AI驱动的分层记忆交易者
与其强迫你选择日内交易本能和中线交易逻辑,LMT拥抱混乱。它生成三个“分析员”代理,每个都有自己的专长和记忆缓冲区,然后让他们进行讨论.

一键发币: x402兼容 | Aptos | X Layer | SUI | SOL | BNB | ETH | BASE | ARB | OP | Polygon | Avalanche
我原型化了一个开源的“分层记忆交易者”(LMT),它让三个专业代理;短期、中线和宏观——辩论交易,权衡他们的信心,并且只有在他们达成一致时才行动。这篇文章中没有真正的资金风险;结果仅限于回测,因此请将这里的所有内容视为研究,而不是投资建议。受Li等人2023年发表的《TradingGPT》论文的启发。如果你想深入挖掘或支持这个项目,请查看这个仓库 。
想象一下每个交易者都害怕的凌晨2点的分裂时刻。你昏昏欲睡地面对图表,RSI显示超卖,日线趋势仍然向下倾斜,你的直觉低语着反弹,而你的风险规则则低声说“保持空仓”。这种短期噪音与长期结构之间的拉锯战,硬性指标与直觉之间的冲突,让我在阅读《TradingGPT》论文后停下来思考,如果软件可以主持同样的内部辩论,记住每种论点,并且当声音最终达成一致时才行动会怎样? 追逐这个想法进入兔子洞,我创建了该论文的一个版本——LMT,即分层记忆交易者。
与其强迫你选择日内交易本能和中线交易逻辑,LMT拥抱混乱。它生成三个“分析员”代理,每个都有自己的专长和记忆缓冲区,然后让他们进行讨论:
- 短期代理 —— 依赖于分钟级动量,非常适合精确的入场和出场。
- 中线代理 —— 跟踪多日结构以过滤噪音并加强或否决快速信号。
- 宏观代理 —— 检查数周到数月的价格行为以及新闻情绪,以获得更大的图景。
只有当一个加权信心投票超过阈值时,LMT才会投入资金(目前是模拟资金)。
这是文章其余部分的路线图。
首先,我将展示原始价格数据是如何转化为指标丰富的数据帧的;
接下来,你将看到LMT如何保持三个精简但信息丰富的记忆缓冲区,分别用于短期、中线和宏观上下文。从那里,我们将深入讨论辩论引擎,其中代理们投下加权选票,决定是否留在场外或采取行动。
最后,我将剖析回测:收益曲线、夏普比率、回撤以及出现的错误。
无论你是寻找新架构的量化交易员,还是对AI好奇的自主交易员,LMT都展示了多代理思维如何推动交易系统。所以让我们开始吧。
1、系统概览
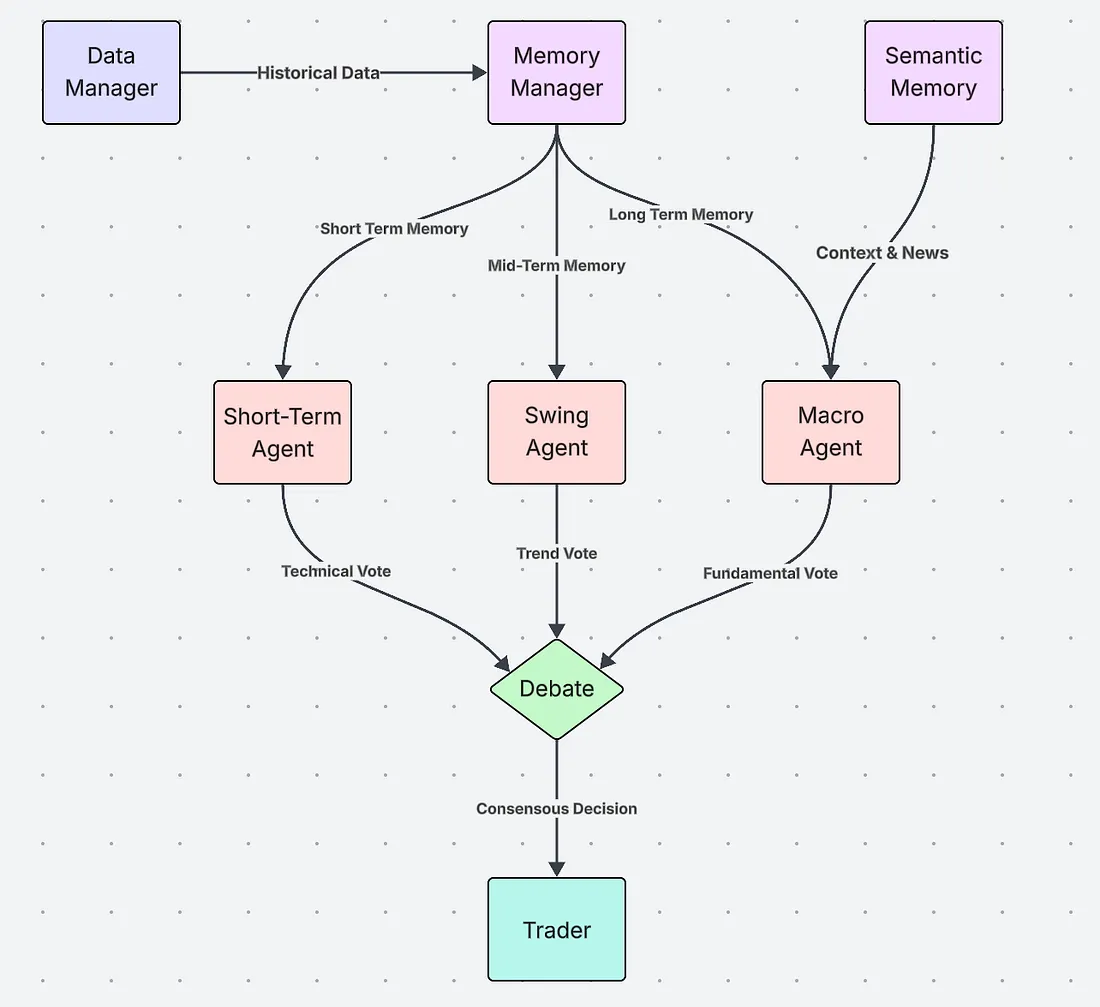
LMT从数据管理器开始,它提取原始蜡烛图和情绪数据,然后将所有内容传递给内存管理器,将其流划分为三个滚动缓冲区:短期、中线和长期。
- 短期代理 获取 < 60 分钟的缓冲区,寻找动量,并进行 技术 投票。
- 中线代理 依靠多日数据进行 趋势 投票。
- 宏观代理 阅读数周至数月的价格以及语义新闻向量,进行 基本面 投票。
这三个选票流入辩论引擎,运行一个加权信心选举。只有当净信念超过可配置的门槛时,交易模块才会发出订单(在我们的回测中是模拟的)。
1.1 数据摄入和市场情报收集
三个代理所知道的关于市场的所有信息都来自一个地方,这就是DataManager。它的任务简单但关键。首先,它加载历史蜡烛图(或以后的实时数据)以获取范围内的股票代码。其次,它将日期范围划分为训练集和测试集用于回测。第三,它提供一个函数 get_data_for_ticker(), 是一个帮助程序,每个代理都可以按需调用。下面是完整的类,你可以直接复制到你的项目中。
from data.price_fetcher import fetch_price_data
from data.sentiment_fetcher import fetch_sentiment_data
import pandas as pd
import time
import yaml
class DataManager:
def __init__(self, config, backtest_mode=None):
self.config = config
self.backtest_mode = backtest_mode
self.all_historical_data = pd.DataFrame()
self.tickers = []
if self.backtest_mode:
self._load_backtest_data()
def _load_backtest_data(self):
"""Loads and prepares historical data for backtesting."""
# Try to load data with news first, fallback to regular data
news_data_path = self.config['backtest'].get('news_data_path', 'historical_data_with_news.csv')
data_path = self.config['backtest']['full_data_path']
try:
print(f"Attempting to load data with news from {news_data_path}...")
self.all_historical_data = pd.read_csv(
news_data_path,
parse_dates=['time']
)
print(f"Successfully loaded data with news from {news_data_path}")
except FileNotFoundError:
print(f"News data not found at {news_data_path}, loading regular data from {data_path}...")
self.all_historical_data = pd.read_csv(
data_path,
parse_dates=['time']
)
# Add placeholder news column if not present
if 'news_summary' not in self.all_historical_data.columns:
self.all_historical_data['news_summary'] = 'No significant news'
self.tickers = self.all_historical_data['ticker'].unique()
if self.backtest_mode == 'train':
start_date = pd.to_datetime(self.config['backtest']['training_period']['start'])
end_date = pd.to_datetime(self.config['backtest']['training_period']['end'])
elif self.backtest_mode == 'test':
start_date = pd.to_datetime(self.config['backtest']['testing_period']['start'])
end_date = pd.to_datetime(self.config['backtest']['testing_period']['end'])
else:
raise ValueError("Invalid backtest mode specified. Choose 'train' or 'test'.")
self.all_historical_data = self.all_historical_data[
(self.all_historical_data['time'] >= start_date) &
(self.all_historical_data['time'] <= end_date)
]
self.backtest_iterator = self.all_historical_data.groupby('ticker')
print(f"Historical data for {self.backtest_mode}ing loaded for tickers: {self.tickers}.")
# Check if news data is available
if 'news_summary' in self.all_historical_data.columns:
news_count = self.all_historical_data['news_summary'].notna().sum()
print(f"News data available: {news_count} records with news information")
else:
print("No news data available in the dataset")
def get_data_for_ticker(self, ticker):
"""Returns the historical data for a specific ticker."""
if self.backtest_mode:
try:
return self.backtest_iterator.get_group(ticker).set_index('time')
except KeyError:
return pd.DataFrame()
else:
# Live mode would fetch data for a specific ticker
return pd.DataFrame()
if __name__ == '__main__':
with open('config.yaml', 'r') as f:
config = yaml.safe_load(f)
data_manager = DataManager(config, backtest_mode='train')
aapl_data = data_manager.get_data_for_ticker('AAPL')
print("AAPL Data:")
print(aapl_data.head())
一旦原始蜡烛图进入内存,LMT就会用一些动量和波动率信号来增强它们,每个代理都能理解:
# Technical indicator enhancement
ticker_data['rsi'] = calculate_rsi(ticker_data)
ticker_data['macd'], ticker_data['macd_signal'] = calculate_macd(ticker_data)
ticker_data['upper_band'], ticker_data['lower_band'] = calculate_bollinger_bands(ticker_data)
这个丰富后的框架将流入内存管理器,确保每个代理在投票之前不仅看到价格,还看到动量背景。
1.2 分层记忆
LMT的核心在于MemoryManager类,这是一个模仿人类交易者自然组织和回忆市场信息的组件。人类交易者不会把每一个tick都当作一样对待;他们保持日内脉搏、中线视角和长期观点,放在不同的心理桶里。LMT通过一个维护三个滚动缓冲区的MemoryManager来复制这种习惯,再加上一个反思日志用于交易后的笔记。
import pandas as pd
import yaml
class MemoryManager:
def __init__(self, horizons: dict):
self.horizons = horizons
self.short_term_memory = pd.DataFrame()
self.mid_term_memory = pd.DataFrame()
self.long_term_memory = pd.DataFrame()
self.reflection_memory = pd.DataFrame(columns=['timestamp', 'decision', 'confidence', 'outcome', 'reflection'])
def update_memory(self, new_data: pd.DataFrame):
"""
Updates all memory layers with new data and ensures they do not exceed their configured size.
:param new_data: A DataFrame containing the new data points to add.
"""
if new_data.empty:
return
# Update short-term memory
self.short_term_memory = pd.concat([self.short_term_memory, new_data])
if len(self.short_term_memory) > self.horizons['short_term']:
self.short_term_memory = self.short_term_memory.iloc[-self.horizons['short_term']:]
# Update mid-term memory
self.mid_term_memory = pd.concat([self.mid_term_memory, new_data])
if len(self.mid_term_memory) > self.horizons['mid_term']:
self.mid_term_memory = self.mid_term_memory.iloc[-self.horizons['mid_term']:]
# Update long-term memory
self.long_term_memory = pd.concat([self.long_term_memory, new_data]).tail(self.horizons['long_term'])
def add_reflection(self, timestamp, decision, confidence, outcome, reflection):
new_reflection = pd.DataFrame({
'timestamp': [timestamp],
'decision': [decision],
'confidence': [confidence],
'outcome': [outcome],
'reflection': [reflection]
})
self.reflection_memory = pd.concat([self.reflection_memory, new_reflection], ignore_index=True)
def get_memory_snapshot(self) -> dict:
"""
Returns a dictionary containing the current state of all memory layers.
"""
return {
'short_term': self.short_term_memory,
'mid_term': self.mid_term_memory,
'long_term': self.long_term_memory,
'reflections': self.reflection_memory
}
三个层次在实际中如何工作:
- 短期记忆 存储最新的tick —— 价格爆发、成交量飙升、动量变化 —— 所以日内代理可以快速出击而不被旧数据淹没。
- 中期记忆 保留几天到几周,让中线代理能够发现趋势延续、回调或新兴区间,这些是200根柱状图窗口可能错过的东西。
- 长期记忆 回溯几个月,给予宏观代理足够的背景来判断当前动作是小波动还是制度变化。
LMT避免了信息过载的经典陷阱,同时仍然保留每个代理真正需要的上下文,即如果它限制每个缓冲区到其时间范围。换句话说,每个分析师看到的正好是符合其职位描述的市场历史片段;不多不少。
1.3 专门的代理团队:不同的思想,共同的目标
一旦市场流被分配到三个记忆中,LMT就为每个时间范围分配了一个专门的分析师。每个代理都继承自同一个BaseAgent接口;因此它们共享日志、风险限制和配置解析,但每个代理都带来了自己的提示模板和投票逻辑。
from abc import ABC, abstractmethod
import pandas as pd
from memory.semantic_memory import SemanticMemory
class BaseAgent(ABC):
"""
Abstract base class for all trading agents.
"""
def __init__(self, name: str, config: dict, semantic_memory: SemanticMemory):
"""
Initializes the agent.
:param name: The name of the agent (e.g., "Short-Term Agent").
:param config: A configuration dictionary.
:param semantic_memory: An instance of SemanticMemory for searching textual data.
"""
self.name = name
self.config = config
self.semantic_memory = semantic_memory
短期代理: 这个代理像一个做市商一样思考。它扫描最近的几百根柱状图寻找突破和动量变化,然后询问一个轻量级的LLM提示进行二进制买入/卖出/持有并带有信心。高速度、高噪音、高决心。
import pandas as pd
from agents.base_agent import BaseAgent
from memory.semantic_memory import SemanticMemory
import google.generativeai as genai
import os
import re
genai.configure(api_key=os.getenv("GEMINI_API_KEY"))
class ShortTermAgent(BaseAgent):
"""
Agent focusing on short-term data to make trading decisions, using an LLM for analysis.
"""
def __init__(self, name: str, config: dict, semantic_memory: SemanticMemory):
super().__init__(name, config, semantic_memory)
self.model = genai.GenerativeModel('gemini-1.5-flash')
def vote(self, memory_snapshot: dict) -> tuple[str, float]:
"""
Analyzes short-term memory using an LLM to decide on a trading action.
"""
short_term_data = memory_snapshot.get('short_term')
if short_term_data is None or short_term_data.empty:
return 'HOLD', 0.5
ticker = short_term_data['ticker'].iloc[-1]
# Prepare the Prompt
prompt = f"You are a short-term momentum trader specializing in {ticker}. Based on the recent price action and technical indicators, what is your recommendation? Provide your answer as 'VOTE: [BUY/SELL/HOLD], CONFIDENCE: [0.0-1.0]'.\n\n"
prompt += f"Short-Term Price & Indicator Data for {ticker} (last 10 data points):\n"
prompt += short_term_data[['close', 'rsi', 'macd', 'upper_band', 'lower_band']].tail(10).to_string() + "\n"
# Get LLM Response
try:
response = self.model.generate_content(prompt)
# Parse the Response
vote_match = re.search(r"VOTE:\s*(BUY|SELL|HOLD)", response.text, re.IGNORECASE)
confidence_match = re.search(r"CONFIDENCE:\s*([0-9.]+)", response.text, re.IGNORECASE)
if vote_match and confidence_match:
vote = vote_match.group(1).upper()
confidence = float(confidence_match.group(1))
print(f"ShortTermAgent LLM Vote: {vote}, Confidence: {confidence}")
return vote, confidence
else:
print(f"ShortTermAgent: Could not parse LLM response: {response.text}")
return 'HOLD', 0.5
except Exception as e:
print(f"An error occurred while calling the Gemini API: {e}")
return 'HOLD', 0.5
中期代理: 这个代理生活在中间。它提取中期缓冲区,几天到几周,计算移动平均交叉、RSI分歧,并检查短期呼叫是否符合更广泛的模式。它的投票通常会缓和做市商的热情。
import pandas as pd
from agents.base_agent import BaseAgent
from memory.semantic_memory import SemanticMemory
import google.generativeai as genai
import os
import re
genai.configure(api_key=os.getenv("GEMINI_API_KEY"))
class MidTermAgent(BaseAgent):
"""
Agent focusing on mid-term data to make trading decisions, using an LLM for analysis.
"""
def __init__(self, name: str, config: dict, semantic_memory: SemanticMemory):
super().__init__(name, config, semantic_memory)
self.model = genai.GenerativeModel('gemini-1.5-flash')
def vote(self, memory_snapshot: dict) -> tuple[str, float]:
"""
Analyzes mid-term memory using an LLM to decide on a trading action.
"""
mid_term_data = memory_snapshot.get('mid_term')
if mid_term_data is None or mid_term_data.empty or len(mid_term_data) < 20:
return 'HOLD', 0.5
ticker = mid_term_data['ticker'].iloc[-1]
# Prepare the Prompt
prompt = f"You are a mid-term trend analyst specializing in {ticker}. Based on the following price data and technical indicators, what is your recommendation? Provide your answer as 'VOTE: [BUY/SELL/HOLD], CONFIDENCE: [0.0-1.0]'.\n\n"
# Add mid-term price trend with moving averages and RSI
prompt += f"Mid-Term Price & Indicator Data for {ticker} (last 20 data points):\n"
prompt += mid_term_data[['close', 'rsi', 'macd', 'upper_band', 'lower_band']].tail(20).to_string() + "\n\n"
prompt += "5-day Moving Average:\n"
prompt += mid_term_data['close'].rolling(window=5).mean().tail().to_string() + "\n\n"
prompt += "20-day Moving Average:\n"
prompt += mid_term_data['close'].rolling(window=20).mean().tail().to_string() + "\n"
# Get LLM Response
try:
response = self.model.generate_content(prompt)
# Parse the Response
vote_match = re.search(r"VOTE:\s*(BUY|SELL|HOLD)", response.text, re.IGNORECASE)
confidence_match = re.search(r"CONFIDENCE:\s*([0-9.]+)", response.text, re.IGNORECASE)
if vote_match and confidence_match:
vote = vote_match.group(1).upper()
confidence = float(confidence_match.group(1))
print(f"MidTermAgent LLM Vote: {vote}, Confidence: {confidence}")
return vote, confidence
else:
print(f"MidTermAgent: Could not parse LLM response: {response.text}")
return 'HOLD', 0.5
except Exception as e:
print(f"An error occurred while calling the Gemini API: {e}")
return 'HOLD', 0.5
宏观(长期)代理: 这个代理是战略家。它阅读数月的价格行为加上对近期新闻、美联储声明或收益讨论的语义搜索,存储在SemanticMemory类中。如果宏观观点大喊“避险”,它可以通过给出强烈的反向投票来推翻其他两个。
import pandas as pd
from agents.base_agent import BaseAgent
from memory.semantic_memory import SemanticMemory
import google.generativeai as genai
import os
import re
genai.configure(api_key=os.getenv("GEMINI_API_KEY"))
class LongTermAgent(BaseAgent):
"""
Agent focusing on long-term data and macroeconomic trends, using an LLM for analysis.
"""
def __init__(self, name: str, config: dict, semantic_memory: SemanticMemory):
super().__init__(name, config, semantic_memory)
self.model = genai.GenerativeModel('gemini-1.5-flash')
def vote(self, memory_snapshot: dict) -> tuple[str, float]:
"""
Analyzes long-term memory and semantic context using an LLM to decide on a trading action.
"""
long_term_data = memory_snapshot.get('long_term')
if long_term_data is None or long_term_data.empty:
return 'HOLD', 0.5
ticker = long_term_data['ticker'].iloc[-1]
# Prepare the Prompt
prompt = f"You are a long-term trading analyst specializing in {ticker}. Based on the following data, what is your recommendation? Provide your answer as 'VOTE: [BUY/SELL/HOLD], CONFIDENCE: [0.0-1.0]'.\n\n"
# Add long-term price trend
prompt += f"Long-Term Price & Indicator Data for {ticker} (last 10 data points):\n"
prompt += long_term_data[['close', 'rsi', 'macd', 'upper_band', 'lower_band']].tail(10).to_string() + "\n\n"
# Add semantic memory context
try:
semantic_results = self.semantic_memory.search_memory("market sentiment", k=3)
if semantic_results:
prompt += "Recent News & Reflections:\n"
for result in semantic_results:
prompt += f"- {result['text']} (distance: {result['distance']:.2f})\n"
except (IndexError, ValueError):
# Not enough memories to search or other value error
prompt += "No significant news or reflections found.\n"
# Get LLM Response
try:
response = self.model.generate_content(prompt)
# Parse the Response
vote_match = re.search(r"VOTE:\s*(BUY|SELL|HOLD)", response.text, re.IGNORECASE)
confidence_match = re.search(r"CONFIDENCE:\s*([0-9.]+)", response.text, re.IGNORECASE)
if vote_match and confidence_match:
vote = vote_match.group(1).upper()
confidence = float(confidence_match.group(1))
print(f"LongTermAgent LLM Vote: {vote}, Confidence: {confidence}")
return vote, confidence
else:
print(f"LongTermAgent: Could not parse LLM response: {response.text}")
return 'HOLD', 0.5
except Exception as e:
print(f"An error occurred while calling the Gemini API: {e}")
return 'HOLD', 0.5
因为所有三个代理都返回一个 (vote, confidence) 对,辩论引擎可以对它们进行对称处理,根据信念进行加权,找出僵局,并在共识较弱时选择不采取行动。这种思想多样性,而不是模型规模,是LMT的优势所在。
1.4 辩论:将三种意见转化为一次交易
每次代理投下 (vote, confidence) 对后,LMT进行一次加权选举,而不是简单的多数。逻辑类似于机构交易台:响亮的声音只有在它们也更加确定时才有意义。
from typing import List, Tuple
from agents.base_agent import BaseAgent
class Debate:
"""
Orchestrates a debate among trading agents to reach a consensus.
"""
def __init__(self, agents: List[BaseAgent]):
self.agents = agents
def run(self, memory_snapshot: dict) -> Tuple[str, float, List[dict]]:
"""
Gathers votes from all agents and determines the final decision using confidence weighting.
"""
votes = []
for agent in self.agents:
decision, confidence = agent.vote(memory_snapshot)
votes.append({'agent': agent.name, 'decision': decision, 'confidence': confidence})
final_decision, final_confidence = self._resolve_votes_with_weighting(votes)
return final_decision, final_confidence, votes
def _resolve_votes_with_weighting(self, votes: List[dict]) -> Tuple[str, float]:
"""
Resolves the collected votes into a single decision using confidence as a weight.
"""
if not votes:
return 'HOLD', 0.5
buy_strength = sum(v['confidence'] for v in votes if v['decision'] == 'BUY')
sell_strength = sum(v['confidence'] for v in votes if v['decision'] == 'SELL')
# Normalize by the sum of all confidences to get a weighted average
total_confidence = sum(v['confidence'] for v in votes)
if total_confidence == 0:
return 'HOLD', 0.0
# The final confidence is the difference between buy and sell strength, normalized
net_strength = buy_strength - sell_strength
final_confidence = abs(net_strength) / total_confidence
if net_strength > 0:
return 'BUY', final_confidence
elif net_strength < 0:
return 'SELL', final_confidence
else:
return 'HOLD', 1.0 - final_confidence # Confidence in HOLD is inverse of conviction
例如,假设短期代理热情地提出买入(0.9),中线代理反驳卖出(0.4),宏观代理选择持有(0.2)。
当辩论引擎汇总加权意见时,买入强度是0.9,卖出强度是0.4,净得分为0.5。除以总信心(0.9 + 0.4 = 1.3)得到大约0.56的整体信心,因此系统的裁决是买入,信心为56%。
至关重要的是,如果这个0.56的分数低于配置中设定的平均信心阈值,LMT只是站在一边;不交易,不折腾。这样,辩论层作为内置的风险控制,抑制冲动信号,并确保只有在集体信念真正稳固时才移动资金。
1.5 回测框架和性能分析
LMT只有在经过冷的、样本外的回测后才能证明其价值。我采用了2023-24年的价格历史,划分出干净的训练和测试窗口,并在“纸面经纪人”模式下运行每个代理,使用trader.py和evaluate.py,然后汇总下面的指标。
2、决策分布

图2显示了买入/卖出/持有的比例。大约40%的买入,16%的卖出,44%的持有告诉我们两件事:系统不是胆怯的,但它在信念薄弱时也会停放资金。这些持有部分是辩论层过滤掉低边缘噪声的直接结果。
3、代理与简单的买入并持有
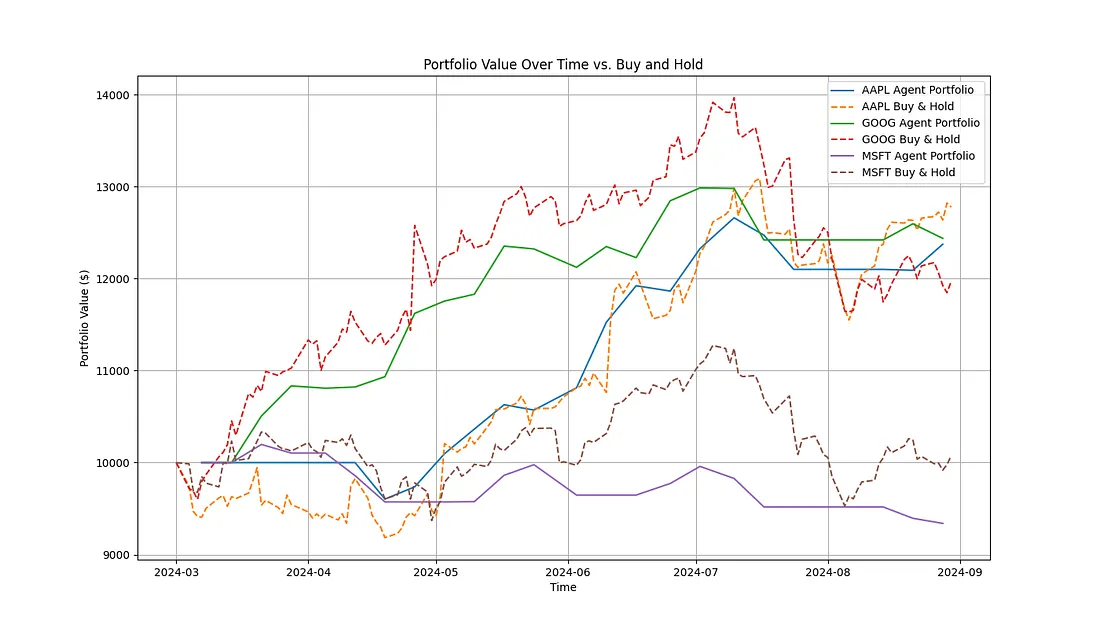
图3绘制了LMT的权益曲线与被动基准的对比。多代理堆栈避开了5月至6月的急剧下跌,并在动量回归时迅速重新部署,这是一种资本保存反应,你在静态的长期组合中永远看不到。
4、风险调整评分卡
LMT的评估生成了超越简单回报计算的全面性能分析:
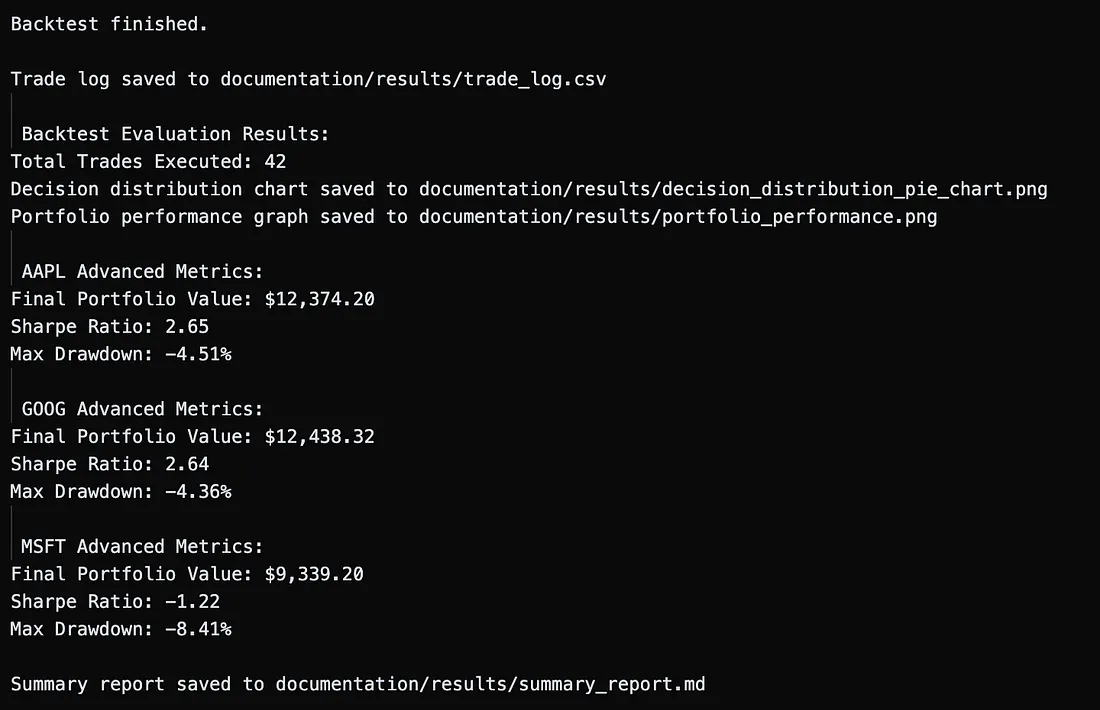
图4显示了主要数字:AAPL和GOOG的夏普比率约为2.6,最大回撤接近-4%(MSFT在糟糕的财报后达到-8%)。夏普比率超过2意味着回报超过了波动性,而单位数的回撤保持了心理和任何未来的仓位大小的稳定。
现实检验。 数据质量决定了这一切。在这个演示中,我依赖于免费的收盘数据对于AAPL、GOOG和MSFT,并用简单的插值填补了一些缺失的条目,没有高级的tick数据,没有机构新闻源,也没有实时填充。这在证明架构时是可以接受的,但你应该预期一旦你更换更高分辨率的数据、更广泛的宇宙和真实的执行成本,结果会非常不同。将上述曲线视为可行性信号,而不是性能承诺。
即使有这些注意事项,结果表明,分层记忆加上信心加权辩论可以做实际的工作,而不仅仅是拟合去年的记录。
5、实际实施考虑因素
- 摩擦成本。 实盘交易意味着佣金、买卖价差、价格滑点和偶尔的市场影响。在流动性差的标的中,这些可能会压倒优势。任何生产部署都需要一个经纪商API包装器,在正向测试期间模拟所有四种成本。
- 制度转变。 一个在低波动2021年数据上训练的模型在2022年的熊市或2020年的熔断中会挣扎。定期重新训练加上一个“健康检查”机制,当实时夏普比率下降时减少仓位规模,可以使系统与当前制度保持一致。
- 延迟与深度。 每根柱状图三个LLM提示在小时图上没问题;但在50毫秒的加密货币馈送中就是自杀。在低延迟环境中,你需要精炼、快速的标记(例如,OpenAI turbo 或本地 llama.cpp)或甚至为短期代理设置基于规则的备用方案。
- 硬件足迹。 存储数十个符号的数月tick级数据,加上语义记忆的嵌入向量,可能会超出单个GPU的VRAM。务实的分割是:指标和记忆在CPU-RAM上,小型LLM推理在GPU上,长期存档在S3或BigQuery中。
6、接下来可以推进的方向
- 更丰富的语义记忆。 引入实时RSS头条新闻、Reddit情绪和宏观日历,使宏观代理的新闻搜索真正实时。
- 自适应人物。 使用强化学习来学习代理的风险容忍度(甚至他们的提示),使其随着市场反馈进化,而不是保持静态。
- 跨资产投资组合。 使用Kelly缩放优化层在股票、期货和外汇之间进行仓位大小分配;相关性聚类可以阻止代理在同一因子赌注上加倍下注。
- 执行微服务。 一个轻量级的Go/Rust层,监听辩论决策并通过TWAP/VWAP切分订单,将研究堆栈变成真正的交易堆栈。
7、结束语
分层记忆交易者表明,认知启发的设计——专业化代理、限定记忆和信心加权辩论——比在图表上摆动线条能做得更多。在回测中,它在回撤中保护了资本,重新部署到动量中,并保持了风险指标的控制。它是否适合生产?绝对不是,除非有更好的数据、更严格的延迟和严肃的监控,但蓝图已经存在。随着市场变得更加嘈杂和数据丰富,能够思考交易而非仅仅计算指标的系统将拥有下一个优势。
原文链接:How I Built a Three‑Agent AI Trader That Argues With Itself Before Placing a Trade
DefiPlot翻译整理转载请标明出处
免责声明:本站资源仅用于学习目的,也不应被视为投资建议,读者在采取任何行动之前应自行研究并对自己的决定承担全部责任。


