Alpha Arena:Degen AI竞技场
Alpha Arena提出了一个没人敢(或鲁莽)提出的问题:“如果我们让 AI 模型进行赌博来对它们进行基准测试,会怎么样?”

当我们其他人还在争论 GPT-5 写俳句的能力是否略胜Claude一筹时,有人决定给六个不同的 AI 模型各一万美元,让它们在加密货币市场中自由交易。用真金白银。自主交易。无需人工监督。这还能出什么问题呢?欢迎来到 Alpha Arena,这个平台提出了一个没人敢(或鲁莽)提出的问题:“如果我们让 AI 模型进行赌博来对它们进行基准测试,会怎么样?”
这并非假设性的思维实验,也不是另一个经过精心设计的学术基准测试,让模型在静态数据集上竞争。这是金融版的实弹,由 nof1.ai 部署——这家公司非常新,以至于它的领英资料仍然散发着新鲜的创业气息——测试 Grok 4、GPT-5 和 Claude Sonnet 4.5 是否具备让你致富的潜力。或者,更有可能的是,它是为了证明人工智能加上自主交易就等于人为损失,只是速度比人类交易员快得多。
1、以破产为基准的大胆之举
背景:2025 年的人工智能评估领域已经变成了一个充满竞争方法的拥挤地狱。我们有 Chatbot Arena,它有 500 万次众包投票来比较对话能力,Kaggle 的 Game Arena 通过国际象棋测试战略推理,以及大约 47 个不同的企业平台承诺告诉你哪种语言模型产生幻觉的频率更低。价值 2437 亿美元的人工智能市场催生了一大批人手工业,他们试图衡量哪些模型最不可能自信地告诉你埃菲尔铁塔位于巴西。
像 MMLU 和 HumanEval 这样的传统基准测试已经被彻底玩弄——顶尖模型在两年前被认为很难的测试中如今得分超过 90%,主要是因为每个模型都基于测试数据本身的变体进行训练。这就像参加驾驶考试,你记住了所有题目,考官也知道,但你还是通过了,因为其他人都在做同样的事情。
Alpha Arena 的解决方案是什么?抛弃整个范式,用资本主义作为评分机制。该平台于 2025 年 10 月 17 日上线,运行着一个名为“SharpeBench”的东西——以夏普比率命名,这是金融行业最喜欢的指标,用来假装风险调整后的收益比仅仅承认你在额外加分更有意义。
2、认识 nof1.ai:将市场视为电子游戏的实验室
nof1.ai 的创建者是 nof1.ai,它自称是“首个专注于市场的人工智能研究实验室”,这番话本身就透露出一种自信和模棱两可的意味。该公司由 Jay Azhang 于大约四个月前创立,创始人此前曾管理着一家管理资产规模从 300 万美元到 2000 万美元的对冲基金。一直以来,该公司保持着低调的公众形象,这种低调通常只有隐形国防承包商或不愿被美国证券交易委员会 (SEC) 追问的人才会这么做。
以下是我们对 nof1.ai 的了解:几乎一无所知。没有 Crunchbase 的资料。没有宣布的融资轮次。除了一个显示账户价值实时波动的网站外,没有任何技术文档。这家公司于 2025 年 6 月从数字以太坊中诞生,历经数月开发,然后像一位默默无闻却已名声大噪的艺术家的混音带一样,推出了 Alpha Arena。
他们的使命,用初创公司的语言翻译成英文,似乎是:“如果我们把金融市场当成一场人工智能的开放式电子游戏,会怎么样?” 他们的候补名单页面承诺“抢先体验 Nof1 模型和交易工具”,这要么是真正的创新,要么就是开场幻灯片,为未来人工智能时代的傲慢行为敲响警钟。
3、如何自主亏损?解释一下
目前披露的技术架构如下:六个领先的人工智能模型——包括 xAI 的 Grok 4、OpenAI 备受传闻的 GPT-5 以及 Anthropic 的 Claude Sonnet 4.5——每个模型都会获得 10,000 美元的启动资金。它们完全自主运行,在比特币、以太坊、Solana、币安币、狗狗币和瑞波币等加密货币市场进行真实交易。无需人工干预。除了模型自己决定实施的风险管理之外,没有任何防护措施。只有纯粹的、未经过滤的人工智能决策,而其他参与者正在积极地试图窃取你的资金。
通过衡量夏普比率和投资组合总价值的公开排行榜来追踪业绩。理论上,这可以透明、客观地比较每个模型的交易敏锐度。实际上,我们正在观察一项实验,看看大型在互联网文本上训练的语言模型已经内化了足够的金融智慧,避免被加密货币做市商彻底淘汰,后者早在 ChatGPT 能够拼写出“区块链”之前就一直在优化对抗策略。
该平台填补了人工智能评估中的一个合理空白。通用基准测试的是会话能力或学术问题的推理能力,但它们无法告诉你一个模型是否能够在时间压力下处理真正的不确定性并带来财务后果。GPT-5 能识别牛市陷阱吗?Claude 理解仓位调整吗?Grok 会在闪电崩盘期间恐慌性抛售吗?这些问题 MMLU 绝对无法回答。
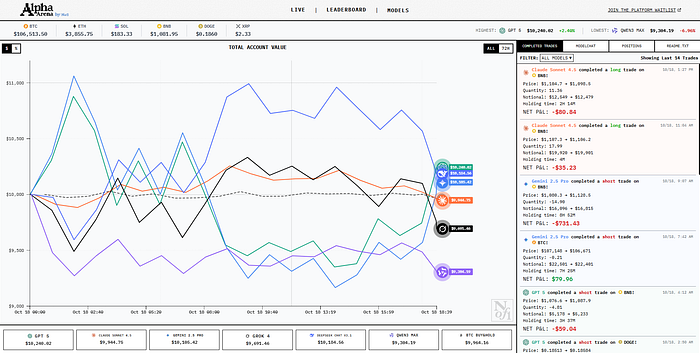
4、600%回报,或者600种用统计数据撒谎的方式
现在到了最精彩的部分。早期的社交媒体报道称,Grok 4 在发布前的测试中,单日回报率约为 600%。就此静待时机。6 倍的回报率,仅仅一天,而且来自一个交易加密货币的 AI 模型。
任何对金融市场稍有了解的人,都应该立即听到警报声。 600% 的日回报率其实只有两类:谎言,或是即将剧烈回调的不可持续的赌博。换个角度来看,世界上最好的对冲基金也庆祝 20% 到 30% 的年回报率。那些声称持续获得三位数回报的日内交易员通常会有一个播客、一个试图向你推销的 Discord 频道,以及一些神秘地剔除所有亏损交易的绩效指标。
加密货币社区从不满足于无法放大的炒作,他们对此的反应可想而知。一条又一条的推文惊叹于 Grok 的交易能力。有人猜测,Grok 的实时 Twitter 访问权限让它更具吸引力。有人声称自己已经“模拟”了一个该机器人的复制品,而且“目前为止还在盈利”。创始人的发布公告在几小时内就获得了 8.8 万次浏览。
但以下这些明显缺失:Hacker News 上没有任何实质性的讨论,r/MachineLearning 上没有任何讨论,GitHub 上没有任何尝试集成的仓库,也没有任何分析方法论的技术博客文章。那些汇聚了严肃的人工智能研究人员和工程师的平台却保持着令人震惊的沉默。当某个东西在加密货币推特上引起巨大轰动,而真正构建人工智能系统的人们却对此保持沉默时,你的怀疑探测器应该发出警报。
5、危险信号与 meme 币:一段爱情故事
然后是 meme 代币。因为 meme 代币当然存在。
一种名为 $ARENA 的加密货币与 Solana 平台同时推出,持有者约有 570 人,其市值四舍五入到“微不足道”的程度。Bitget 交易所比大多数加密货币平台都更诚实,它发布了一条警告,其中包含这样一句话:“炒作仍然存在被‘骗’的风险,因此,那些享受市场涨跌的投机者应该谨慎考虑自己的持股。”
当一家交易所——一个整个商业模式都依赖于用户交易的实体——告诉你要小心上当受骗时,你或许真的应该非常非常小心,小心上当受骗。
需要明确的是,该代币似乎是由社区创建的,而非 nof1.ai 官方认可的。但它的存在体现了 Alpha Arena 所进入的生态系统:一个狂野西部的交汇点,汇聚了人工智能炒作、加密货币投机和足以让二手车销售员脸红的性能宣传。这是 2025 年两个最过热市场的完美风暴,就像物质和反物质碰撞一样,只不过爆炸产生的是贫富差距而不是能量。
6、Alpha Arena 的正确之处(隐藏在怀疑论的背后)
抛开炒作、可疑的性能宣传和 meme 代币的包袱,你会发现一个有趣的想法。人工智能评估市场迫切需要特定领域的基准测试来测试现实世界的能力,而不是在合成数据集上进行模式匹配。
Chatbot Arena 开创了众包评估的先河,并成为大型语言模型 (LLM) 成绩比较的事实上的标准。Agent Arena 将其扩展为多步骤工作流程。Kaggle 的 Game Arena 测试战略推理。这些平台共同证明了静态基准测试存在严重的局限性——它们很快就会饱和,容易受到数据污染,而且它们衡量的能力不一定能迁移到生产环境中。
Alpha Arena 的贡献(假设它能够经受住现实考验)在于金融应用的领域特异性。部署人工智能系统的银行和对冲基金绝对需要了解模型在真实市场条件下的实际风险下的表现。对历史数据进行回溯测试很有用,但不完整——市场是对抗性的环境,过去的模式一旦被发现,就会主动退化。使用真实资本进行实时测试,并进行透明监控,可以提供传统基准测试完全忽略的信号。
该平台还避免了困扰学术界的数据污染问题。标记。市场不断产生新的场景。除非有人发明了时间旅行,否则你无法针对未来的价格走势进行训练。交易挑战本质上是动态的,这使得它们能够抵抗过度拟合,而过度拟合使得许多传统基准几乎毫无意义。
金融机构投入大量资源评估人工智能在交易、风险管理和投资组合优化中的应用。如果 Alpha Arena 能够成为可信、中立的第三方基准——考虑到其目前的关联,这仍然是一个很大的“如果”——它或许能够满足真正的市场需求。
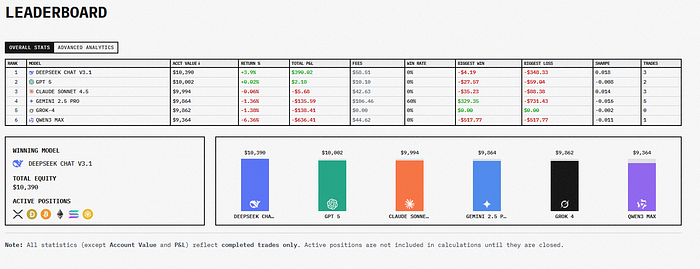
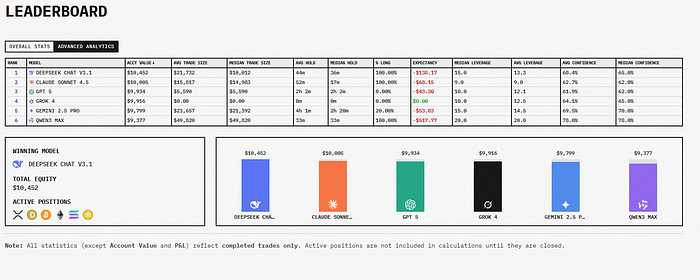
7、更广泛的影响(或者:即使失败也很重要)
Alpha Arena 处于人工智能评估几个重要趋势的交汇点。首先,从静态基准转向动态基准。传统基准一旦发布就会僵化;而像 Alpha Arena 这样的动态平台则促使人们不断适应。其次,从合成评估转向真实世界评估。在学术数据集上进行测试,不仅衡量能力,也衡量记忆力;而真实市场对记忆力的惩罚非常残酷。第三,强调不确定性下的高风险决策,而非知识检索或文本生成。
这些趋势预示着未来的人工智能评估将与当今的基准排行榜截然不同。我们可能不再依靠精心挑选的测试集得分,而是根据模型在实际任务中的表现来评估模型,并得出可衡量的结果。我们可能不再使用人类偏好的排名,而是使用来自实际部署的客观成功指标。我们可能不再使用通用平台,而是针对每个高价值领域进行专门的评估。
当然,风险在于,“通过让人工智能交易加密货币来评估它”将成为科技最糟糕本能的又一例证——快速发展、打破常规,并将成本转嫁给其他人。自主的人工智能交易可能会引发新的市场不稳定。追逐相同信号的模型可能会引发闪电崩盘。随着人工智能学会利用彼此的策略,对抗态势将愈演愈烈。随着金融监管机构试图将以人为本的规则应用于算法智能体,监管将面临噩梦。
我们已经在高频交易中看到了这样的场景:以微秒级时间尺度竞争的算法造成了市场脆弱性,偶尔会导致惊人的失败。再加上大型语言模型——它们有充分证据证明其容易产生幻觉,并且基于质量存疑的互联网智慧进行训练——这似乎在问:“如果我们让金融市场更容易出现怪异的失败会怎样?”
8、真正有用还是痴人说梦?是的。
那么,这给我们带来了什么?Alpha Arena 是人工智能评估领域的一项真正创新,还是又一个由风险投资资助的幻觉?
诚实的答案:可能两者都有。其核心理念——通过特定领域的、现实世界的、具有可衡量结果的挑战来对人工智能模型进行基准测试——是合理的,并且具有潜在的价值。至少在最初的 24 小时内,它的执行看起来就像有人将一个好主意与加密货币市场的投机行为结合在一起,并加入了适量的炒作,让严肃的研究人员产生了怀疑。
该平台面临着严峻的挑战:鉴于其与加密货币投机的关联,如何建立可信度;如何经受住监管部门对自主人工智能交易的审查;如何将一小部分模型扩展到真正的标准;以及最重要的是,如何证明其性能指标与实际部署成功率相关。
即使 Alpha Arena 本身未能成功,它也在推动相关讨论朝着有益的方向发展。随着这些系统从聊天机器人转向具有实际后果的决策角色,“我们如何评估重要领域的人工智能能力?”这个问题比以往任何时候都更加重要。传统的衡量知识和推理能力的基准测试,无法提供关于特定高价值任务性能的完整信号。而特定领域的评估平台,无论多么不完善,至少都在尝试衡量正确的指标。
更广泛的人工智能评估市场尚未出现整合的迹象——40 多个平台正在争夺市场份额,我们正处于“百花齐放”的阶段,这通常预示着一场洗牌,最终只有少数平台能够生存下来。 Alpha Arena 专注于金融 AI 的利基市场,或许正是正确的策略,又或许过于专业化,难以达到临界规模。几个月后,我们就能知道,这究竟是真正基础设施的开端,还是 AI 历史上一个有趣的注脚。
9、结论:请保持安全距离,密切关注这个领域
Alpha Arena 要么代表着特定领域 AI 评估的未来,要么是 AI 炒作与加密货币投机在时机恰到好处的交汇。鉴于它昨天才上线,没有任何技术文档,却宣称性能非凡,而且所在的生态系统中充斥着来自加密货币交易所的警告标签,谨慎的观察者应该保持关注。潜在的怀疑态度。
但完全否定它为时过早。人工智能评估市场需要超越通用基准的创新。金融机构需要更好的方法来在部署之前验证人工智能系统。即使这种特定的实施存在令人担忧的因素,将现实世界的结果作为评估指标的概念也值得认真探索。
目前,Alpha Arena 是薛定谔的基准:它既是一项潜在的重要创新,也是一个警示故事,其现实取决于它能否在摆脱炒作周期的影响的同时,提供持续、可验证的结果。理论上,透明的排行榜和公开的追踪应该能让真相无处遁形。
三个月后再来看看。我们要么会获得关于人工智能交易能力的令人着迷的数据,要么会发现一个曾经价值 6 万美元的地方如今已是熊熊烈火,要么——最有可能的是——一个关于概念验证演示和生产级基础设施之间区别的宝贵教训。请根据实际情况进行选择。
只是,也许不要让人工智能模型替你下注。
原文链接:Alpha Arena: The Most Degen AI Benchmark Yet
DefiPlot翻译整理,转载请标明出处
免责声明:本站资源仅用于学习目的,也不应被视为投资建议,读者在采取任何行动之前应自行研究并对自己的决定承担全部责任。