用Python访问实时智能合约数据
假设你需要访问以太坊(或Polygon、BSC等)上某些智能合约的实时数据,比如Uniswap或甚至PEPE币,并使用标准的数据科学家/分析师工具:Python、Pandas、Matplotlib等来分析其数据。

一键发币: x402兼容 | Aptos | X Layer | SUI | SOL | BNB | ETH | BASE | ARB | OP | Polygon | Avalanche
假设你需要访问以太坊(或Polygon、BSC等)上某些智能合约的实时数据,比如Uniswap或甚至PEPE币,并使用标准的数据科学家/分析师工具:Python、Pandas、Matplotlib等来分析其数据。在这篇教程中,我将向你展示更高级的数据访问工具,这些工具更像是外科手术刀(The Graph子图),而不是众所周知的瑞士军刀(RPC节点访问)或锤子(现成的API)。我希望我的比喻不会让你感到害怕 😅。
在以太坊上有几种不同的方法可以访问数据:
- 使用像getBlockByNumber这样的RPC节点命令来获取低级区块信息,然后通过像web3.py这样的库访问智能合约数据。这种方法允许你逐块获取数据并将其存储在自己的数据库或CSV文件中。这种方式速度不快,解析流行的智能合约数据通常需要花费数年时间。
- 使用一些数据分析提供商如Dune,它们可以帮助你获取一些流行的智能合约数据,但并不是真正的实时数据。延迟可能达到几分钟。
- 使用一些现成的API,如NFT API/Token API/DeFi API。这通常是一个很好的选择,因为延迟通常较低。你可能遇到的唯一问题是所需的数据不可用。例如,并非所有变量都可以作为历史时间序列提供。
如果你仍然想要获得智能合约的实时数据,但对之前的解决方案不满意,因为你希望拥有以下所有内容:
- 低延迟数据(数据总是最新,在新区块被挖出后立即更新)
- 需要的自定义数据切片,任何现成的API都无法提供
- 不想手动逐块处理数据并处理区块重组
这就是The Graph子图的最佳应用场景。本质上,The Graph是一个去中心化的网络,可以通过支付GRT代币的方式以去中心化的方式访问智能合约数据。
但其底层技术称为子图(subgraph)的技术允许你将简单的描述(即需要保存哪些变量以供实时访问)转换为生产级别的ETL管道,该管道:
- 从区块链提取数据
- 将其保存到数据库中
- 通过GraphQL接口使数据可访问
- 在网络中的每个新区块被挖掘后更新数据
- 自动处理链重组
这是一个重大的突破。你不需要成为高度合格的数据工程师,熟悉EVM兼容的区块链,就可以设置整个工作流。
但让我们从一些现成的东西开始。如果有人已经开发了一个子图,帮助你访问所需的数据怎么办?
你可以前往The Graph托管服务网站,找到社区子图部分,尝试在你需要的协议上获取现有的子图。例如,让我们找到一个子图来访问Lido协议(它允许用户质押他们的以太坊而无需限制最低值32个以太坊,并且除了可以再次质押的代币外,还能相信这一点?😅)。
根据DeFiLlama的数据,Lido协议目前在TVL(总锁定价值——用于衡量锁定或质押在特定DeFi平台或DApp上的数字资产总价值的指标)方面排名首位。
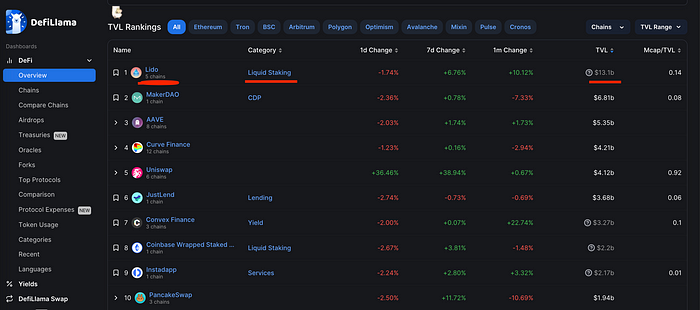
它就在那里!Lido团队制作的子图在这里。
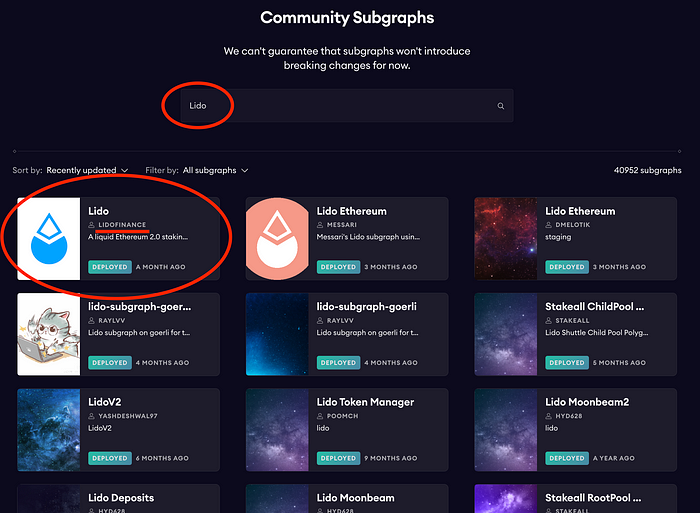
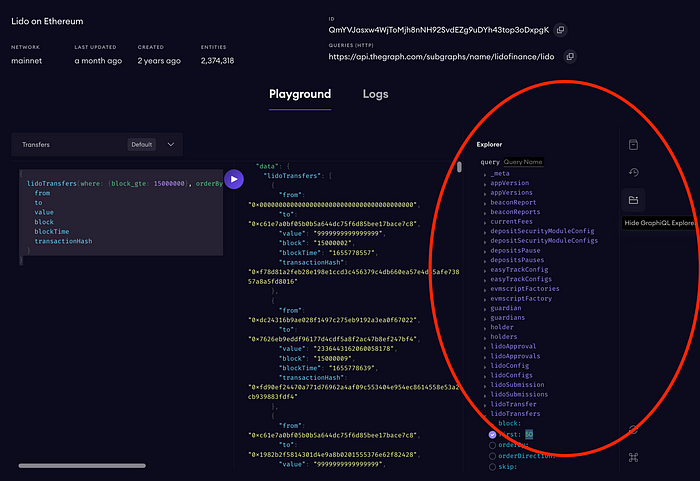
让我们进入子图详情页面。
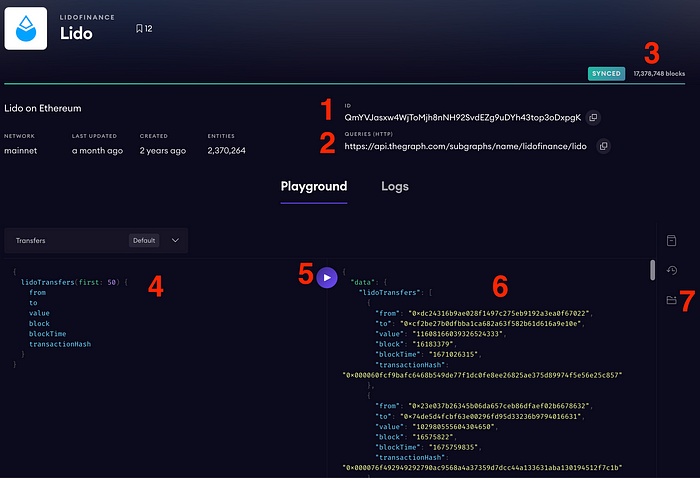
我们可以看到什么?
- 这个子图的IPFS CID——这是这个子图的内部唯一标识符,指向IPFS(点对点协议,通过哈希查找文件)上的这个子图清单(这是一个极度简化的解释,但你可以自己弄清楚它是如何工作的)。
- 查询URL——这是我们将在Python代码中使用的实际端点,以访问智能合约数据。
- 子图同步状态指示器。当子图是最新的时,你可以查询数据,但你应该明白部署一个新的子图后,必须等待一段时间才能同步。在此过程中,它会显示当前正在处理的区块数量。
- GraphQL查询。每个子图都有自己的数据结构(数据表的列表),在创建GraphQL查询时需要考虑这些结构。一般来说,GraphQL相当容易学习,但如果你觉得困难,可以请ChatGPT帮忙 🙂。
- 运行查询的按钮。
- 输出窗口。如你所见,GraphQL响应是一种类似JSON的结构。
- 一个开关,允许你查看此子图的数据结构。
让我们开始工作(让我们揭开我们的Jupyter笔记本🙂)。
获取原始数据:
import pandas as pd
import requests
def run_query(uri, query):
request = requests.post(uri, json={'query': query}, headers={"Content-Type": "application/json"})
if request.status_code == 200:
return request.json()
else:
raise Exception(f"Unexpected status code returned: {request.status_code}")
url = "https://api.thegraph.com/subgraphs/name/lidofinance/lido"
query = """{
lidoTransfers(first: 50) {
from
to
value
block
blockTime
transactionHash
}
}"""
result = run_query(url, query)
结果变量看起来像这样:
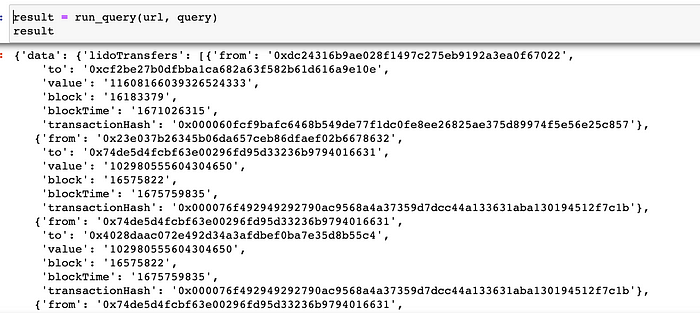
最后的转换(仅适用于扁平JSON响应)创建了一个数据框:
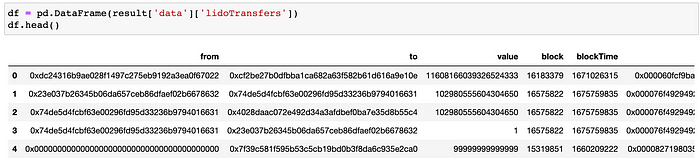
df = pd.DataFrame(result['data']['lidoTransfers'])
df.head()
但如果要从表格中下载所有数据呢?GraphQL有多种方法可以实现这一点,我选择了以下方法。考虑到区块是升序排列的,让我们从第一个区块开始,每次查询1000个实体(1000是graph-node的限制)。
query = """{
lidoTransfers(orderBy: block, orderDirection: asc, first: 1) {
block
}
}"""
# 这里我们得到第一个区块号开始
first_block = int(run_query(url, query)['data']['lidoTransfers'][0]['block'])
current_last_block = 17379510
# 生成连续查询的模板
query_template = """{{
lidoTransfers(where: {{block_gte: {block_x} }}, orderBy: block, orderDirection: asc, first: 1000) {{
from
to
value
block
blockTime
transactionHash
}}
}}"""
result = [] # 存储响应
offset = first_block # 从第一个找到的区块开始
while True:
query = query_template.format(block_x=offset) # 生成查询
sub_result = run_query(url, query)['data']['lidoTransfers'] # 获取数据
if len(sub_result)<=1: # 如果完成则退出
break
sh = int(sub_result[-1]['block']) - offset # 计算偏移量
offset = int(sub_result[-1]['block']) # 计算新的偏移量
result.extend(sub_result) # 添加
print(f"{(offset-first_block)/(current_last_block - first_block)* 100:.1f}%, got {len(sub_result)} lines, block shift {sh}" ) # 显示日志
# 转换为数据框
df = pd.DataFrame(result)
请注意,我们进行重叠查询,因为我们每次使用查询的最后一个区块号来开始下一个查询。我们这样做是为了避免由于每块可能有多笔交易而导致记录丢失。

正如我们所见,每次查询返回1000行,但区块号变化了几万个。这意味着并非每个区块都至少包含一笔Lido交易。这里的重要步骤是去除我们收集的重复项,以避免遗漏记录:
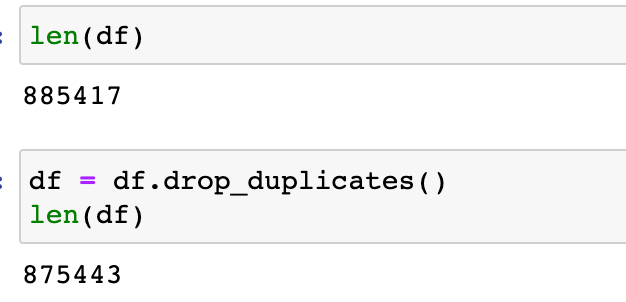
如我们所见,数据框中有9k+条重复行。
现在让我们做一些简单的EDA。
col = "from"
df.groupby(col, as_index=False)\
.agg({'transactionHash': 'count'})\
.sort_values('transactionHash', ascending=False)\
.head(5)

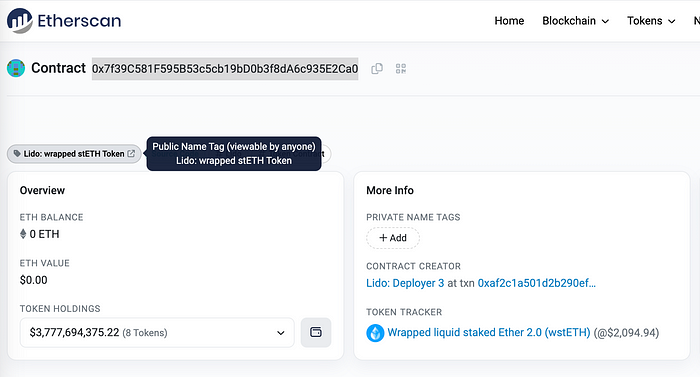
如果我们检查“from”字段中最频繁的地址,我们会发现“0x0000000000000000000000000000000000000000”地址。通常这意味着新代币的问题,因此我们可以在Etherscan中找到一笔交易并检查:
(df[df['from']=='0x0000000000000000000000000000000000000000'].iloc[1000].to,\
df[df['from']=='0x0000000000000000000000000000000000000000'].iloc[1000].transactionHash,
df[df['from']=='0x0000000000000000000000000000000000000000'].iloc[1000].value,)

我们将看到具有相同“value”的交易:
同样,检查“to”字段中最频繁的资金接收者也很有趣:
col = "to"
df.groupby(col, as_index=False)\
.agg({'transactionHash': 'count'})\
.sort_values('transactionHash', ascending=False)\
.head(5)
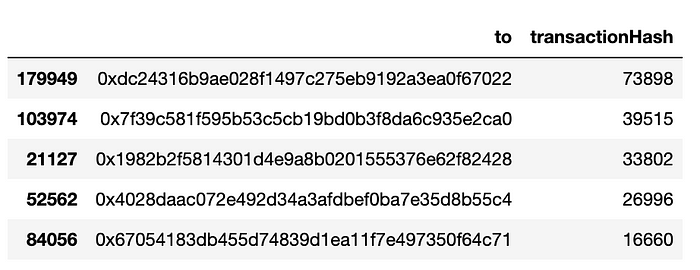
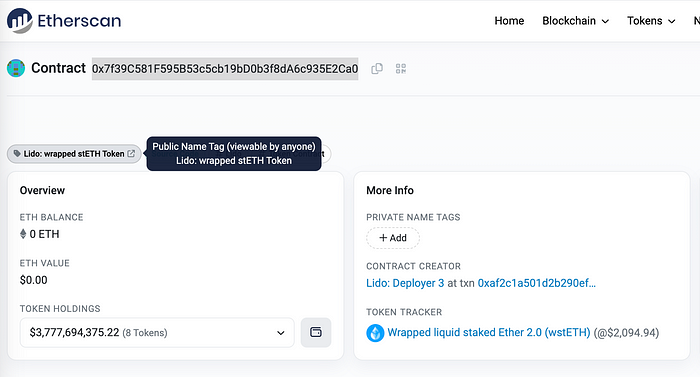
地址“0x7f39c581f595b53c5cb19bd0b3f8da6c935e2ca0”可以在Etherscan中找到,它是Lido的wrapped stETH Token。
现在让我们看看每月的交易数量:
import datetime
import matplotlib.pyplot as plt
df["blockTime_"] = df["blockTime"].apply(lambda x: datetime.datetime.fromtimestamp(int(x)))
df['ym'] = df['blockTime_'].dt.strftime("%Y-%m")
df_time = df.groupby('ym', as_index=False).agg({'transactionHash': 'count'}).sort_values('ym')
fig, ax = plt.subplots(figsize=(12,8))
ax.plot(df_time['ym'].iloc[:-1], df_time['transactionHash'].iloc[:-1])
plt.xticks(rotation=45)
plt.xlabel('month')
plt.ylabel('number of transactions')
plt.grid()
plt.show()
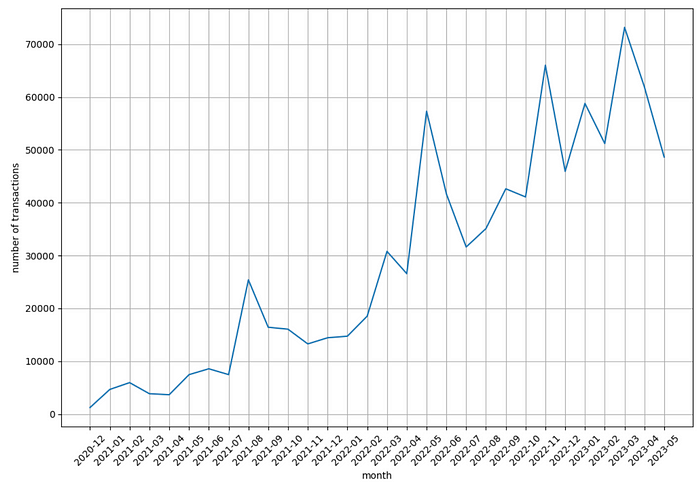
每月的交易数量逐年增长!
你可以继续深入研究其他字段,或者对同一子图上的不同表进行其他查询:
原文链接:How to access real-time smart contract data from Python code (using Lido contract as an example)
DefiPlot翻译整理,转载请标明出处
免责声明:本站资源仅用于学习目的,也不应被视为投资建议,读者在采取任何行动之前应自行研究并对自己的决定承担全部责任。


