AI 交易: 当理论与现实相遇
我将一些深度学习模型投入了比特币市场。但可以说,市场有其他计划

一键发币: x402兼容 | Aptos | X Layer | SUI | SOL | BNB | ETH | BASE | ARB | OP | Polygon | Avalanche
我将一些深度学习模型投入了比特币市场。可以说,市场有其他计划。这是当学术理论撞上市场现实时的真实故事,以及我下一次构建更智能交易机器人的计划。
实验 —— 与市场力量的谦卑相遇
1、人工智能盈利的诱惑
和你们一样,我一直都在寻找AI和机器学习中的下一个大事件,那个可能变成酷东西的想法。不久之前,我听了journalclub.io的一集节目——真的,如果你没有订阅,你错过了一个很棒的AI/ML研究播客——他们讨论了一篇论文 “Deep Learning for Algorithmic Trading: A Systematic Review of Predictive Models and Optimization Strategies.” 它描绘了一个使用深度学习在金融领域中令人信服的愿景,一个想法击中了我:如果我实际上尝试自己构建和测试这些理论呢?

任何涉足数据科学和金融的人都知道这种诱惑:找到那个完美的模型,那个数据和特征的神奇组合,最终破解市场的密码。因此,受到灵感和,说实话,一大剂雄心的驱使,我决定试试看。我的战场?比特币这个极其狂野的世界。
我的计划当时看起来相当稳固。我将使用一些深度学习中的高手——LSTMs和CNN-LSTMs,它们擅长处理序列——试图预测每小时的比特币价格变动。我用了一系列17个技术指标武装它们,甚至使用Optuna进行了一些严重的超参数调优。我真的以为自己正在搭建学术承诺与现实交易之间的桥梁。这篇博客文章?它是这次冒险的记录——好的、坏的和意想不到的丑陋部分。
但正如任何经验丰富的交易者会告诉你的(而我即将痛苦地发现),市场擅长提供一份额外的谦卑,尤其是当你认为你已经掌握了全部的时候。这就是接下来发生的故事,学到的艰难教训,以及我希望能从这里去往何方。
2、打造一个“完美”的交易机器人
我的想法是,为了给这些模型一个公平的机会,我需要坚持一种相当标准、稳健的方法论——你在扎实的量化研究中看到的那种。
- 模型: 我首先选择了**LSTM(长短期记忆)**网络。对于时间序列数据来说,这很合理,因为它擅长记住较长时间内的模式。
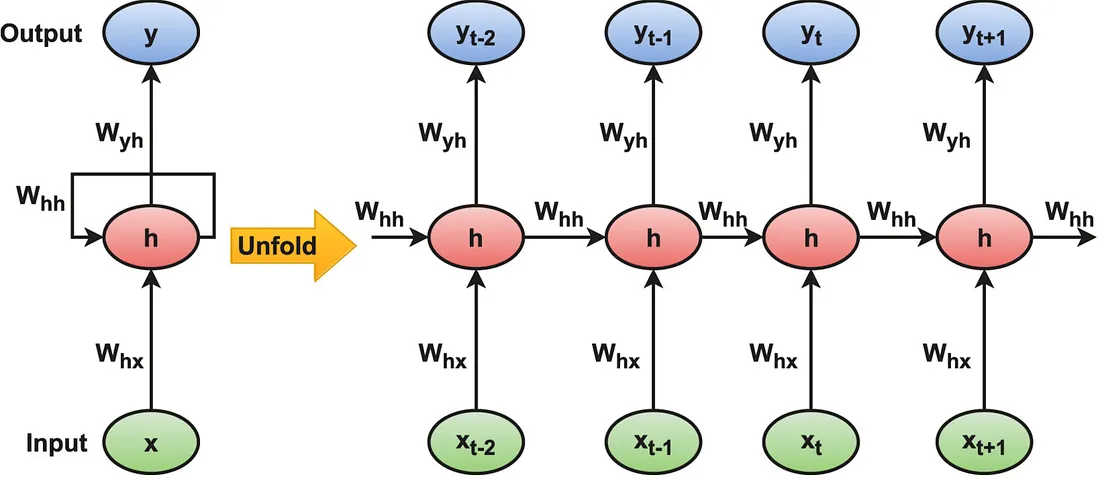
然后,我决定也构建一个 CNN-LSTM 模型。我的想法是,卷积层可以巧妙地从时间段中提取出更高层次的特征,然后再将这些特征输入到 LSTM 中。我希望 CNN 能像一个精密的模式识别器一样,帮助 LSTM 进行识别。
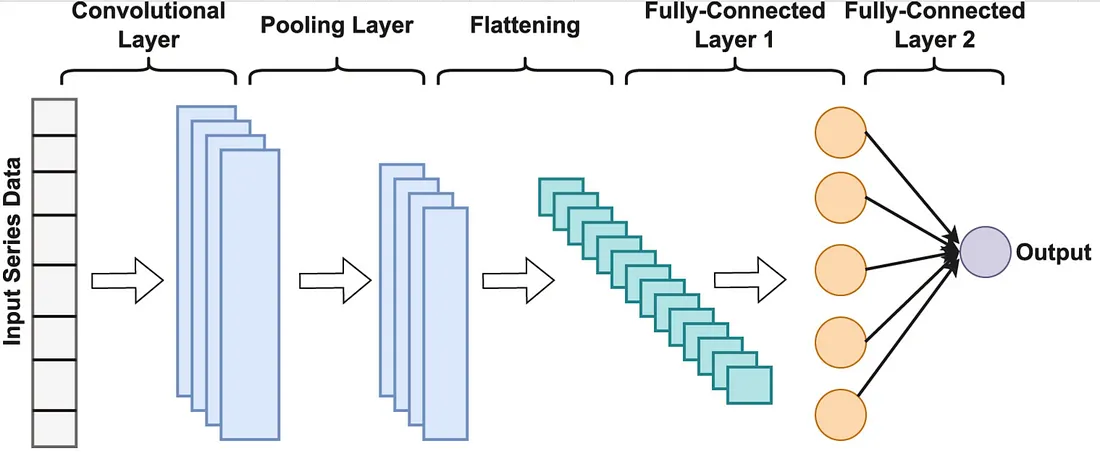
- 数据与特征: 我选择的数据集是两年的每小时BTC/USD数据——一个不错的数据量。从这些数据中,我制作了17个不同的技术指标。我们谈论的是经典:RSI, MACD, Bollinger Bands, 诸如此类。我的目标是为模型提供一个丰富、多维的市场情况视图,关于动量、波动性和趋势。
- 回测引擎: 对于回测,我保持初始策略相当简单。核心思想:如果模型预测的上涨概率超过某个置信水平(比如>0.6),我们就做多。如果它低于较低水平(<0.4),我们就做空。介于两者之间?就保持观望。我还加入了在第25个epoch时提前停止,基于验证损失的情况,以尝试防止明显的过拟合。
现在,对于那些喜欢深入细节的人,信号生成和回测的实际代码有很多内容在后台运行。为了保持这篇文章的可读性和聚焦性,我在这里的代码片段更加概念化。但不用担心,你可以在我GitHub仓库中找到所有完整的、可操作的Python代码、我的Jupyter笔记本和详细的设置。
这里是TradingStrategy类结构的一个鸟瞰图,只是为了给你一个味道:
# TradingStrategy 的概念结构
# 在GitHub上深入了解完整实现
import torch
import numpy as np
class TradingStrategy:
"""
这是我交易策略大脑的一个简化版。
它处理将模型预测转化为交易,然后计算我们是否赚取或损失了虚拟资金。
真实版本有更多的检查、平衡和数据处理。
"""
def __init__(self, model, threshold_buy=0.6, threshold_sell=0.4, transaction_cost=0.001):
self.model = model
self.threshold_buy = threshold_buy # 我最初的“自信时买入”水平
self.threshold_sell = threshold_sell # 我最初的“自信时卖出”水平
self.transaction_cost = transaction_cost # 必须考虑这些讨厌的费用!
self.equity_curve = [1.0] # 从$1的虚拟资本开始
def generate_signals(self, X_test_data_loader):
# 这里是模型发光(或不发光)的地方。
# 它查看测试数据,输出概率,
# 然后我们决定:买入、卖出还是坐等?
# ... 所有细节都在GitHub上...
pass
def backtest(self, signals, actual_market_returns):
# 这里我们模拟我们的策略与实际发生的情况。
# 每个信号转化为一笔交易(或持有模式),
# 扣除交易成本,并查看我们的权益如何变化。
# ... 查看GitHub上的完整模拟逻辑...
pass
def calculate_metrics(self):
# 真相时刻!
# 计算夏普比率、最大回撤、总回报、波动率等。
# 这告诉我们是否中了大奖还是挖了坑。
# ... 数学和细节都在GitHub上...
pass
3、现实检验:两个模型与无情市场的对决
在所有的数据准备、模型训练、细致的调优,最后的回测……结果来了。而且,坦白说,它们是残酷的。
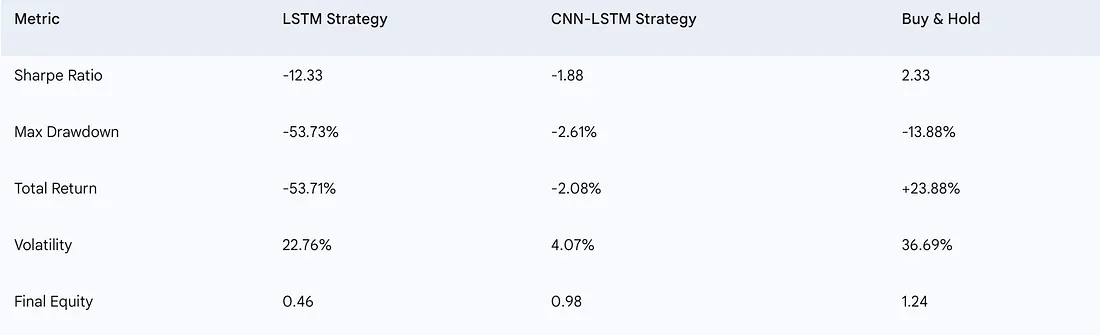
是的,你没看错。这两个本应复杂的模型彻底失败了,无法盈利。LSTM策略不仅糟糕;它是一个壮观的暴跌,烧掉了超过一半的初始资本。CNN-LSTM模型,祝福它的混合心脏,做得好一点——它基本上持平。但“持平”在简单的“买入并持有”策略能带来+23.88%的情况下,是一种冷酷的安慰。这是一颗难以吞咽的药丸,尤其是在投入了这么多时间和精力之后。

看看那张图片中的权益曲线(右上角图表)。虽然“买入并持有”在稳步上升,我的LSTM策略却像一把掉下来的刀,而CNN-LSTM则只是平盘。那么,到底哪里出错了?为什么看似拥有所有正确成分的模型在模拟真实世界测试中表现得如此惨烈?我必须深入挖掘。
4、分析失败:我的美丽理论与丑陋现实的碰撞
老话说得好:魔鬼在于细节。悲惨的绩效指标只是头条新闻;真正的故事是为什么事情变得糟糕隐藏在模型的行为和输出中。这就是我的调查变得非常有趣(当然,也有些痛苦)。
4.1 过拟合与趋势跟随陷阱
我的模型是伟大的历史学家,而不是未来主义者。
很明显,我的模型并没有学会预测未来;它们只是学会了描述最近的过去。下面的特征重要性图表?那是我的罪证。
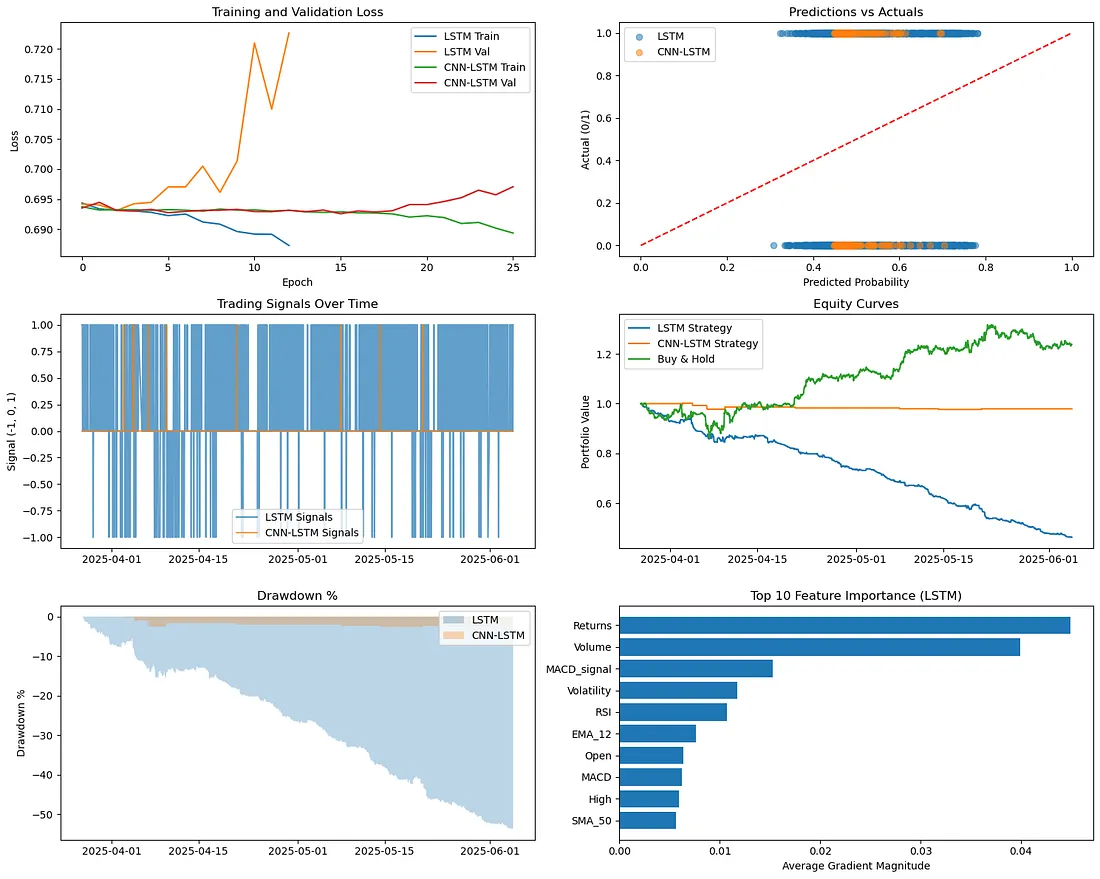
看特征重要性,Returns和Volume对LSTM来说非常重要。翻译:模型基本上学会了非常简单且最终天真的趋势跟随规则。类似,“嘿,如果价格在高成交量下火箭般上升,它可能会继续这样做!”这很好,直到它不再这样。它没有发现任何隐藏的alpha;它只是根据刚刚发生的事情画了一条直线。典型的模型学习“什么”,但对“为什么”一无所知。
4.2 中立预测问题:我的模型是“也许”的大师
如果你看“信号分布”图表(在DL_Algo_2.png图像中),你会看到两个模型大部分时间都在生成……中性信号。换句话说,它们一直在耸肩说,“我不知道!”这是模型陷入市场噪音中,无法找到自信的可交易信号的明显迹象。预测都集中在0.5概率附近。它很少有勇气实际发出交易信号,所以错过了潜在的好机会。就像有一个财务顾问,只会说,“嗯,它可能会上涨,或者它可能会下跌。”不太有用!
4.3 遭遇制度变化:当市场变卦,我的静态模型跌落悬崖
金融市场是活生生的生物;它们不会只停留在一种情绪中。它们在不同的“制度”之间切换——咆哮的牛市、缓慢的熊市、混乱的横向行动、剧烈波动的时期,以及平静的时期。我发现自己,非常沮丧地,发现我的模型就像天气晴朗的水手。它们在市场条件大致类似于训练数据时表现良好(或至少不太差)。但一旦海面变得困难或风向改变?它们完全迷失了。
“滚动夏普比率”图表(也在DL_Algo_2.png中)生动地描绘了这一点。LSTM策略有一个小小的略好表现的短暂波动,然后,砰——市场可能改变了方向,模型的表现突然崩溃,再也没有回头。这是静态模型的致命弱点:它们脆弱。当市场的基本动态发生变化时,它们无法适应。
5、教训:算法交易中残酷(但宝贵)的真实情况
整个实验,尽管肯定没有让我变得富有,但是一次我无法支付的教育。它强调了一些关于将深度学习应用于加密货币交易的严格现实——这些教训现在深深烙在我的脑海中:
- 纸面上的模型“优秀”≠现实中的可交易阿尔法: 这是我最大的、最痛苦的收获。一个模型在训练中看起来非常好——低验证损失、高准确率、所有的好东西——但如果它不能在真实的(或现实的模拟)市场中赚钱,那就毫无意义。学术指标和实际收益之间的差距可能是一个深渊。
- 特征重要性揭示了模型的(有时天真)偏见: 看到我的模型严重依赖近期收益?这是一个明确的迹象,表明了一个简单的趋势跟随偏见。现在,趋势跟随本身并不是坏的,但如果那是你的模型所学到的全部,那么你将会面临巨大的麻烦。我的模型并不如我所希望的那样复杂;它们只是找到了训练数据中最简单的模式,而这并不一定是“聪明”的模式。
- 制度变化一定会摧毁静态模型: 市场是一个变色龙。昨天有效的东西可能是明天的灾难。在特定市场条件下(如稳定的牛市)训练的模型可能会在这些条件改变(你好,突如其来的崩盘或漫长的无聊震荡)时,轰然倒塌。静态模型就像一个单一技巧的马匹试图赢得十项全能比赛——它们根本没有适应性。
这些教训清楚地突显了从一个酷的学术概念到一个在混乱、不可预测的现实世界中真正有效的交易策略之间的广阔而常常危险的差距。这是一次谦卑的经历,但对任何认真在这个领域玩的人来说,也是一个极具启发性的经历。
哦,这真痛。现在,我如何构建一个更聪明的比特币机器人?——下一次迭代
所以,最初的结果是一个打击,毫无疑问。但这里有个问题:它不是死胡同。如果有什么的话,它在我身上点燃了一把火,意外地给了我一个更清晰的路线图,下一步要尝试什么。这就是我从“哦,这失败了”转向“好吧,让我们开始工作”的地方。这就是真正的工程,真正的解决问题的开始!
6、控制野兽:真正理解市场制度
问题: 我的第一代模型完全无视了更广泛的市场天气。牛市、熊市、震荡、平静——对他们来说都是一样的,这是一个巨大的错误。解决方案: 我的第一个想法是,“好吧,我需要一种检测当前市场制度的方法。”其目的是有一个模块可以告诉我我们现在处于牛市、熊市、只是横盘,还是极度波动。
- 我打算如何解决这个问题:
- 旧式统计: 可以从滚动波动率(最近价格跳动多少)、平均真实范围(ATR)或甚至只是查看长期移动平均线交叉开始。
- 稍微更高级的ML: 或者,我可以训练一个单独的、更简单的模型(可能是隐马尔可夫模型,或者甚至随机森林)在历史数据上,我已经手动标记了不同的制度。这个模型的任务只是预测当前状态。
- 为什么这可能是一个游戏改变者:
- 更聪明的策略: 然后我可以有不同的交易模型或参数,根据制度启动。牛市市场趋势跟随,如果是震荡,可能某种均值回归。
- 自适应风险: 我还可以调整我的风险,增加或减少。如果制度检测器尖叫“高波动性!”,则较小的赌注和更宽的止损。
- 新特征的力量: 检测到的制度本身?这可以成为我主要预测模型的一个超级强大的新特征。
(我会在GitHub上分享我的制度检测实验代码!)
7、超越价格与成交量:用高级特征工程挖掘黄金
问题: 那些初始的17个技术指标?它们之所以是标准的,是有原因的,但我怀疑它们并没有捕捉到足够的微妙市场低语。
解决方案: 这让我想到:我需要更深入地挖掘我的特征。我正在研究更复杂的信号,特别是与市场微观结构(交易是如何实际发生的)和长期趋势动态相关的。
# 一些我正在探索的新特征的概念性想法。
# 市场微观结构(如果无法获得完整的订单簿数据):
# df['bid_ask_spread_proxy'] = (df['High'] - df['Low']) / df['Close']
# df['volume_imbalance'] = (df['Volume'] - df['Volume'].rolling(window=20).mean()) / df['Volume'].rolling(window=20).std()
# 感受更大的画面 - 更长期的趋势强度:
# df['trend_strength_200'] = (df['Close'] - df['Close'].rolling(window=200).mean()) / df['Close'].rolling(window=200).std()
- 市场微观结构线索: 像
bid_ask_spread_proxy(流动性的一个粗略衡量)或volume_imbalance(现在是否有更多的买方或卖方压力?)这样的特征可以让我更好地了解非常短期的行动。真正的订单簿数据是梦想,但那是另一个层次的复杂性(和成本)。 - 放大以获取上下文: 像
trend_strength_200(当前价格距离其200小时平均价有多远,调整了波动性?)这样的东西可以帮助模型看到森林而不被树木迷惑,并可能阻止它试图逆流而上。
8、从固定规则到流动逻辑:让我的阈值动态化
问题: 我使用的固定信号阈值(比如,如果概率>0.6就买入,如果<0.4就卖出)?回头看,它们感觉非常随意和僵硬。市场不是固定的,为什么我的决策规则应该是固定的?这感觉像是用一个非常粗糙的工具来完成一件精细的工作。
解决方案: 所以,下一步是让这些阈值更智能,更适应。我希望它们根据模型当前的自信程度,或者根据市场波动性来变化。
# 再次,只是对自适应阈值的想法的草率想法。
# 示例:让阈值依赖于最近的模型信心
# recent_predictions = get_the_model_outputs_from_the_last_few_hours()
# long_threshold = np.percentile(recent_predictions, 75) # 只有在最近的25%的信心范围内才行动
# short_threshold = np.percentile(recent_predictions, 25) # 或者在底部25%进行做空
- 信心是关键: 这样,模型只有在它的信念比它最近的表现更高时才会行动。如果它通常不确定,它需要更强的信号。
- 波动性作为指南: 另一个角度是让中性区域在市场动荡时更宽。基本上,在混乱的环境中要求模型给出更清晰的信号。
9、资本保护是王道:认真对待稳健的风险管理
问题: 我的第一个回测者对风险非常天真。LSTM的灾难性暴跌直接源于此。这是一个痛苦但绝对重要的教训:没有保护的预测只是快速失去资金的方式。
解决方案: 这其实是一个不言而喻的解决方案。我绝对必须建立明确的、稳健的风险管理规则。我指的是止损和更聪明的仓位大小。
# 一些关于风险管理的初步想法。
# 自适应仓位大小 - 不把全部押在每一次交易上:
# current_market_volatility = figure_out_how_crazy_the_market_is_right_now()
# # 根据波动性反向调整下注大小,有一些合理的上限
# position_size_percentage = max(0.01, min(0.1, 0.05 / (current_market_volatility + 1e-6)))
# 止损 - 知道何时放弃:
# stop_loss_trigger_percentage = 0.02 # 例如,入场价的2%止损。不可协商。
- 止损:我的安全网。 这是版本2.0中不可协商的。硬性止损限制了我在任何单笔交易中的损失。再也不会看着我的虚拟权益蒸发!
- 更聪明的下注(仓位大小): 不是在每次交易中都冒同样的风险,我需要调整我的仓位大小。也许在波动性高的时候冒更少的风险,或者在模型不是很自信的时候,而在条件有利的时候冒一点风险。我最初的固定仓位大小方法只是在找麻烦。
10、倾听人群(和新闻):融入情感分析
问题: 价格图表和技术指标?它们只告诉你部分发生了什么。特别是在加密货币世界中,市场情绪——集体情绪、炒作、恐惧、不确定性、怀疑(FUD)——可以是一个非常强大且经常是领先的价格驱动因素。我的模型对此是聋的。解决方案: 我将尝试整合来自各种来源的情感数据。这是很重要的一点,说实话,我对进入这个领域感到非常兴奋。
10.1 我打算从哪里获取这些情感数据
我一直在研究几个不同的途径:
- Google Trends API (pytrends)
- StockTwits API / 其他社交媒体(如Twitter、Reddit)
10.2 令人头疼的部分:新闻冲击,但市场什么时候感受到它?
我已预料到的一件事是市场并不总是即时或可预测地对新闻做出反应:
- 重大新闻(主要交易所上市、大黑客、监管炸弹): 高频交易算法和超级关注者可能在1–5分钟内做出反应。其余人?它可能需要更长时间才能传播。
- 预定数据(经济报告等——对加密货币来说不太直接但仍有影响): 通常在15–30分钟内市场开始消化,影响可能持续数小时。
- 分析师报告/意见领袖喊话(如果足够大): 可能在2–24小时内随着消息传播。
- 社交媒体谣言/FUD/FOMO: 这是不可预测的。可能在大意见领袖发推文时立即发生,或者谣言病毒式传播。或者,它可能只是消失,毫无意义。
10.3 我预期的情感处理头痛
处理原始文本很麻烦。我知道我将遇到挑战,试图准确判断情感:
- 讽刺和反讽: “哦,好的工作,SEC…”可能是否定的,即使用了正面词。
- 上下文是关键: “比特币暴跌至6万美元。”不好,对吧?但如果它上个月是3万美元,而这是未来牛市高峰的头条呢?或者有人随意地说,“比特币暴跌向上至6万美元!”(意思是它飙升)。
- 谁说的?(来源可信度和意图): 一条来自知名加密货币分析师的推文?可能比一个匿名账户更有意义。来源是想告知、操纵情绪,还是只是发泄?
- 术语(金融术语和缩写): 我的模型需要理解“HODL”、“FUD”、“钻石手”、“ATH”、“DeFi”、“NFTs”和所有其他加密货币俚语。
- 表情符号和模糊性: “BTC到月亮 🚀🌕”——显然积极。 “BTC会到月亮吗? 🤔”——更加不确定。
10.4 我处理情感的计划
根据我读到的内容和一些初步的头脑风暴,这是我思考的方法:
- 不要把所有鸡蛋放在一个篮子里(多源方法): 我不会只依赖一个情感来源。我会尝试结合2-3种不同类型的信息源——可能是一般新闻、一些专注于加密货币的社交媒体,如果我能得到的话,还有链上情感。
- 情感随时间变化(滞后特征): 不仅仅是现在的感情。它是如何变化的?所以我将尝试创建以下特征:
Sentiment_Score_NowSentiment_Score_1hr_AgoSentiment_Score_6hr_AgoSentiment_Change_Rate_Last_Hour(它是在变得更积极还是更消极?)Sentiment_Volatility(情感稳定还是到处都是?)- 并非所有来源都同等重要(来源加权和过滤):
- 我会尝试给可信新闻来源(如路透社或彭博社,如果我能访问的话)更多权重,而不是一些随机博客。
- 在社交媒体上,我会尝试过滤掉一些来自粉丝较少或参与度低的账户的噪音。
- 最近的新闻通常比旧新闻更重要,但我要考虑不同类型信息变得过时的速度。
- 合适的工具:(NLP技术):
- 基于词典的方法(如VADER或SentiWordNet):这些对于一般情感很有用,通常更容易实现。但它们可能在处理所有特定金融术语时遇到困难。
- 基于机器学习的分类器: 为了更好的准确性,特别是对于特定领域的语言,我可能需要训练自定义的情感模型(使用诸如朴素贝叶斯、SVM或甚至更先进的BERT模型)。这肯定是更繁琐的工作,因为它需要良好的标注数据,但可能是真正深入理解所必需的。
10.5 从便宜处开始:我为这个研究阶段的成本效益工具包:
对于像我这样作为研究项目进行的个人(读作:预算有限),以下是一些我计划开始使用的免费或免费试用工具:
- NewsAPI.org(免费版): 这将使我能够访问一般新闻文章。我需要自己对标题或内容进行情感分析。
- Reddit PRAW(Python Reddit API包装器 - 免费): 我可以使用它来抓取相关子版块(如r/CryptoCurrency、r/Bitcoin)。这是零售情绪的海量来源,但需要过滤掉很多噪音。
- yfinance(免费): 这个库可以提取与股票代码相关的新闻头条(加密货币的覆盖可能仅限于大名,但仍有用)。
- Alpha Vantage(免费版用于新闻和情感): 他们提供了一些预处理的情感分数,这可能是开始的绝佳方式,而无需从头开始构建自己的NLP管道。
- Google Trends(通过
pytrends- 免费): 如我所说,它非常适合跟踪搜索兴趣。
我希望通过系统地处理这些改进,我可以将那些初始表现不佳的模型塑造成更复杂、适应性强且(希望)真正盈利的东西。当然,我会在我的GitHub上记录所有这些新功能的代码和实验:[链接到你的GitHub仓库]。
11、从黑箱挫败到玻璃箱探索 —— 旅程仍在继续
那个诱人的“魔法黑箱”梦想——一个复杂的算法,安静地从市场上打印钱——正如我的小实验所残酷地证明的那样,主要是幻想,当它撞上现实世界的复杂性时。我第一次尝试使用深度学习进行比特币交易是一个非常鲜明、非常真实的提醒,即仅仅因为一个模型在学术论文中看起来很好或具有低验证损失,并不意味着它会在真实(或现实的模拟)市场中赚钱。尤其是在加密货币领域,这完全是另一个级别的疯狂。在受控、无菌实验室环境中运行得很好的东西,往往在面对市场的混乱、不可预测的美时崩溃。
那些痛苦的回撤和所有错过的机会?它们并不是失败,至少不是真正的失败。它们是非常有价值的数据点。它们将严厉的聚光灯投向了过度拟合的陷阱、在非静态市场中使用静态模型的纯粹天真,以及绝对、不可协商的需要多层次方法,远远超出仅仅预测下一个价格点。构建一个模型是一回事;构建一个持续工作并保持工作的模型是另一回事,随着世界的变化而变化。
前进的道路,我在第二部分中概述的,是试图构建一个更智能的系统。我想有一个能够真正感受不同市场制度的系统,能够引入更丰富的数据如情感,能够在飞行中适应其决策,并且至关重要的是,知道如何保护其资本。这是从一个简单的预测黑箱演变为一个更全面、适应性强和可理解的交易策略的过程。这段旅程,从一个酷的学术理论到(希望)一个持续盈利的市场现实,是关于迭代:学习、适应和不断优化。而这段旅程,对我来说,肯定还远未结束。我实际上很期待分享我的进展,当我着手这些下一步时,所以希望你能继续关注!
原文链接:Deep Learning for Crypto Trading: When Academic Theory Meets Market Reality
DefiPlot翻译整理,转载请标明出处
免责声明:本站资源仅用于学习目的,也不应被视为投资建议,读者在采取任何行动之前应自行研究并对自己的决定承担全部责任。