用图数据库分析 ETF 和公司关系
GraphDB 正在成为解决这两种方法挑战的解决方案。它们将实体存储为节点,关系存储为边,允许以多层结构清晰地组织信息及其连接。
一键发币: x402兼容 | Aptos | X Layer | SUI | SOL | BNB | ETH | BASE | ARB | OP | Polygon | Avalanche
一个广为接受的事实和当今常见的刻板印象是,数据就是王。在投资方面,显然为什么数据对于我们的策略优势至关重要。
在本文中,我们将不讨论如何获取数据,因为这非常简单。在旅程的开始,你可以轻松浏览互联网找到适合你需求的数据集。当这些不够时,你可以从专门的供应商如 FinancialModelingPrep 获取数据。所以,假设你已经拥有数据。接下来呢?你需要以一种能帮助你获得答案并可视化的方式存储它,以便理解模式和趋势。
存储数据的最常见方法是:
关系型数据库就像带有多个可以相互连接的表格的Excel电子表格。它们的优势在于这些链接,但缺点是需要大量维护,因为每当有新信息时都需要更新表。
NoSQL 数据库就像各种 JSON 文档的存储。通过一些巧妙的技术,你可以检索所有具有相似性的文档。优点是添加新信息很容易——只需将其插入文档中,与关系型数据库相比节省了时间。然而,缺点是数据之间的关系不那么清晰,很容易在数百万个文档中迷失方向。
然后我们有 GraphDB!
1、什么是 GraphDB,以及它如何用于投资
GraphDB 正在成为解决这两种方法挑战的解决方案。它们将实体存储为节点,关系存储为边,允许以多层结构清晰地组织信息及其连接。这使得查询和可视化变得高效且独特。
一个简单的例子,比如我们将在本文后面看到的例子,有助于更好地理解通过可视化 ETF 持有的资产及其重叠来理解。我们将为 ETF 和 COMPANY 创建节点,并建立称为 HOLDS 的关系。这种关系将从 ETF 指向 COMPANY。每个节点将包含一些基本信息:ETF 将具有其市值,而 COMPANY 将包括其市值和行业。此外,在关系(HOLDS)级别,我们将记录 ETF 投资于每个特定资产的百分比。
在我们进入实际例子之前,让我指出其他 GraphDB 会感兴趣的案例:
- 像上面那样,我们也可以记录行业暴露区域,以识别集中风险,
- 上传地区销售,以便绘制公司的特定地区的销售集中度,或者查看该地区的特定公司集中度。
2、Neo4J
在本文中,我们将使用最常用的 GraphDB 平台之一,即 Neo4J。选择这个的原因有很多
- 它是最成熟的图数据库之一
- 它有一个免费的云解决方案,我们将用于本文
- 它有一个 Python 连接器
- 它使用 Cypher 语言查询数据库
为了跟随这篇文章,您只需要开始免费注册 Neo4J AuroraDB。
3、收集数据
要将有意义的数据上传到 Neo4J,我们首先需要收集并将其转换为稍后更容易上传的格式。为此,我们将使用 FMP 的股票筛选器 API。
尽管这个练习的逻辑是尽可能多地上传 ETF 和其资产,但本文是为了展示方法,因此我们实际上会限制 ETF 及其资产的数量,使其可视化更容易理解。
让我们先进行导入:
import requests
import pandas as pd
import json
from typing import List, Dict, Any
from tqdm import tqdm
token = 'YOUR FMP TOKEN HERE'
然后,使用 FMP 筛选器,我们将识别资产管理超过 500 亿美元的 ETF。接下来,我们将从 ETF 信息 API 中检索行业暴露数据,并过滤出在科技行业有超过 30% 暴露的 ETF。
screener_url = 'https://financialmodelingprep.com/api/v3/stock-screener'
params = {
'apikey': token,
"country":"US",
'isEtf': True,
'marketCapMoreThan': 50_000_000_000
}
resp = requests.get(screener_url, params).json()
df_etfs = pd.DataFrame(resp)
def get_etf_industry_exposure(symbol: str, token: str) -> dict:
ret = {}
try:
url_info = f'https://financialmodelingprep.com/api/v4/etf-info?symbol={symbol}'
params_local = {'apikey': token}
r = requests.get(url_info, params=params_local)
data = r.json()
exposures = data[0]['sectorsList']
for exp in exposures:
ret[exp['industry']] = exp['exposure']
except Exception as e:
print(f'Error getting etf-information for {symbol}: {e}')
pass
return ret
all_industries = set()
etf_to_industry = {}
symbols = df_etfs['symbol'].dropna().astype(str).tolist()
for symb in symbols:
exp = get_etf_industry_exposure(symb, token)
etf_to_industry[symb] = exp
all_industries.update(exp.keys())
# Add columns for each industry exposure, prefixed to avoid collisions
industry_cols = [f'Industry_{ind}' for ind in sorted(all_industries)]
for col in industry_cols:
df_etfs[col] = 0.0
# Fill exposures
for idx, row in df_etfs.iterrows():
symb = row['symbol']
exp = etf_to_industry.get(symb, {})
for ind, val in exp.items():
col = f'Industry_{ind}'
if col in df_etfs.columns:
df_etfs.at[idx, col] = float(val)
df_etfs = df_etfs[df_etfs['Industry_Technology'] > 30]
下一步是使用相应的 FMP API 检索 ETF 的底层资产。为了确保相关性,我们只包括构成 ETF 组合超过 0.5% 的资产。
holdings_all: List[dict] = []
etf_holder_base = 'https://financialmodelingprep.com/api/v3/etf-holder/'
for sym in df_etfs['symbol'].dropna().astype(str).tolist():
url = f'{etf_holder_base}{sym}'
data = requests.get(url, params).json()
for item in data:
rec = dict(item) if isinstance(item, dict) else {'raw': item}
rec['etfSymbol'] = sym
holdings_all.append(rec)
df_holdings = pd.DataFrame(holdings_all)
df_holdings = df_holdings[df_holdings['weightPercentage'] > 0.5]
最后一步是使用 FMP API 获取每个资产的详细信息,这会获取资产的资料。
assert 'df_holdings' in globals(), "df_holdings not found. Run the holdings cell first."
company_info_url = 'https://financialmodelingprep.com/api/v3/profile/{}'
unique_assets = (
df_holdings.get('asset')
.dropna()
.astype(str)
.str.strip()
.unique()
.tolist()
)
print(f'Unique assets: {len(unique_assets)}')
records = []
for sym in unique_assets:
try:
r = requests.get(company_info_url.format(sym), params={'apikey': token})
data = r.json()
if isinstance(data, list) and data:
d = data[0]
elif isinstance(data, dict):
d = data
else:
d = {}
# Normalize keys and handle both mktCap/marketCap variants
rec = {
'symbol': d.get('symbol', sym),
'mktCap': d.get('mktCap', d.get('marketCap')),
'companyName': d.get('companyName'),
'sector': d.get('sector'),
}
except Exception:
rec = {'symbol': sym, 'mktCap': None, 'companyName': None, 'sector': None}
records.append(rec)
df_company_info = pd.DataFrame(records)
df_company_info = df_company_info.drop_duplicates(subset=['symbol']).reset_index(drop=True)
这样我们就有了上传到 Neo4J DB 所需的所有数据。
- DataFrame
df_etfs包含 ETF - DataFrame
df_holdings包含 ETF 到股票的链接 - DataFrame
df_company_info包含股票的数据
在将数据上传到 Neo4J 之前,我们需要进行最后一步。我们应该
- 将市场资本和持有的股份等数字字段转换为数字类型。
- 替换一些特殊字符以及符号中的空格,因为这些将用作连接节点和边的关系键。
df_etfs['symbol'] = df_etfs['symbol'].str.replace('/', '_').str.replace('.', '_').str.replace(' ', '_').str.replace('\\', '_').str.replace('-', '_')
df_etfs['marketCap'] = pd.to_numeric(df_etfs['marketCap'], errors='coerce').fillna(0)
df_holdings['etfSymbol'] = df_holdings['etfSymbol'].str.replace('/', '_').str.replace('.', '_').str.replace(' ', '_').str.replace('\\', '_').str.replace('-', '_')
df_holdings['asset'] = df_holdings['asset'].str.replace('/', '_').str.replace('.', '_').str.replace(' ', '_').str.replace('\\', '_').str.replace('-', '_')
df_holdings['sharesNumber'] = pd.to_numeric(df_holdings['sharesNumber'], errors='coerce').fillna(0)
df_holdings['weightPercentage'] = pd.to_numeric(df_holdings['weightPercentage'], errors='coerce').fillna(0)
df_company_info['symbol'] = df_company_info['symbol'].str.replace('/', '_').str.replace('.', '_').str.replace(' ', '_').str.replace('\\', '_').str.replace('-', '_')
df_company_info['mktCap'] = pd.to_numeric(df_company_info['mktCap'], errors='coerce').fillna(0)
4、上传到 Neo4J
现在我们已经准备好上传所有数据。我们首先应该安装 Python 模块,它将处理与数据库的连接。
pip install neo4j
我们现在使用 Python;我们应该连接到数据库。URI、实例名称和密码应该已经在创建 Neo4J 实例时获得。
URI = "YOUR INSTANCE URL"
AUTH = ("neo4j", "YOUR PASSWORD FROM NEO4J")
from neo4j import GraphDatabase
with GraphDatabase.driver(URI, auth=AUTH) as driver:
driver.verify_connectivity()
首先,我们将上传 ETFs
for index, row in tqdm(df_etfs.iterrows(), total=len(df_etfs)):
try:
query = f'CREATE (e_{row['symbol']}:ETF{{symbol:"{row['symbol']}", name:"{row['companyName']}", marketCap:{row['marketCap']}}})'
driver.execute_query(query,database_="neo4j",)
except Exception as e:
print(query)
print(e)
break
在数据库上执行的 Cypher 查询示例如下:
CREATE (e_QUAL:ETF{symbol:"QUAL", name:"iShares MSCI USA Quality Factor ETF", marketCap:54236893281})
现在我们应该上传股票:
for index, row in tqdm(df_company_info.iterrows(), total=len(df_company_info)):
try:
query = f'CREATE (c_{row['symbol']}:COMPANY{{symbol:"{row['symbol']}",name:"{row['companyName']}", sector:"{row['sector']}", marketCap:{row['mktCap']}}})'
driver.execute_query(query,database_="neo4j",)
except Exception as e:
print(query)
print(e)
break
最后,关系(边)
for index, row in tqdm(df_holdings.iterrows(), total=len(df_holdings)):
try:
query = f'CREATE (e_{row['etfSymbol']})-[:HOLDS {{sharesNumber:{row["sharesNumber"]}, weightPercentage:{row["weightPercentage"]}}}]->(c_{row["asset"]})'
driver.execute_query(query,database_="neo4j",)
except Exception as e:
print(query)
print(e)
break
创建关系的示例如下:
CREATE (e_QUAL)-[:HOLDS {sharesNumber:2786496.0, weightPercentage:0.522}]->(c_ED)
你会注意到这里的区别,以及如何清晰地将两个节点连接在一起,同时还能在关系级别添加诸如权重百分比等数据。
5、在 Neo4J 中的数据可视化
现在,你应该返回到你的 Neo4J 平台上的免费实例,并在“查询”菜单下,你应该能够看到以下内容。
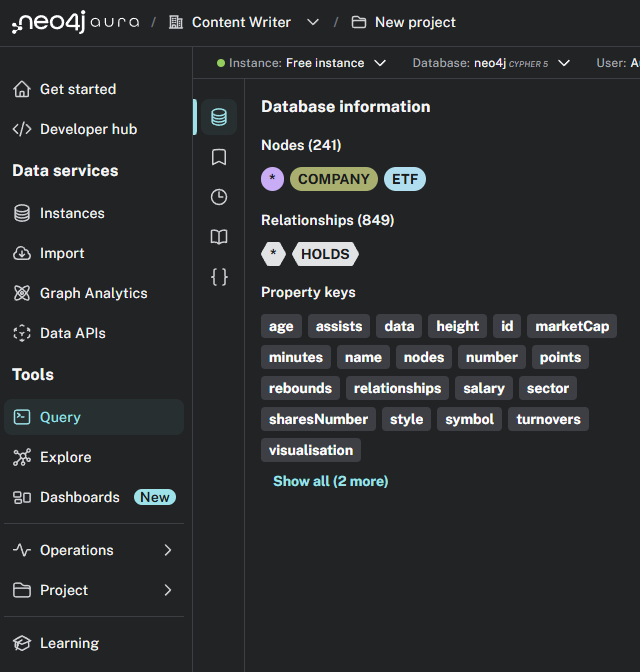
正如你所看到的,节点和关系应该已经上传!
现在,让我们观察可视化是如何工作的。让我们使用 Cypher 语言检索所有节点(ETF 和公司)。
MATCH (n) RETURN n;
实际上,这会检索所有节点(n)并返回它们。为了好玩,这类似于 SQL 中的 Select * from *,我们知道它会以什么方式结束。此查询将显示所有节点和关系,如下所示:
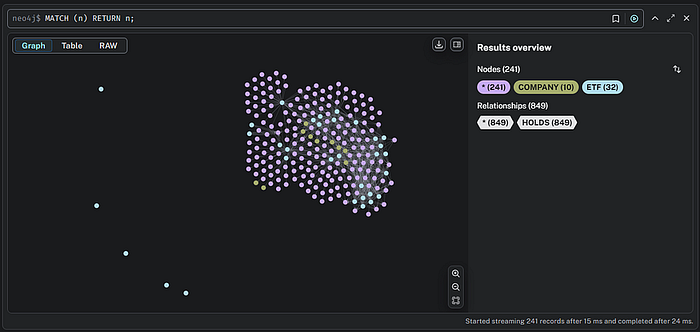
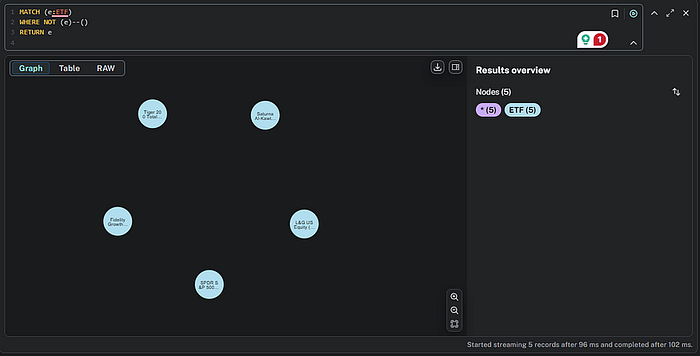
我们可以注意到的第一件事是那些没有关系的点。由于某种原因,这些 ETFS 没有返回任何资产。那么,让我们用 Cypher 查看是否可以隔离这些。
MATCH (e:ETF) WHERE NOT (e)--() RETURN e
这将可视化以下内容:
我们还可以可视化特定 ETF 的持仓。在我们的情况下,让我们尝试 VOO(Vanguard S&P 500 ETF)。
MATCH (etf:ETF {symbol: "VOO"})-[:HOLDS]->(company:COMPANY) RETURN etf, company
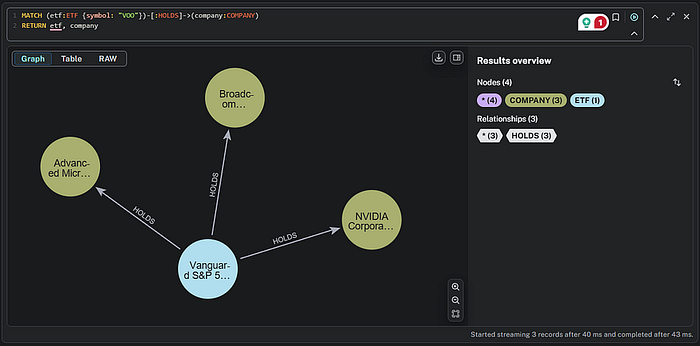
现在让我们探索更复杂的可视化。我将编写一个查询,包括所有持有 NVIDIA 的 ETF。我将使用名称“NVIDIA Corporation”来说明我们可以利用节点中的任何标签。
MATCH (company:COMPANY {name: "NVIDIA Corporation"})<-[:HOLDS]-(etf:ETF)-[:HOLDS]->(heldCompany:COMPANY)
RETURN DISTINCT etf, heldCompany
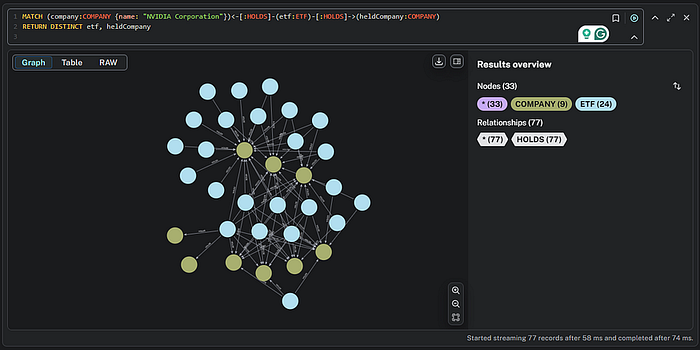
这是一个有趣的图表。去“玩”一下,放大或缩小图表,或者尝试移动节点。相信我,这会很有趣。然而,让我们看看从这个可视化中可以立即指出什么,而用其他方法则需要大量的努力,结果可能不确定。
在左下角有两个公司仅与一个 ETF 相连。放大后会更清楚我在说什么。
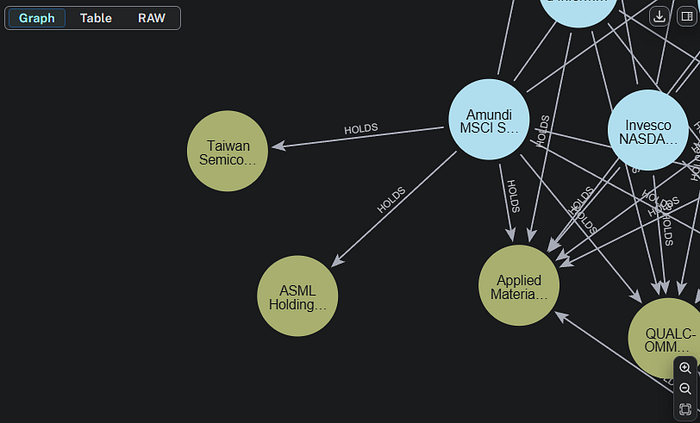
我们拥有的信息是,在所有包含 NVIDIA 的 ETF 中,只有 Amundi MSCI 持有台湾半导体和 ASML Holding,而其他 ETF 大多数都持有其他股票。对我来说,这值得对这两家公司进行调查。你觉得呢?
让我们做一个最终的例子。让我们显示按市值排名前五的 ETF 及其持仓。
MATCH (e:ETF)-[:HOLDS]->(c:COMPANY)
WITH e, collect(c) AS companies
ORDER BY e.marketCap DESC
LIMIT 5
RETURN e, companies
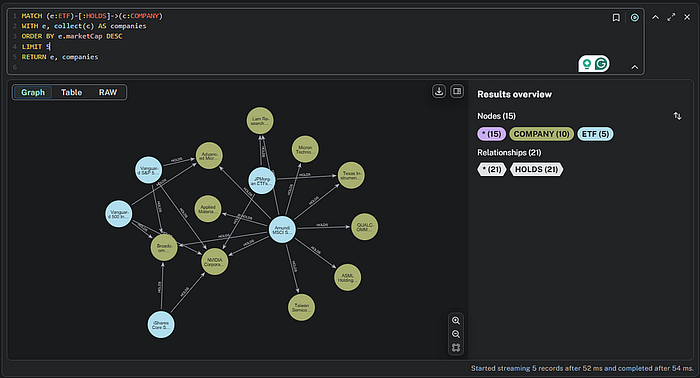
如果这是 SQL,它会产生一个包含所有公司的表格,我们需要运行一些计数和排序才能真正了解发生了什么。但是使这个可视化独特的是,通过这个简单的查询,你可以立即看到中间的两个蓝色 ETF(节点)是持有最多的,而左边的其他 ETF 持有最少。
6、除了可视化之外?
上述的一个简单例子展示了使用 GraphDB 可视化的强大功能。但这是否是唯一的好处?肯定不是。
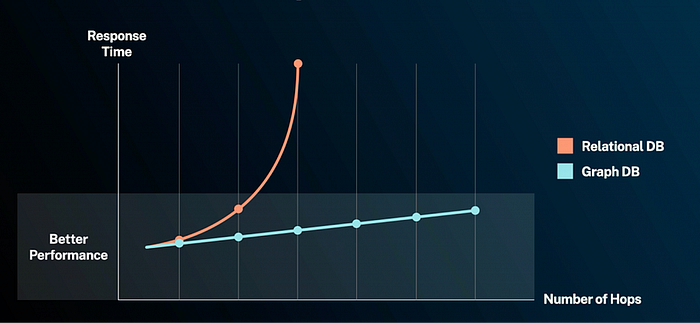
上面的图表,我们从 Neo4J 网站上获得,显示了基于查询“跳跃”的性能差异。跳跃是指我们从一条记录跳转到另一条记录的次数。例如,寻找我的朋友的朋友的朋友涉及每条记录的 3 次跳跃。现在想象一下,与之前的例子中数千只股票和 ETF 相比,这在图数据库中会快多少。
因此,Python 驱动程序已经覆盖了你。你可以像平常一样执行查询并解释结果。显然,不要期望这些是表格或数据框。让我们看一个之前查询的 Python 示例,即前五名 ETF。
query = """
MATCH (e:ETF)-[:HOLDS]->(c:COMPANY)
WITH e, collect(c) AS companies
ORDER BY e.marketCap DESC
LIMIT 5
RETURN e, companies
"""
def get_top_etfs_with_companies(tx):
result = tx.run(query)
for record in result:
etf = record["e"]
companies = record["companies"]
print(f"ETF Symbol: {etf.get('symbol')}, Market Cap: {etf.get('marketCap')}")
print("Holds Companies:")
for company in companies:
print(f" - {company.get('name')}")
print()
with driver.session() as session:
session.read_transaction(get_top_etfs_with_companies)
这将返回以下内容:
ETF Symbol: SEMG_L, Market Cap: 7316752931120
Holds Companies:
- NVIDIA Corporation
- Broadcom Inc.
- Taiwan Semiconductor Manufacturing Company Limited
- ASML Holding N.V.
- Advanced Micro Devices, Inc.
- Texas Instruments Incorporated
- QUALCOMM Incorporated
- Applied Materials, Inc.
- Micron Technology, Inc.
- Lam Research Corporation
ETF Symbol: VOO, Market Cap: 1326566414232
Holds Companies:
- NVIDIA Corporation
- Broadcom Inc.
- Advanced Micro Devices, Inc.
ETF Symbol: VFIAX, Market Cap: 1325308446655
Holds Companies:
- NVIDIA Corporation
- Broadcom Inc.
- Advanced Micro Devices, Inc.
ETF Symbol: JURE_L, Market Cap: 945886890977
Holds Companies:
- NVIDIA Corporation
- Texas Instruments Incorporated
- Lam Research Corporation
ETF Symbol: IVV, Market Cap: 659327809893
Holds Companies:
- NVIDIA Corporation
- Broadcom Inc.
7、结束语
本文主要是提供图数据库的可能性的高层次概述,以及如何将 FMP APIs 的广泛数据与 Neo4J 图数据库结合。你可以花几个小时研究具有复杂关系的数据集。
图数据库看起来提供了更好的可视化答案,其性能显而易见。所以如果“一张图片胜过千言万语”,“时间就是金钱”,那么图数据库必须是最好的讲故事者——节省时间、金钱,并永远避免枯燥的电子表格 ;)
话说回来,你已经读完了这篇文章。希望你今天学到了一些新的和有用的东西。感谢你的时间。
原文链接:How Python + GraphDB Transforms ETF and Company Relationship Analysis
DefiPlot翻译整理,转载请标明出处
免责声明:本站资源仅用于学习目的,也不应被视为投资建议,读者在采取任何行动之前应自行研究并对自己的决定承担全部责任。


