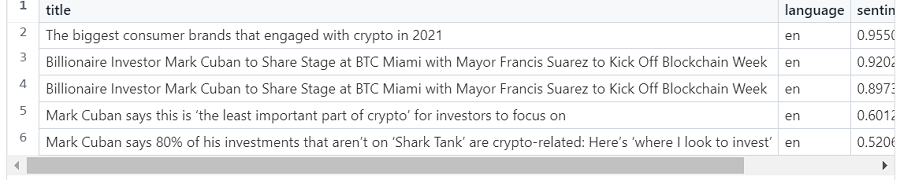
虽然标题本身可能不是最具描述性的,但我们也可以检查在提到马克库班的文章中哪些其他实体经常同时出现:
MATCH (o:Entity)<-[:MENTIONS]-(a:Article)-[m:MENTIONS]->(e:Entity {name: 'Mark Cuban'})
WITH o, count(*) AS countOfArticles
ORDER BY countOfArticles DESC
LIMIT 5
RETURN o.name AS entity, countOfArticles结果如下:

毫不奇怪,有各种加密代币。此外,达拉斯小牛队也出现了,这是马克拥有的 NBA 俱乐部。达拉斯小牛队是否支持加密,或者记者是否喜欢说马克拥有达拉斯小牛队,我不知道。你可以继续这种分析方式,但在这里,我们还将看看我们在 NLP 处理过程中提取了哪些事实:
MATCH p=(e:Entity {name: "Mark Cuban"})--(:Entity)
RETURN p结果如下:
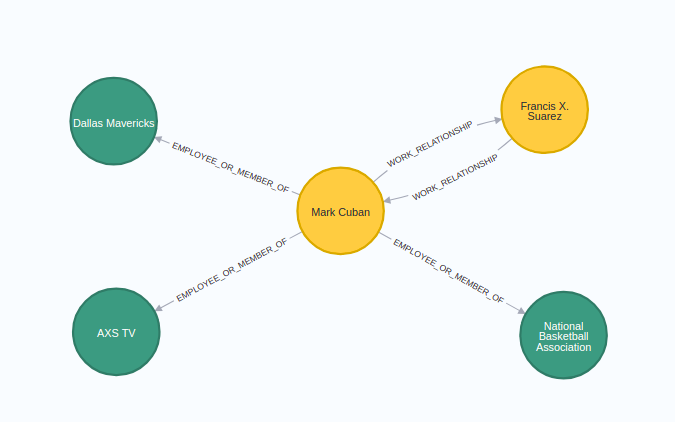
接下来,我们将快速评估出现 Floyd Mayweather 的文章标题,因为平均情绪相当低:
MATCH (a:Article)-[m:MENTIONS]->(e:Entity {name: 'Floyd Mayweather'})
RETURN a.title AS title, a.language AS language, m.sentiment AS sentiment
ORDER BY sentiment ASC
LIMIT 5结果如下:

似乎金·卡戴珊和弗洛伊德·梅威瑟因涉嫌加密货币诈骗而被起诉。 NLP 处理还可以识别各种代币和股票行情,因此我们可以分析当前哪些代币和股票最受欢迎以及它们的情绪:
MATCH (e:Entity)<-[m:MENTIONS]-()
WHERE (e)<-[:STOCK_SYMBOL]-()
RETURN e.name AS stock,
count(*) as mentions,
avg(m.sentiment) AS averageSentiment,
min(m.sentiment) AS minSentiment,
max(m.sentiment) AS maxSentiment
ORDER BY mentions DESC
LIMIT 5结果如下:

我只是粗略介绍了我们可以提取的可用见解。最后,我将添加两个可视化效果并提及一些你可以开发的应用程序:
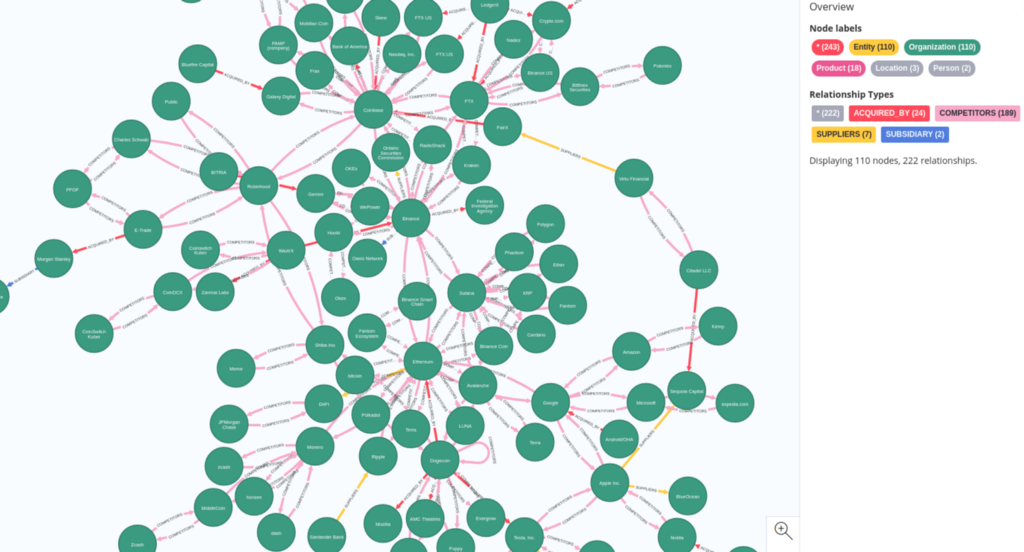
例如,你可以通过查看竞争对手、被收购方、供应商等关系来分析市场。另一方面,你可以将分析重点更多地放在图表中的人物身上,并评估他们的影响力或联系。
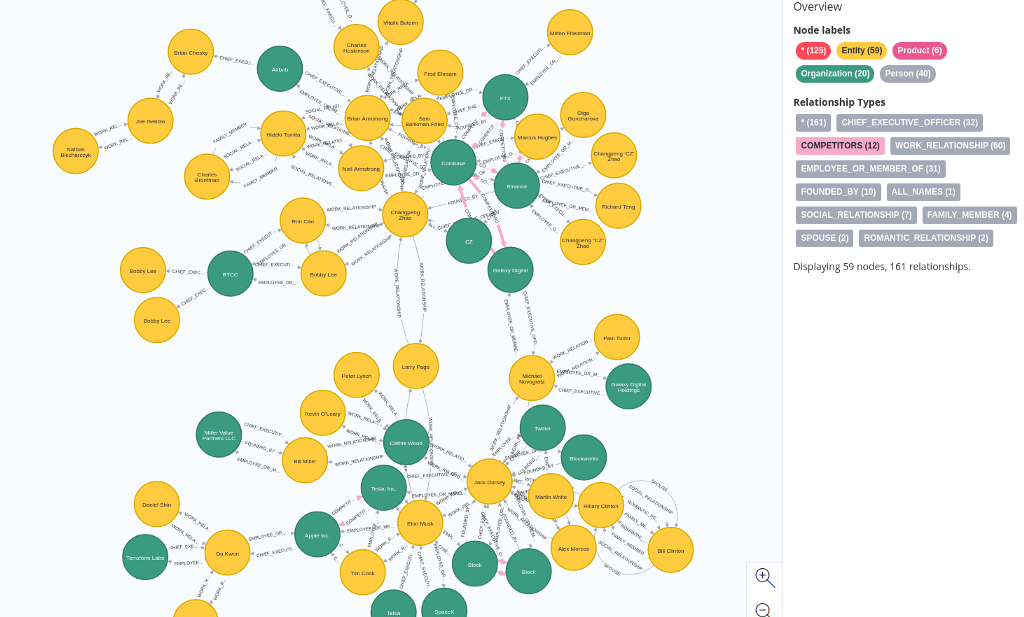
5、结束语
我只是触及了使用这些类型的数据管道进行分析的可能性的表面。如前所述,你可以监控有关你的公司、竞争对手、整个行业的新闻,甚至可以尝试预测未来事件(如收购)。不仅如此,你还可以使用提取的数据为你的机器学习模型提供所需的用例,例如预测加密趋势。
与往常一样,代码可在 GitHub 上找到。
原文链接:Monitoring the Cryptocurrency Space with NLP and Knowledge Graphs
DefiPlot翻译整理,转载请标明出处
免责声明:本站资源仅用于学习目的,也不应被视为投资建议,读者在采取任何行动之前应自行研究并对自己的决定承担全部责任。


